
SOFTWARE:
DEFINICION: El software es el ingrediente principal que permite a una computadora realizar una tarea determinada, el cual consiste en instrucciones electrónicas por medio de las cuales el computador va a procesar los datos que recibe para transformarlos en información.
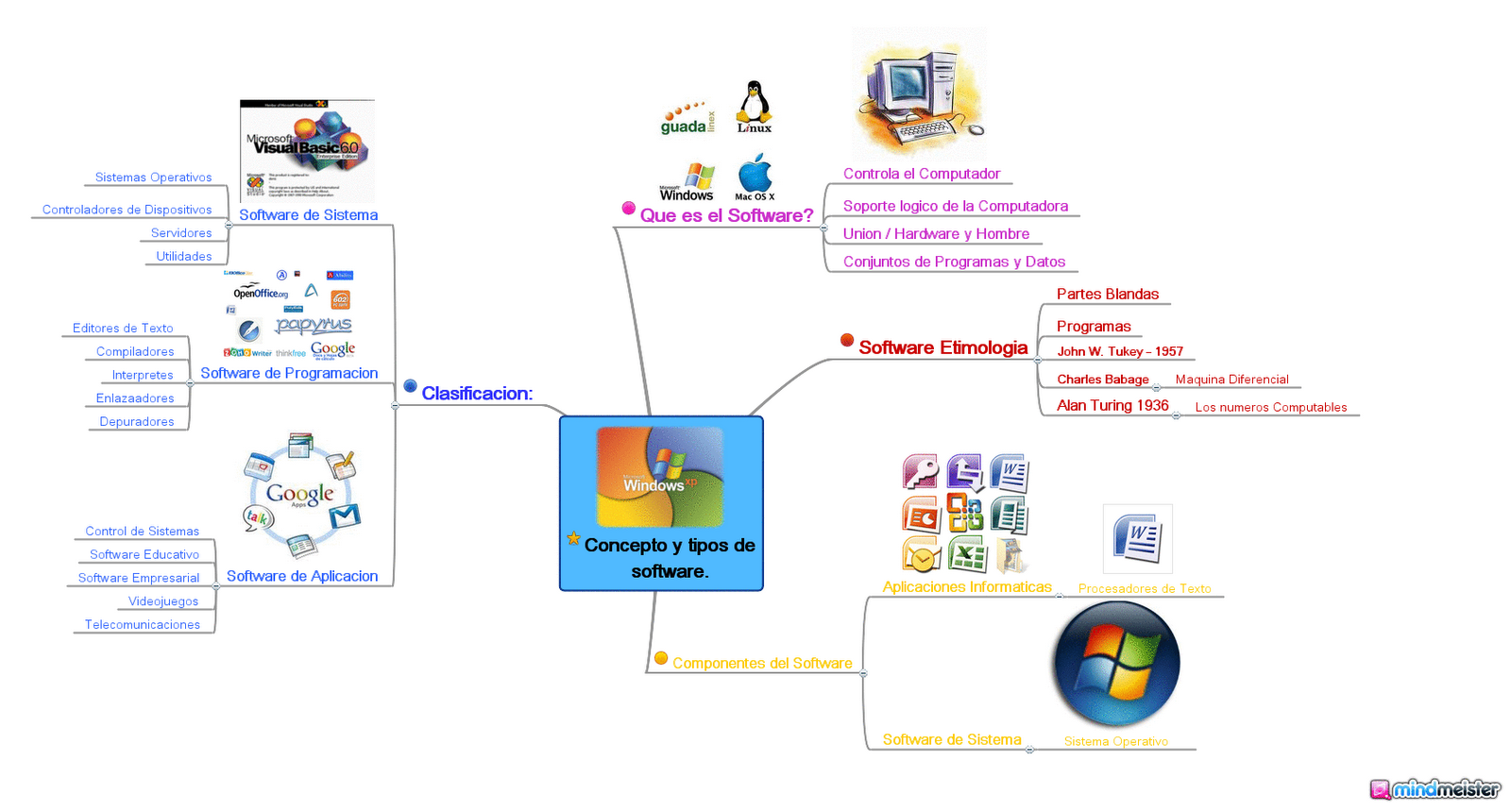
TIPOS: Aunque la serie de programas disponibles es basta y variada, la mayor parte del software cae en dos categorías principales:
a) software de aplicación
b) software de sistemas o sistemas operativos
SISTEMAS OPERATIVOS :
DEFINICION: el sistema operativo es aquel que proporciona programas los cuales tienen como función principal ayudar en el funcionamiento y desarrollo de las labores del computador asi como tambien le dice a la computadora como usar sus propios componentes.
- FUNCIONES:
- facilitar el uso del computador ta que el software proporciona una interfaz que es mas favorable al usuario donde el recive su información principal.
- el sistema operativo administra los recursos del computador en un intento por cumplir con los objetivos globales del sistema siendo el principal la eficiencia en su trabajo.
- proporciona programas con un conjunto de servicios que pueden ayudar en el funcionamiento de muchas tares comunes.
- comparte los recursos de la maquina entre varios procesos al mismo tiempo.
En conclusión se podria decir que la función central de un sistema operativo es administrar y organizar los recursos con que dispone una computadora para la mejor utilización de la misma, en beneficio del mayor numero posible de usuarios.
TIPOS:
A) SISTEMAS OPERATIVOS DE LINEAS DE COMANDO:
Son software estrictamente basado en texto y operado por comandos, a lo largo de los años ochenta , el sistema operativo mas difundido en las computadoras fue el MS-DOS .
B) SISTEMA OPERATIVO DE AMBIENTE GRAFICO: Estos son software que permiten la integración de texto con imágenes de alta resolución.
CLASIFICACION:
La clasificación de los sistemas operativos se basan en la clase de interfaz del usuario que ellos proporcionan y gran parte de su terminología surge de la forma en que este se le presenta al usuario.
Una forma de clasificacion de los sistemas operativos puede ser de la siguiente forma:
a) De acuerdo al número de usuarios que el sistema pueda atender a la vez, se clasifican en:
–Sistema de un solo trabajo: Ejecuta solo un trabajo de un usuario a la vez, lo encontramos a menudo en microcomputadores y computadores personales ya que es el tipo de sistemas operativos mas antiguos; estos son empleados normalmente en los computadores estándar, ya que a causa del tamaño limitado de su memoria y a la falta de canales y de otros recursos, seria difícil soportar mas de un usuario en dicha maquina.
-sistema de multiprogramación: Permite ejecutar varios trabajos de usuarios al mismo tiempo, su sistema operativo se encarga de intercambiar el cpu entre los distintos trabajos de usuario proporcionando un ambiente adecuado de modo que los trabajos no se interfieran. Su propósito básico es mejorar el rendimiento permitiendo así que los recursos de sistema se compartan entre varios trabajos
–sistemas de multiprocesamiento: Es semejante al anterior pero en este hay más de un cpu disponible.
b) Por el tipo de acceso que proporciona al usuario:
-sistemas de procesamiento por lotes: Se define como una secuencia de proposiciones de control almacenadas en forma legible para la maquina. El sistema operativo puede leer y ejecutar una serie de dichos trabajos sin otra intervención humana que las de ciertas funciones como el montaje de cintas y discos.
-Sistemas de tiempo compartido: Es aquel que proporciona acceso interactivo o conversacional a varios usuarios. Su sistema operativo ejecuta mandatos conforme los recibe, intentando dar a cada usuario un tiempo de respuesta razonablemente corto para cada mandato.
-sistema de tiempo real: Está planeado para responder con rapidez a señales externas como las generadas por sensores de datos , y se emplean por ejemplo, en computadores vigilantes asi como también en aquellos que controlan procesos críticos, en cuanto al tiempo, como la operación de un reactor nuclear o el vuelo de una nave espacial.
Los más conocidos son:
Los sistemas operativos empleados normalmente son UNIX, Macintosh OS, MS-DOS, OS/2, Windows 95 y Windows NT.
-MS-DOS.
El significado de estas letras es el de Microsoft Disk Operating System. Microsoft es el nombre de la compañía que diseño este sistema operativo, e IBM la compañía que lo hizo estándar al adoptarlo en sus microordenadores.
Este sistema operativo emplea discos flexibles con una organización determinada. Los discos se pueden grabar por una o por dos caras y la información se organiza en 40 pistas de 8 ó 9 sectores de un tamaño de 512 caracteres, reservándose el sistema para la propia información del disco, que puede ser disco removible o disco duro, teniendo en el segundo más capacidad pero similar estructura.
Los nombres de los ficheros en MS-DOS, para los que se emplean tanto letras como números, se componen de dos partes: el nombre del fichero y la extensión, estando ambos datos separados por un punto. Las diferentes unidades de disco son identificadas por el MS-DOS a través de una letra seguida de dos puntos. Los tipos de extensión más habituales son como aparecería la memoria cargada con ellos; es decir, que pueden cargar directamente a memoria sin el auxilio del sistema operativo.
Los de extensión .EXE precisan que el cargador del DOS los coloque en memoria, lo que significa que el sistema operativo debe estar en memoria. Los del tipo .BAT son los compuestos de comandos que se ejecutan secuencialmente.
El sistema operativo tiene varios componentes que son:
– Rutinas de control, que funcionan con el programa IBM.DOS, y se encargan de las operaciones de entrada / salida.
– Procesador de comandos, también llamado COMMAND.COM, que procesa los dos tipos de comandos de que dispone el DOS; es decir, los residentes en memoria o internos, y los no residentes o externos, que residen en el disco del sistema operativo.
– Rutinas de servicios accesibles desde el programa control.
También existe la posibilidad de subdividir el disco en subdirectorios que permiten un empleo más ágil de toda la información.
MS-DOS esta lejos de ser el sistema operativo ideal, ya que, de momento, se trata de un sistema monotarea, pero aunque esto se resolviera, seguiría presentando problemas de diseño que provocan que el comportamiento de la máquina sea poco fiable. A pesar de estas desventajas y de que existen otros sistemas operativos en el mundo de la microinformática, hay que tener siempre presente la enorme cantidad de software que se ha desarrollado para DOS y que conviene aprovechar en lo posible.
OS/2.
Desarrollado inicialmente por Microsoft Corporation e International Business Machines (IBM), después de que Intel introdujera al mercado su procesador 80286. Pero la sociedad no duro mucho ya que IBM veía a Windows como una amenaza para el SO/2.
Pero IBM continúo desarrollando este sistema operativo. El OS/2 al principio fue muy parecido al MS-DOS, tiene una línea de comando, pero la diferencia que existe con el DOS es el intérprete de comandos, el cual es un programa separado del kernel del sistema operativo y aparece únicamente cuando se hace clic en uno de los iconos “OS/2 prompt” dentro del Workplace Shell. Otra diferencia es que este sí en un sistema operativo multitarea.
En el OS/2 muchos de los comandos son idénticos a los de su contra parte pero tiene más comandos debido a que es más grande, completo y moderno.
El ambiente gráfico es el Workplace Shell (WS), es el equivalente a un administrador del área de trabajo para el WS.
Macintosh OS.
El sistema operativo constituye la interfaz entre las aplicaciones y el hardware del Macintosh. El administrador de memoria obtiene y libera memoria en forma automática para las aplicaciones y el sistema operativo. Esta memoria se encuentra normalmente en un área llamada cúmulo. El código de procedimientos de una aplicación también ocupa espacio en el cúmulo. Ahora se presenta una lista de los principales componentes del sistema operativo.
° El cargador de segmentos carga los programas por ejecutar. Una aplicación se puede cargar completa o bien puede dividirse en segundos individuales que se pueden cargar de manera dinámica conforme se necesiten.
° El administrador de eventos del sistema operativo informa de la ocurrencia de diversos eventos de bajo nivel, como la presión de un botón del mouse o el tecleo. En condiciones normales, el administrador de eventos de la caja de herramientas transfiere estos eventos a las aplicaciones.
° El administrador de archivos se encarga de la entrada / salida de archivos; el administrador de dispositivos se encarga de la entrada / salida de dispositivos.
° Los manejadores de dispositivos son programas con los cuales los diversos tipos de dispositivos pueden presentar interfaces uniformes de entrada / salida a las aplicaciones. Tres manejadores de dispositivo están integrados al sistema operativo en ROM: el manejador de disco se encarga del acceso a la información en discos, el manejador de sonido controla los generadores de sonido, y el manejador en serie envía y recibe datos a través de los puertos seriales (estableciendo así la comunicación con dispositivos periféricos en serie como impresoras y módems).
° Con el manejador de impresoras las aplicaciones pueden imprimir datos en diversas impresoras.
° Con el administrador de AppleTalk las aplicaciones pueden transmitir y recibir información en una red de comunicaciones AppleTalk.
° El Administrador de retrazado vertical programa las actividades por realizar durante las interrupciones de retrazado vertical que ocurren 60 veces cada segundo cuando se refresca la pantalla de vídeo.
° El manejador de errores del sistema toma el control cuando ocurre un error fatal del sistema y exhibe un cuadro de error apropiado.
° Los programas de utilidad general del sistema operativo ofrecen diversas funciones útiles como la obtención de la fecha y la hora, la comparación de cadenas de caracteres y muchas más.
° El paquete de iniciación es llamado por el paquete de archivos estándar para iniciar y nombrar discos; se aplica con más frecuencia cuando el usuario inserta un disco al que no se le han asignado valores iniciales.
° El paquete de aritmética de punto flotante ofrece aritmética de doble precisión. El paquete de funciones trascendentales ofrece un generador de números aleatorios, así como funciones trigonométricas, logarítmicas, exponenciales y financieras. Los compiladores de Macintosh generan en forma automática llamadas a estos paquetes para realizar manipulaciones numéricas.
UNIX.
Es un sistema operativo multiusuario que incorpora multitarea. Fue desarrollado originalmente por Ken Thompson y Dennis Ritchie en los laboratorios de AT&T Bell en 1969 para su uso en minicomputadoras. El sistema operativo UNIX tiene diversas variantes y se considera potente, más transportable e independiente de equipos concretos que otros sistemas operativos porque esta escrito en lenguaje C. El UNIX esta disponible en varias formas, entre las que se cuenta AIX, una versión de UNIX adaptada por IBM (para su uso en estaciones de trabajo basadas en RISC), A/ux (versión gráfica para equipos Apple Macintosh) y Mach (un sistema operativo reescrito, pero esencialmente compatible con UNIX, para las computadoras NeXT).
El UNIX y sus clones permiten múltiples tareas y múltiples usuarios. Su sistema de archivos proporciona un método sencillo de organizar archivos y permite la protección de archivos. Sin embargo, las instrucciones del UNIX no son intuitivas.
Este sistema ofrece una serie de utilidades muy interesantes, como las siguientes:
° Inclusión de compiladores e interpretes de lenguaje.
° Existencia de programas de interfase con el usuario, como ventanas, menús, etc.
° Muchas facilidades a la hora de organización de ficheros.
° Inclusión de lenguajes de interrogación.
° Facilidades gráficas.
° Programas de edición de textos.
Microsoft Windows NT.
Microsoft no solo se ha dedicado a escribir software para PCs de escritorio sino también para poderosas estaciones de trabajo y servidores de red y bases de datos.
El sistema operativo Windows NT de Microsoft, lanzado al mercado el 24 de Mayo de 1993, es un SO para redes que brinda poder, velocidad y nuevas características; además de las características tradicionales. Es un SO de 32 bits, y que puede trabajar en procesadores 386, 486 y Pentium.
Además de ser multitarea, multilectura y multiprocesador ofrece una interfaz gráfica. Y trae todo el software necesario para trabajar en redes, permitiendo ser un cliente de la red o un servidor.
Microsoft Windows 95.
Es un entorno multitarea dotado de una interfaz gráfica de usuario, que a diferencia de las versiones anteriores, Windows 95 no necesita del MS-DOS para ser ejecutado, ya que es un sistema operativo.
Este SO esta basado en menús desplegables, ventanas en pantalla y un dispositivo señalador llamado mouse. Una de las características principales de Windows 95 es que los nombres de los archivos no están restringidos a ocho caracteres y tres de la extensión, pueden tener hasta 256 caracteres para tener una descripción completa del contenido del archivo. Además posee Plug and Play, una tecnología conjuntamente desarrollada por los fabricantes de PCs, con la cual un usuario puede fácilmente instalar o conectar dispositivos permitiendo al sistema automáticamente alojar los recursos del hardware sin la intervención de usuario.
COMPONENTES:
Componentes: El sistema operativo es generalmente diseñado por el fabricante y por ello no es posible definir uno estándar; aunque hay un conjunto de funciones básicas o componentes que todo sistema debe considerar, y son:
-
- Controlar las operaciones de entrada y salida.
- Cargar, inicializar y supervisar la ejecución de los trabajos.
- Detectar errores.
- Controlar las interrupciones causadas por los errores.
- Asignar memoria a cada tarea.
- Manejar el multiproceso, la multiprogramación, memoria virtual, etc…
Gracias por Visitar mi Blog te invito a seguir explorando mis opciones en la pagina de las que te pueden interesar:
https://blogdelisc2015.wordpress.com/2017/12/28/coleccion-de-peliculas-para-celular-mp4/
SOFTWARE DE APLICACIÓN
Son programas que ayudan a loa usuarios a realizar cualquier tipo de tarea imaginable, desde el procesamiento de palabras hasta una infinidad de tareas especificas.
PROCESADORES DE PALABRAS:
El software de procesamiento de palabras consiste esta diseñado para crear documentos que consisten principalmente en texto.
HOJA DE CÁLCULO:
Se le llama también hoja electrónica de cálculo a unos sistemas que permiten el manejo virtualizado de columnas de números, y que vuelven fácil la tarea de hacerles modificaciones y operaciones diversas, que van desde alteraciones sencillas en sus valores hasta el calculo de cifras adicionales que dependen de relaciones matemáticas entre otras columnas y renglones especificados por el usuario. Su utilidad es muy amplia e importante sobre todo en aplicaciones de contabilidad, finanzas y presupuestos.
GRAFICADORES:
Las aplicaciones de auditoria multimedia le permiten organizar textos, sonidos, videos, y otros elementos gráficos en un sistema operativo secuenciado.
* Clasificación de los graficadotes:
-Software de pintura: permite pintar píxeles en la pantalla usando un dispositivo apuntador , pudiendo ser este un ratón, palanca de mando , bola rastreadora o pluma, traduciendo sus movimientos en patrones y líneas en la pantalla.
-Software de procesamiento digital de imágenes: Permite al usuario manipular fotografías y otras imágenes de alta definición con herramientas similares a las que proporciona los programas de pintura.
-Software de dibujo: almacena una imagen no como colección de puntos sino como una colección de líneas y formas. El programa de dibujo almacena las formas como formas y el texto como texto. Como las imágenes son colecciones de líneas, formas y objetos, esta estrategia se conoce como graficación orientada a objetos.
-Software de gráficos para presentaciones: Esta diseñado para automatizar la creación de ayudas visuales para conferencias, sesiones de capacitación, demostraciones de ventas etc… De acuerdo con una definición amplia este tiene desde programas de diagramación, hojas de cálculo hasta software de animación y edición de video, y muchos programas son capaces de manejar todas estas diversas tareas.
-Software de modelado tridimensional: Los diseñadores graficos pueden crear objetos tridimensionales con herramientas similares a las del software de de dibujo convencional. Un artista puede dibujar una escena tridimensional sobre una página de dos dimensiones. Este sistema posee gran flexibilidad ya que permite observar el trabajo ampliamente y con una gran perspectiva.
MANEJADOR DE BASE DE DATOS:
Una de las razones principales para tener sistemas de gestión de base de datos es tener el control central de los datos y de los programas que acceden a esos datos. La persona que tiene dicho control central sobre el sistema se llama manejador de base de datos, además de que organiza todos los datos ya archivados y permite su búsqueda de forma más eficaz y eficiente, gracias a sus distintas maneras y técnicas de búsqueda.
Existen programas denominados sistemas gestores de bases de datos, abreviado SGBD, que permiten almacenar y posteriormente acceder a los datos de forma rápida y estructurada. Las propiedades de estos SGBD, así como su utilización y administración, se estudian dentro del ámbito de la informática.
Las aplicaciones más usuales son para la gestión de empresas e instituciones públicas. También son ampliamente utilizadas en entornos científicos con el objeto de almacenar la información experimental.
Aunque las bases de datos pueden contener muchos tipos de datos, algunos de ellos se encuentran protegidos por las leyes de varios países. Por ejemplo, en España los datos personales se encuentran protegidos por la Ley Orgánica de Protección de Datos de Carácter Personal (LOPD).
Bases de datos bibliográficas
Solo contienen un subrogante (representante) de la fuente primaria, que permite localizarla. Un registro típico de una base de datos bibliográfica contiene información sobre el autor, fecha de publicación, editorial, título, edición, de una determinada publicación, etc. Puede contener un resumen o extracto de la publicación original, pero nunca el texto completo, porque si no, estaríamos en presencia de una base de datos a texto completo (o de fuentes primarias —ver más abajo). Como su nombre lo indica, el contenido son cifras o números. Por ejemplo, una colección de resultados de análisis de laboratorio, entre otras.
Bases de datos dinámicas
Éstas son bases de datos donde la información almacenada se modifica con el tiempo, permitiendo operaciones como actualización, borrado y adición de datos, además de las operaciones fundamentales de consulta. Un ejemplo de esto puede ser la base de datos utilizada en un sistema de información de un supermercado, una farmacia, un videoclub o una empresa.
Bases de datos estáticas
Éstas son bases de datos de sólo lectura, utilizadas primordialmente para almacenar datos históricos que posteriormente se pueden utilizar para estudiar el comportamiento de un conjunto de datos a través del tiempo, realizar proyecciones y tomar decisiones.
Bases de datos deductivas
Un sistema de base de datos deductiva, es un sistema de base de datos pero con la diferencia de que permite hacer deducciones a través de inferencias. Se basa principalmente en reglas y hechos que son almacenados en la base de datos. Las bases de datos deductivas son también llamadas bases de datos lógicas, a raíz de que se basa en lógica matemática.
Bases de datos documentales
Permiten la indexación a texto completo, y en líneas generales realizar búsquedas más potentes. Tesaurus es un sistema de índices optimizado para este tipo de bases de datos.
Bases de datos jerárquicas
Éstas son bases de datos que, como su nombre indica, almacenan su información en una estructura jerárquica. En este modelo los datos se organizan en una forma similar a un árbol (visto al revés), en donde un nodo padre de información puede tener varios hijos. El nodo que no tiene padres es llamado raíz, y a los nodos que no tienen hijos se los conoce como hojas.
Las bases de datos jerárquicas son especialmente útiles en el caso de aplicaciones que manejan un gran volumen de información y datos muy compartidos permitiendo crear estructuras estables y de gran rendimiento.
Una de las principales limitaciones de este modelo es su incapacidad de representar eficientemente la redundancia de datos.
Bases de datos multidimensionales
Son bases de datos ideadas para desarrollar aplicaciones muy concretas, como creación de Cubos OLAP. Básicamente no se diferencian demasiado de las bases de datos relacionales (una tabla en una base de datos relacional podría serlo también en una base de datos multidimensional), la diferencia está más bien a nivel conceptual; en las bases de datos multidimensionales los campos o atributos de una tabla pueden ser de dos tipos, o bien representan dimensiones de la tabla, o bien representan métricas que se desean estudiar.
Bases de datos orientadas a objetos
Este modelo, bastante reciente, y propio de los modelos informáticos orientados a objetos, trata de almacenar en la base de datos losobjetos completos (estado y comportamiento).
Una base de datos orientada a objetos es una base de datos que incorpora todos los conceptos importantes del paradigma de objetos:
- Encapsulación – Propiedad que permite ocultar la información al resto de los objetos, impidiendo así accesos incorrectos o conflictos.
- Herencia – Propiedad a través de la cual los objetos heredan comportamiento dentro de una jerarquía de clases.
- Polimorfismo – Propiedad de una operación mediante la cual puede ser aplicada a distintos tipos de objetos.
En bases de datos orientadas a objetos, los usuarios pueden definir operaciones sobre los datos como parte de la definición de la base de datos. Una operación (llamada función) se especifica en dos partes. La interfaz (o signatura) de una operación incluye el nombre de la operación y los tipos de datos de sus argumentos (o parámetros). La implementación (o método) de la operación se especifica separadamente y puede modificarse sin afectar la interfaz. Los programas de aplicación de los usuarios pueden operar sobre los datos invocando a dichas operaciones a través de sus nombres y argumentos, sea cual sea la forma en la que se han implementado. Esto podría denominarse independencia entre programas y operaciones.
SQL:2003, es el estándar de SQL92 ampliado, soporta los conceptos orientados a objetos y mantiene la compatibilidad con SQL92.
Bases de datos o «bibliotecas» de información química o biológica.
- Las que almacenan secuencias de nucleótidos o proteínas.
- Las bases de datos de rutas metabólicas.
- Bases de datos de estructura, comprende los registros de datos experimentales sobre estructuras 3D de biomoléculas-
- Bases de datos clínicas.
- Bases de datos bibliográficas (biológicas, químicas, médicas y de otros campos): PubChem, Medline, EBSCOhost.
Base de datos de red
Éste es un modelo ligeramente distinto del jerárquico; su diferencia fundamental es la modificación del concepto de nodo: se permite que un mismo nodo tenga varios padres (posibilidad no permitida en el modelo jerárquico).
Fue una gran mejora con respecto al modelo jerárquico, ya que ofrecía una solución eficiente al problema de redundancia de datos; pero, aun así, la dificultad que significa administrar la información en una base de datos de red ha significado que sea un modelo utilizado en su mayoría por programadores más que por usuarios finales.
Bases de datos relacionales
Éste es el modelo utilizado en la actualidad para modelar problemas reales y administrar datos dinámicamente. Tras ser postulados sus fundamentos en 1970 por Edgar Frank Codd, de los laboratorios IBM en San José (California), no tardó en consolidarse como un nuevo paradigma en los modelos de base de datos. Su idea fundamental es el uso de «relaciones». Estas relaciones podrían considerarse en forma lógica como conjuntos de datos llamados «tuplas». Pese a que ésta es la teoría de las bases de datos relacionales creadas por Codd, la mayoría de las veces se conceptualiza de una manera más fácil de imaginar. Esto es pensando en cada relación como si fuese una tabla que está compuesta por registros (las filas de una tabla), que representarían las tuplas, y campos (las columnas de una tabla).
En este modelo, el lugar y la forma en que se almacenen los datos no tienen relevancia (a diferencia de otros modelos como el jerárquico y el de red). Esto tiene la considerable ventaja de que es más fácil de entender y de utilizar para un usuario esporádico de la base de datos. La información puede ser recuperada o almacenada mediante «consultas» que ofrecen una amplia flexibilidad y poder para administrar la información.
El lenguaje más habitual para construir las consultas a bases de datos relacionales es SQL, Structured Query Language o Lenguaje Estructurado de Consultas, un estándar implementado por los principales motores o sistemas de gestión de bases de datos relacionales.
Durante su diseño, una base de datos relacional pasa por un proceso al que se le conoce como normalización de una base de datos.
Durante los años 80 la aparición de dBASE produjo una revolución en los lenguajes de programación y sistemas de administración de datos. Aunque nunca debe olvidarse que dBase no utilizaba SQL como lenguaje base para su gestión.
Bases de datos Texto completo
Almacenan las fuentes primarias, como por ejemplo, todo el contenido de todas las ediciones de una colección de revistas científicas.
Bases de datos transaccionales
Son bases de datos cuyo único fin es el envío y recepción de datos a grandes velocidades, estas bases son muy poco comunes y están dirigidas por lo general al entorno de análisis de calidad, datos de producción e industrial, es importante entender que su fin único es recolectar y recuperar los datos a la mayor velocidad posible, por lo tanto la redundancia y duplicación de información no es un problema como con las demás bases de datos, por lo general para poderlas aprovechar al máximo permiten algún tipo de conectividad a bases de datos relacionales.
Desventajas en Gestión de Bases de Datos
- Típicamente, es necesario disponer de una o más personas que administren la base de datos, de la misma forma en que suele ser necesario en instalaciones de cierto porte disponer de una o más personas que administren los sistemas operativos. Esto puede llegar a incrementar los costos de operación en una empresa. Sin embargo hay que balancear este aspecto con la calidad y confiabilidad del sistema que se obtiene.
- Si se tienen muy pocos datos que son usados por un único usuario por vez y no hay que realizar consultas complejas sobre los datos, entonces es posible que sea mejor usar una planilla de cálculo.
- Complejidad: los software muy complejos y las personas que vayan a usarlo deben tener conocimiento de las funcionalidades del mismo para poder aprovecharlo al máximo.
- Tamaño: la complejidad y la gran cantidad de funciones que tienen hacen que sea un software de gran tamaño, que requiere de gran cantidad de memoria para poder correr.
- Coste del hardware adicional: los requisitos de hardware para correr un SGBD por lo general son relativamente altos, por lo que estos equipos pueden llegar a costar gran cantidad de dinero.
Esquema
Un esquema es la definición de una estructura (generalmente relaciones o tablas de una base de datos), es decir, determina la identidad de la relación y que tipo de información podrá ser almacenada dentro de ella; en otras palabras, el esquema son los metadatos de la relación. Todo esquema constará de:
- Nombre de la relación (su identificador).
- Nombre de los atributos (o campos) de la relación y sus dominios; el dominio de un atributo o campo define los valores permitidos para el mismo, es equivalente al tipo de dato por ejemplocharacter,integer,date,string, etc.
Gestión de bases de datos
Los sistemas de gestión de bases de datos (en inglés database management system, abreviado DBMS) son un tipo de software muy específico, dedicado a servir de interfaz entre la base de datos, el usuario y las aplicaciones que la utilizan.
Gestión de bases de datos distribuida (SGBDD)
La base de datos y el software SGBD pueden estar distribuidos en múltiples sitios conectados por una red. Hay de dos tipos: 1. Distribuidos homogéneos: utilizan el mismo SGBD en múltiples sitios. 2. Distribuidos heterogéneos: Da lugar a los SGBD federados o sistemas multibase de datos en los que los SGBD participantes tienen cierto grado de autonomía local y tienen acceso a varias bases de datos autónomas preexistentes almacenados en los SGBD, muchos de estos emplean una arquitectura cliente-servidor. Estas surgen debido a la existencia física de organismos descentralizados. Esto les da la capacidad de unir las bases de datos de cada localidad y acceder así a distintas universidades, sucursales de tiendas, etcétera.
Gestores de bases de datos Libres
PostgreSQL: Es un Sistema de gestión debase de datos relacional orientada a objetos y libre, publicado bajo la licencia BSD. Como muchos otros proyectos de código abierto, el desarrollo de PostgreSQL no es manejado por una empresa y/o persona, sino que es dirigido por una comunidad de desarrolladores que trabajan de forma desinteresada, altruista, libre y/o apoyados por organizaciones comerciales. Dicha comunidad es denominada el PGDG (PostgreSQL Global Development Group). Mediante un sistema denominado MVCC (Acceso concurrente multiversión, por sus siglas en inglés) PostgreSQL permite que mientras un proceso escribe en una tabla, otros accedan a la misma tabla sin necesidad de bloqueos. Cada usuario obtiene una visión consistente de lo último a lo que se le hizo commit. Esta estrategia es superior al uso de bloqueos por tabla o por filas común en otras bases, eliminando la necesidad del uso de bloqueos explícitos.
FireBird: Es un sistema de administración de bases de datos relacional (o RDBMS) (Lenguaje consultas:SQL) de código abierto, basado en la versión 6 de Interbase, cuyo código fue liberado por Borland en 2000. Su código fue reescrito de C a C++. El proyecto se desarrolla activamente, el 18 de abril de 2008 fue liberada la versión 2.1 y el 26 de diciembre de 2009 fue liberada la versión 2.5.0 RC1Existen dos tipos de servidor Firebird para ser instalados: Classic y Super server. Si bien tienen varias diferencias menores entre sí, la principal consiste en que el super server maneja hilos de ejecución individuales para cada conexión. Por lo tanto para un número reducido de conexiones el recomendado sería el classic porque consumirá menor cantidad de recursos. En caso de arquitecturas SMP, se debe utilizar el servidor classic porque el Supersever no tiene soporte para este tipo de arquitectura.
SQLite: Es un sistema de gestión de bases de datos relacional compatible con ACID, contenida en una relativamente pequeña (~275 kiB) biblioteca en C. SQLite es un proyecto de dominio público1creado por D. Richard Hipp. A diferencia de los sistema de gestión de bases de datos cliente-servidor, el motor de SQLite no es un proceso independiente con el que el programa principal se comunica. En lugar de eso, la biblioteca SQLite se enlaza con el programa pasando a ser parte integral del mismo. El programa utiliza la funcionalidad de SQLite a través de llamadas simples a subrutinas y funciones. Esto reduce la latencia en el acceso a la base de datos, debido a que las llamadas a funciones son más eficientes que la comunicación entre procesos. El conjunto de la base de datos (definiciones, tablas, índices, y los propios datos), son guardados como un sólo fichero estándar en la máquina host. Este diseño simple se logra bloqueando todo el fichero de base de datos al principio de cada transacción. En su versión 3, SQLite permite bases de datos de hasta 2 Terabytes de tamaño, y también permite la inclusión de campos tipo BLOB. El autor de SQLite ofrece formación, contratos de soporte técnico y características adicionales como compresión y cifrado.
DB2 Express-C: DB2 express-C es un motor de base de datos perteneciente a la empresa IBM, conteniendo parte de las funcionalidades de la versión de pago DB2 propiedad tambien de la empresa IBM, este motor de base de datos es gratuita pero no libre (como aquellas que tienen licencia GPL) y cuenta con la ventaja de no tener limite de crecimiento en sus archivos de base de datos.
Apache Derby: es un sistema gestor de base de datos relacional escrito en Java que puede ser empotrado en aplicaciones Java y utilizado para procesos de transacciones online. Tiene un tamaño de 2 MB de espacio en disco. Inicialmente distribuido como IBM Cloudscape, Apache Derby es un proyecto open sourcelicenciado bajo la Apache 2.0 License. Actualmente se distribuye como Sun Java DB.
Criticas sobre Derby:
Derby está escrito en Java y no tiene bindings para otros lenguajes (no tendría mucho sentido) por lo que limita al programador a utilizarlo mediante la máquina virtual de Java y en programas escritos en ese lenguaje o lenguajes de scripting que se ejecuten sobre JVM (Jython, JRuby, Jacl, etc.). Esto por otro lado hace que las aplicaciones sean altamente portables.
Derby hace uso de una mayor cantidad de memoria y su rendimiento y compatibilidad SQL es inferior que otras alternativas como puede ser la base de datos gratuita y de código libre H2 por lo que su uso tiene poco sentido.
En su modo empotrado sólo soporta un único proceso que tenga abierta la base de datos. Sin embargo en su modo de cliente/servidor soporta el acceso de varios procesos simultáneos mediante bloqueo de filas.
Gestores de bases de datos no Libres
MySQL:
es un sistema de gestión de base de datos relacional, multihilo y multiusuario con más de seis millones de instalaciones. MySQL AB —desde enero de 2008 una subsidiaria de Sun Microsystems y ésta a su vez de Oracle Corporation desde abril de 2009— desarrolla MySQL como software libre en un esquema de licenciamiento dual.Por un lado se ofrece bajo la GNU GPL para cualquier uso compatible con esta licencia, pero para aquellas empresas que quieran incorporarlo en productos privativos deben comprar a la empresa una licencia específica que les permita este uso. Está desarrollado en su mayor parte en ANSI C. Al contrario de proyectos como Apache, donde el software es desarrollado por una comunidad pública y el copyright del código está en poder del autor individual, MySQL es patrocinado por una empresa privada, que posee el copyright de la mayor parte del código.
Advantage Database: Ofrece una ruta de crecimiento para las aplicaciones de bases de datos integradas, que permite que las aplicaciones utilicen conjuntos de funciones de nivel empresarial. Los desarrolladores que utilizan Advantage Database Server tienen la flexibilidad de utilizar varias plataformas y diferentes lenguajes de desarrollo con controladores nativos. Requiere poco o nada de mantenimiento
dBase: BASE fue el primer Sistema de gestión de base de datos usado ampliamente para microcomputadoras, publicado por Ashton-Tate para CP/M, y más tarde para Apple II, Apple Macintosh, UNIX, VMS, e IBM PC bajo DOS donde con su legendaria versión III Plus se convirtió en uno de los títulos de software más vendidos durante un buen número de años.dBASE nunca pudo superar exitosamente la transición a Microsoft Windows y terminó siendo desplazado por productos más nuevos como Paradox, Clipper, y FoxPro. Incorporaba un lenguaje propio interpretado y requería un LAN PACK para funcionar sobre red local. En 1988 llegó finalmente la versión IV. dBASE fue vendido a Borland en 1991. Al poco tiempo promovió una casi intrascendente versión 5, de la que llegó a haber versión para Windows. Luego vendió los derechos de la línea de productos en 1999 a dataBased Intelligence, Inc. (dBI) que sigue comercializando nuevas versiones, llamadas dBASE Plus, desde 1999. Durante la primera mitad de los ’80s muchas otras compañías produjeron sus propios dialectos o variaciones del producto y lenguaje. Estos incluyeron FoxPro (ahora Visual FoxPro), Quick-Silver, Clipper, Xbase++, FlagShip, y Harbour. Todos ellos son llamados informalmente como xBase o XBase. El formato subyacente de dBASE, el archivo dbf, es ampliamente utilizado en muchas otras aplicaciones que necesitan un formato simple para almacenar datos estructurados. dBASE fue licenciado a los usuarios por un plazo de quince años basado en el inconcebible evento de que un usuario utilizara su copia de dBASE por tan largo período.
FileMaker: FileMaker Pro es una aplicación multiplataforma (Windows y Mac) de base de datos relacional de FileMaker Inc. (una subsidiaria de Apple Inc.). FileMakerintegra el motor de la base de datos con la interfaz, lo que permite a los usuarios modificar la base de datos al arrastrar elementos (campos, pestañas, botones…) a las pantallas o formas que provee la interfaz.FileMaker evolucionó de una aplicación de MS-DOS, que se desarrolló primariamente para Apple Macintosh. Desde 1992 está disponible para Microsoft Windows y se puede utilizar como un ambiente heterogéneo. FileMaker está disponible para desktop, servidor y configuraciones web. La característica que define a FileMaker es que el motor de la base de datos está integrado con las vistas (pantallas, reportes, etc.) que se utilizan para acceder a él. La mayoría de las bases de datos separan estos elementos y se concentran primariamente en la organización y almacenamiento de datos.
Fox Pro: (acrónimo de FoxBASE Professional) es un lenguaje de programación orientado a objetos, que a la vez es un Sistema Gestor de Bases de datos o Database Management System (DBMS), publicado originalmente por Fox Software y posteriormente por Microsoft, para los sistemas operativos MS-DOS, MS Windows, Mac OS y UNIX.Aunque FoxPro es un DBMS y como tal soporta relaciones entre las tablas, no se le considera como un Sistema administrador de bases de datos relacionales (o RDBMS), por no soportar las transacciones.
gsBase: Es un Sistema de desarrollo cliente/servidor que permite la creación, diseño, ejecución y mantenimiento de aplicaciones de gestión o cálculo. IDE (integrated development environment). Incluye una potentísima Base de datos relacional y transaccional con registros multidimensionales de longitud variable.
IBM DB2: DB2 es una marca comercial, propiedad de IBM, bajo la cual se comercializa un sistema de gestión de base de datos.DB2 versión 9 es un motor de base de datos relacional que integra XML de manera nativa, lo que IBM ha llamado pureXML, que permite almacenar documentos completos dentro del tipo de datos xml para realizar operaciones y búsquedas de manera jerárquica dentro de éste, e integrarlo con búsquedas relacionales. La compatibilidad implementada en la última versión, hace posible la importación de los datos a DB2 en una media de 1 o 2 semanas, ejecutando PL/SQL de forma nativa en el gestor IBM DB2 La automatización es una de sus características más importantes, ya que permite eliminar tareas rutinarias y permitiendo que el almacenamiento de datos sea más ligero, utilizando menos hardware y reduciendo las necesidades de consumo de alimentación y servidores. La memoria se ajusta y se optimiza el rendimiento del sistema, con un interesante sistema que permite resolver problemas de forma automática e incluso adelantarse a su aparición, configurando automáticamente el sistema y gestión de los valores.
IBM Informix: Informix es una familia de sistema de gerencia de base de datos emparentada Productos (RDBMS) cerca IBM. Se coloca como servidor de los datos del buque insignia de IBM para tratamiento transaccional en línea (OLTP) así como soluciones integradas. IBM adquirió la tecnología de Informix en 2001 del software de Informix.
Interbase de CodeGear: es un Sistema de Administración y gestion de Base de Datos Relacionales (RDBMS) desarrollado y comercializado por la compañía Borland Software Corporation y actualmente desarrollado por su ex-filial CodeGear.Interbase se destaca de otros DBMS’s por su bajo consumo de recursos, su casi nula necesidad de administración y su arquitectura multi-generacional. InterBase corre en plataformas Linux, Microsoft Windows y Solaris. Interbase es un RDBMS que acepta el estándar SQL-92 y soporta varias interfaces de acceso como JDBC, ODBC y ADO.NET. Sin embargo, ciertas características técnicas lo distinguen de otros productos. Una instalación completa del servidor de Interbase 7 requiere aproximadamente 40Mb en disco. Esto es significativamente mas pequeño que la instalación del cliente de muchos servidores de base de datos de otras compañías. El servidor usa muy poca memoria mientras está ocioso. Una instalación mínima de un cliente InterBase requiere aproximadamente 400Kb de espacio en disco.
MAGIC eDeveloper: puede ser utilizado para el desarrollo de aplicaciones Internet y Cliente/Servidor, que utilicen Sistemas Manejadores de Bases de Datos (DBMS). Dependiendo del tipo de licencia, eDeveloper puede usar un Servidor de Licencias para administrar la licencia de todos los usuarios (Flexlm).
Microsoft Access: Es un programa, utilizado en los sistemas operativos Microsoft Windows, para la gestión de bases de datos creado y modificado por Microsoft y orientado a ser usado en entornos personal o en pequeñas organizaciones. Es un componente de la suite Microsoft Office. Permite crear ficheros de bases de datos relacionales que pueden ser fácilmente gestionadas por una interfaz gráfica sencilla. Además, estas bases de datos pueden ser consultadas por otros programas. Dentro de un sistema de información, entraría dentro de la categoría de gestión, y no en la de ofimática, como podría pensarse. Este programa permite manipular los datos en forma de tablas (formadas por filas y columnas), crear relaciones entre tablas, consultas, formularios para introducir datos e informes para presentar la información.
Microsoft SQL Server: Microsoft SQL Server es un sistema para la gestión de bases de datos producido por Microsoft basado en el modelo relacional. Sus lenguajes para consultas son T-SQL y ANSI SQL. Microsoft SQL Serverconstituye la alternativa de Microsoft a otros potentes sistemas gestores de bases de datos como son Oracle o PostgreSQL o MySQL.
Este sistema incluye una versión reducida, llamada MSDE con el mismo motor de base de datos pero orientado a proyectos más pequeños, que en sus versiónes 2005 y 2008 pasa a ser el SQL Express Edition, que se distribuye en forma gratuita.
NexusDB: es un motor de base de datos comercial para el Delphi , C + + Builder y . NET lenguajes de programación creado por Nexus Sistemas de bases de datos Pty Ltd. fue creado como un sucesor del sistema FlashFiler del Turbo Pascal días. El motor de base de datos compatible con el SQL: 2003 junto con la base estándar SQL funcionalidad.
Open Access: desarrollado por la compañía estadounidense Software Products International (SPI) entre 1984 y 1992, era un conjunto de aplicaciones de escritorio orientadas a la gestión administrativa de pequeñas y medianas empresas.Se ejecutaba en modo texto bajo entorno MS-DOS. A diferencia de las aplicaciones de línea de comandos de aquella época, el acceso a todas las funciones se podía llevar a cabo mediante selección de opciones de menú, y también por reasignación de teclas de función. Aunque en principio no disponía de soporte para ratón, ofrecía menús contextuales similares a los de un botón secundario. Además, todos los módulos se integraban en un centro de control, compartían una interfaz similar y facilitaban el intercambio de datos entre sí. Este diseño compacto y unitario utilizaba de modo más eficiente los recursos de hardware y superaba las limitaciones del sistema operativo DOS para la multitarea. Compartían el mismo enfoque otros productos rivales de aquella época (segunda mitad de los años ochenta), como Framework (de Ashton-Tate),Lotus Symphony y, más tarde, Microsoft Works. Se englobaban en la categoría de los paquetes integrados, que más tarde serían desplazados por las suites ofimáticas. OA incluía cuatro módulos principales: gestor de bases de datos, hoja de cálculo, procesador de textos y entorno de desarrollo, además de utilidades para el trabajo de oficina en colaboración, como soporte de comunicaciones, funciones de red, creación y edición de macros, generación de gráficos, cliente de correo, presentaciones y agenda.
Oracle: es un sistema de gestión de base de datos relacional (o RDBMS por el acrónimo en inglés de Relational Data Base Management System), desarrollado por Oracle Corporation. Se considera a Oracle como uno de los sistemas de bases de datos más completose considera a Oracle como uno de los sistemas de bases de datos más completos.
Paradox: Base de datos relacional para entorno MS Windows, anteriormente disponible para MS-DOS y Linux, desarrollada actualmente por Corel e incluida en la suite ofimática WordPerfect Office.En los tiempos del MS-DOS, era una base de datos de bastante éxito, compitiendo con dBase, Clipper y FoxBase. Pasó al control de Borland después de la compra de Ansa Software en 1987. Aunque Borland la portó a Windows, su cuota de mercado es mucho menor que la de Microsoft Access, pero su lenguaje de programación (ObjectPAL) es Pascal, lo que le hace más potente que Access, que usa Visual Basic y esto limita bastante sus prestaciones si se compara con otras bases de datos que usan lenguajes más avanzados. Con su Runtime se puede desarrollar una aplicación usando una sola licencia sin limitación de puestos.
PervasiveSQL: Motor de base de datos embebible que sustenta la integridad de los datos, el alto rendimiento, flexibilidad, escalabilidad y un bajo coste total de propiedad.
Progress (DBMS): Progress Enterprise RDBMS está diseñado para grandes ambientes empresariales y el procesamiento de transacciones a través de las aplicaciones más demandantes de hoy día, basadas en procesamiento de transacciones en línea (OLTP) utilizando SQL y Progress 4GL (ver figura 2). Cimentado en una arquitectura flexible, de multienlaces y multiservidor, Progress Enterprise RDBMS es una base de datos empresarial a gran escala, poderosa y abierta, que puede ejecutarse a través de múltiples plataformas de hardware y redes.
Progress Enterprise RDBMS incluye toda la funcionalidad necesaria para satisfacer los requerimientos OLTP más demandantes. Estas capacidades incluyen bloqueo a nivel de registro, recuperación «roll-back» y «roll-forward», recuperación «point-in-time», administración de la base de datos distribuida con «two-phase commit», un juego completo de utilidades en línea y soporte completo para ANSI estándar SQL-92. Una combinación de poder, flexibilidad y fácil operación hacen de Progress Enterprise RDBMS un sistema ideal para un amplio rango de aplicaciones comerciales y de procesamiento de datos. Sofisticadas capacidades autoajustables e interfaces gráficas simples para la administración del sistema, hacen de Progress Enterprise RDBMS un sistema más sencillo de instalar, afinar y administrar que otros productos. Con bajos costos de administración, un bajo costo inicial por licencias y costos mínimos por actualización, Progress Enterprise RDBMS proporciona una ventaja significativa en el costo de propiedad sobre los productos de bases de datos de la competencia.
Sybase ASE: Adaptive Server Enterprise (ASE) es el motor de bases de datos (RDBMS) insignia de la compañía Sybase. ASE es un sistema de gestión de datos, altamente escalable, de alto rendimiento, con soporte a grandes volúmenes de datos, transacciones y usuarios, y de bajo costo, que permite: Almacenar datos de manera segura, Tener acceso y procesar datos de manera inteligente, Movilizar datos
Sybase ASA: Sybase Adaptive Server Anywhere (ASA) es un Sistema administrador de bases de datos relacionales (RDBMS) de alto rendimiento, que dentro de su funcionalidad incluye gestión de transacciones, un optimizador de consultas auto-afinable, integridad referencial, procedimientos almacenados Java y SQL,triggers, bloqueo a nivel de registro, programación de eventos y recuperación automática. ASA es desarrollado por iAnywhere, subsidiaria de Sybase.
Sybase IQ: es un motor de bases de datos altamente optimizado para inteligencia empresarial, desarrollado por la empresa Sybase. Diseñado específicamente para entregar resultados más rápidos en soluciones de inteligencia empresarial analítica de misión crítica, almacenes de datos y generación de reportes, Sybase IQ combina velocidad y agilidad, con un bajo costo total de propiedad, lo que permite a las empresas llevar a cabo análisis de datos y generación de reportes antes impensables, imprácticos o costosos. La más reciente versión de Sybase IQ es la 15.2
WindowBase: WindowBase era un sistema de gestión de base de datos relacionales (SGBD) desarrollado por Software Products International como el sucesor natural de su famoso gestor para MS-DOS Open Access. Anunciada en 1991 es presentado en Europa en el CeBIT 1992 siendo inicialmente distribuida por las filiales europeas de SPI.SPI respondía así a la competencia creciente de aplicaciones que ya venían explotando las ventajas de la interfaz gráfica de usuario (GUI) de Microsoft Windows 3.x, demanda que acabaría acaparando el propio Microsoft con Microsoft Access. Costaba 495 dólares (695 $ con el SDK para C) . Incorporaba funcionalidades Dynamic Data Exchange (DDE), un software development kit con C y C++ y soporte SQL. En cuanto a la interfaz, además de personalización de menús brindaba al usuario no experto herramientas de ayuda para representar de forma gráfica los criterios de sus consultas: botones de selección, controles editables, barras de desplazamiento y casillas de verificación, además de un sistema en línea de ayuda sensible al contexto. También se incluían plantillas predefinidas de formularios de pantalla y de informes impresos. Los datos podían exportarse o importarse gracias a conexiones con los principales formatos de archivo: dBase, Btrieve o el propio Open Access-GBD. En monopuesto era compatible con Microsoft SQL Server. En 1994 se presenta la versión 2.0 a un precio de 495 dólares la nueva licencia, 79 dólares por el pack opcional de conectividad xBase, y 149 dólares por actualizaciones. En España es distribuida por Sedyco, empresa que se hizo cargo del soporte de los clientes de SPI tras del cierre de SPI Ibérica. Esta empresa lo traduce al idioma español con vistas a comercializarlo también en Hispanoamérica y lo comercializa a un precio inicial de 19.900 pesetas.
IBM IMS (Information Management System): es un gestor de bases de datos jerárquicas y un gestor transaccional con alta capacidad de proceso.IBM diseñó el IMS con Rockwell y Caterpillar en 1966 debido al Programa Apollo. El desafío de IBM era inventariar la extensísima lista de materiales del cohete lunar Saturno V y de la nave Apollo.
El primer mensaje «IMS READY» apareció en un terminal IBM 2740 en Downey, California un 14 de agosto de 1968. IMS todavía se usa extensamente 40 años después y, con el tiempo, ha visto interesantes desarrollos como el sistema IBM Sistema/360, hoy convertido en z/OS y Sistema z9. Por ejemplo, IMS soporta aplicaciones desarrolladas en Java, JDBC, XML y Servicios Web.
CA-IDMS: IDMS (Integrated Database Management System) es un ( red ) CODASYL sistema de gestión de base de datos desarrollado por primera vez en BF Goodrich y comercializados posteriormente por Cullinane base de datos de Sistemas (rebautizada Cullinet en 1983). Desde 1989, el producto ha sido propiedad de
Computer Associates , que le cambió el
nombreCA-IDMS.
Gestores de Bases de Datos no libres y gratuitos:
Microsoft SQL Server Compact Edition Básica
Microsoft SQL Server Compact (SQL Server CE) es un motor de base de datos relacional, de libre descarga y distribución, tanto para dispositivos móviles como para aplicaciones escritorio. Especialmente orientada a sistemas ocasionalmente conectados, ofrece unas características especialmente útiles para clientes ligeros. La versión más reciente es SQL Server Compact 3.5 SP2. Anteriormente era conocida como SQL Server CE o SQL Server Mobile. Desde la versión 2.0, el lanzamiento de SQL Server Compact ha ido ligado al de Microsoft Visual Studio .NET. Recientemente, Scott Guthrie, Vice-presidente Corporativo de la División de Desarrollo de Microsoft, anunció el próximo lanzamiento de SQL Server Compact 4.0 con novedades relacionadas principalmente al desarrollo de aplicaciones ASP.NET.
Gracias por Visitar mi Blog te invito a seguir explorando mis opciones en la pagina de las que te pueden interesar:
https://blogdelisc2015.wordpress.com/2017/12/28/coleccion-de-peliculas-para-celular-mp4/
Sybase ASE Express Edition para Linux (edición gratuita para Linux)
Tiene algunos límites de escalabilidad y almacenamiento, pero se puede usar libremente para desarrollo y producción.
Instancias
Una instancia de manera formal es la aplicación de un esquema a un conjunto finito de datos. En palabras no tan técnicas, se puede definir como el contenido de una tabla en un momento dado, pero también es valido referirnos a una instancia cuando trabajamos o mostramos únicamente un subconjunto de la información contenida en una relación o tabla, como por ejemplo:
- Ciertos caracteres y números (una sola columna de una sola fila).
- Algunas o todas las filas con todas o algunas columnas
- Cada fila es una tupla. El número de filas es llamadocardinalidad.
- El número de columnas es llamado grado.
Modelos de Bases de Datos
Además de la clasificación por la función de las bases de datos, éstas también se pueden clasificar de acuerdo a su modelo de administración de datos.
Un modelo de datos es básicamente una «descripción» de algo conocido como contenedor de datos (algo en donde se guarda la información), así como de los métodos para almacenar y recuperar información de esos contenedores. Los modelos de datos no son cosas físicas: son abstracciones que permiten la implementación de un sistema eficiente de base de datos; por lo general se refieren a algoritmos, y conceptos matemáticos.
Modelo relacional
El modelo relacional para la gestión de una base de datos es un modelo de datos basado en la lógica de predicados y en la teoría de conjuntos. Es el modelo más utilizado en la actualidad para modelar problemas reales y administrar datos dinámicamente. Tras ser postuladas sus bases en 1970 por Edgar Frank Codd, de los laboratorios IBM en San José (California), no tardó en consolidarse como un nuevo paradigma en los modelos de base de datos.
Su idea fundamental es el uso de (relaciones). Estas relaciones podrían considerarse en forma lógica como conjuntos de datos llamados (tuplas). Pese a que ésta es la teoría de las bases de datos relacionales creadas por Edgar Frank Codd, la mayoría de las veces se conceptualiza de una manera más fácil de imaginar, esto es, pensando en cada relación como si fuese una tabla que está compuesta por registros (cada fila de la tabla sería un registro o tupla), y columnas (también llamadas campos).
Descripción
En este modelo todos los datos son almacenados en relaciones, y como cada relación es un conjunto de datos, el orden en el que estos se almacenen no tiene relevancia (a diferencia de otros modelos como eljerárquicoy el dered). Esto tiene la considerable ventaja de que es más fácil de entender y de utilizar por un usuario no experto. La información puede ser recuperada o almacenada por medio de consultas que ofrecen una amplia flexibilidad y poder para administrar la información. Este modelo considera labase de datoscomo una colección de relaciones. De manera simple, una relación representa una tabla que no es más que un conjunto de filas, cada fila es un conjunto de campos y cada campo representa un valor que interpretado describe el mundo real. Cada fila también se puede denominar tupla o registro y a cada columna también se le puede llamar campo o atributo. Para manipular la información utilizamos un lenguaje relacional, actualmente se cuenta con dos lenguajes formales el Álgebra relacional y el Cálculo relacional. El Álgebra relacional permite describir la forma de realizar una consulta, en cambio, el Cálculo relacional sólo indica lo que se desea devolver.
Objetivos en Gestion de bases de datos
Existen distintos objetivos que deben cumplir los SGBD:
- Abstracción de la información. Los SGBD ahorran a los usuarios detalles acerca del almacenamiento físico de los datos. Da lo mismo si una base de datos ocupa uno o cientos de archivos, este hecho se hace transparente al usuario. Así, se definen varios niveles de abstracción.
- Consistencia. En aquellos casos en los que no se ha logrado eliminar la redundancia, será necesario vigilar que aquella información que aparece repetida se actualice de forma coherente, es decir, que todos los datos repetidos se actualicen de forma simultánea. Por otra parte, la base de datos representa una realidad determinada que tiene determinadas condiciones, por ejemplo que los menores de edad no pueden tener licencia de conducir. El sistema no debería aceptar datos de un conductor menor de edad. En los SGBD existen herramientas que facilitan la programación de este tipo de condiciones.
- Independencia. La independencia de los datos consiste en la capacidad de modificar el esquema (físico o lógico) de una base de datos sin tener que realizar cambios en las aplicaciones que se sirven de ella.
- Manejo de transacciones. Una transacción es un programa que se ejecuta como una sola operación. Esto quiere decir que luego de una ejecución en la que se produce una falla es el mismo que se obtendría si el programa no se hubiera ejecutado. Los SGBD proveen mecanismos para programar las modificaciones de los datos de una forma mucho más simple que si no se dispusiera de ellos.
- Seguridad. La información almacenada en una base de datos puede llegar a tener un gran valor. Los SGBD deben garantizar que esta información se encuentra segura de permisos a usuarios y grupos de usuarios, que permiten otorgar diversas categorías de permisos.
- Tiempo de respuesta. Lógicamente, es deseable minimizar el tiempo que el SGBD demora en proporcionar la información solicitada y en almacenar los cambios realizados.
Propositos en Gestión de bases de datos
El propósito general de los sistemas de gestión de bases de datos es el de manejar de manera clara, sencilla y ordenada un conjunto de datos que posteriormente se convertirán en información relevante para una organización.
Ventajas en Gestión de Objetos:
Proveen facilidades para la manipulación de grandes volúmenes de datos (ver objetivos). Entre éstas:
- Simplifican la programación de equipos de consistencia.
- Manejando las políticas de respaldo adecuadas, garantizan que los cambios de la base serán siempre consistentes sin importar si hay errores correctamente, etc.
- Organizan los datos con un impacto mínimo en el código de los programas.
- Disminuyen drásticamente los tiempos de desarrollo y aumentan la calidad del sistema desarrollado si son bien explotados por los desarrolladores.
- Usualmente, proveen interfaces y lenguajes de consulta que simplifican la recuperación de los datos.
PROGRAMAS DE UTILIDAD:
Los programas de utilidad sirven como herramientas para llevar a cavo el mantenimiento del sistema y efectuar algunas operaciones que el sistema operativo no maneja de forma automática.
Ejm:
Fragmentación de Archivos.
Es una condición por la que los archivos se dividen en el disco en pequeños segmentos separados físicamente entre si. Esta condición es una consecuencia natural del crecimiento de los archivos y de su posterior almacenamiento en un disco lleno. Este disco ya no contendría bloques contiguos de espacio libre lo suficientemente grandes como para almacenar los archivos. La fragmentación de archivos no es un problema de integridad, aunque a veces puede ocurrir que los tiempos de acceso y de lectura aumenten si el disco esta muy lleno y el almacenamiento se ha fragmentado incorrectamente. Existen productos de software para organizar u optimizar el almacenamiento de archivos.
En una base de datos, la fragmentación del archivo es una situación en la cual los registros no se graban en su secuencia de acceso óptima debido a las continuas adiciones y eliminaciones de registros. La mayoría de los sistemas de bases de datos cuentan con utilidades que reordenan los registros para mejorar el rendimiento de acceso y recuperar el espacio libre ocupado por los registros borrados.
Compresión de Datos.
También llamada compactación de datos. Y es el término que se aplica a diversos métodos para compartir la información a fin de permitir una transmisión o almacenamiento más eficaces. La velocidad de compresión y descompresión y el porcentaje de compresión (la relación entre los datos comprimidos y sin comprimir) dependen del tipo de los datos y el algoritmo utilizado. Una técnica de compresión de archivos de texto, la llamada codificación de palabras clave, sustituye cada palabra que aparece con frecuencia como por ejemplo el o dos por un puntero (uno o dos bytes) a una entrada de una tabla (que se guarda en el archivo) de palabras. Las técnicas de compresión fuzzy (por ejemplo JPEG), utilizadas en compresión de audio y vídeo, tienen un porcentaje de compresión muy elevado, pero no permiten recuperar exactamente el original.
Administración de Memoria.
Sea cual sea el esquema de organización del almacenamiento que se adopte para un sistema específico, es necesario decir que estrategias se deben utilizar para obtener un rendimiento optimo. Las estrategias de administración del almacenamiento, determinar el comportamiento de una organización de almacenamiento determinada cuando se siguen diferentes políticas: ¿Cuándo se toma un nuevo programa para colocarlo en la memoria? ¿Se toma el programa cuando el sistema lo solicita específicamente o se intenta anticiparse a las peticiones del sistema? ¿En que lugar del almacenamiento principal se coloca el siguiente programa por ejecutar? ¿Se coloca los programas lo más cerca posible uno del otro en los espacios disponibles de la memoria principal para reducir al mínimo el desperdicio de espacio, o se colocan los programas lo más rápido posible para reducir al mínimo el tiempo de ejecución ? .
LENGUAJE DE PROGRAMACION:
DEFINICION:
Son métodos por medio de los cuales los programadores se comunican con el computador, existen muchos lenguajes de programación, la mayoría de los cuales tienen un conjunto de reglas muy estructurado. La selección depende de quien este implicado y la naturaleza de la “conversación”; por ejemplo, se usa un lenguaje para crear sistemas de programación para toda una empresa y otro para una presentación dinámica de ventas.
GENERACIONES:
–Lenguaje de maquina (la lengua materna):
Es la lengua materna de la computadora; crear programas en lenguaje de maquina suele ser um proceso un poco fastidioso, por lo tanto se escriben en lenguajes de programación mas sencillos para el programador. Sin embargo, los programas así escritos deben traducirse al lenguaje de maquina para que sean ejecutados.
-Lenguajes orientados a procedimientos:
La introducción de lenguajes de programación más amistosos en 1955 permitió un cambio cualitativo en la comodidad de los programadores ya que estos pudieron escribir una sola instrucción en lugar de numerosas y fastidiosos procedimientos, esto es, requerían que los programadores resolvieran los problemas mediante la lógica tradicional de programación. Así, el programador codifica o escribe las instrucciones en la secuencia que deben ejecutarse para resolver el problema. Ejemplo de este tipo de lenguaje son el COBOL y el FORTRAN ambos introducidos a fines de lo 50.
-Lenguajes orientados a objetos y a la OOP:
En este tipo de lenguaje el énfasis se encuentra en el objeto de la accion , de ahí la orientación del obeto. La estructura jerarquica , de arriba a bajo de la programación orientada a objetos permite que sea mas facil diseñar y entender los programas . Asimismo la tendencia en programcion va orientada en el sentido de usar mas imágenes, videos y sonidos. La (OOP) maneja estos elementos mejor que los lenguajes de procedimientos.
-los lenguajes de cuarta generación (4GL):
Por lo general, son, los especialistas en computación quienes programan con lenguajes de procedimientos o por objetos. Pero la programación con los 4GL, además de estar a cargo de los especialistas también puede ser utilizada por los usuarios finales, pues es más sencilla. Los usuarios escriben programas de 4GL para consulta (extraer información de) una base de datos y crear sistemas de información personales o para el departamento de una compañía.
Los lenguajes de cuarta generación usan instrucciones de alto nivel parecidas al ingles, para recuperar y darle formato a los datos de consulta y reportes.
-Otros lenguajes de programación son:
*ALGOL: (1960)
*BASIC: (1964)
*COBOL: (1958)
* C: (1970)
*FORTRAN: (1957)
*MODULA-2: (1979)
* PASCAL: (1970)
*PL/I: (1965)
*APL: (1961)
*LISP: (1960)
*PROLOG: (1972)
*FORTH
*ADA.
