Ein Blog über Sprache, Dialekte, Grammatik und das Leben überhaupt.
Ein Blog über Sprache, Dialekte, Grammatik und das Leben überhaupt.
Auf Reflexe des Kasusumlauts bin ich durchs Unterrichten gestoßen: Bei der Vorbereitung für eine Seminarsitzung zur historischen Morphologie des Deutschen nahm ich mal wieder die Einführung von Nübling und Kolleginnen in die Hand, die mittlerweile die stolze fünften Auflage erreicht und sich zu einem regelrechten Handbuch gemausert hat. Dort findet sich im Kapitel zur Interaktion von Phonologie und Morphologie der kurze Hinweis auf die Relevanz von Ortsnamen (Nübling et al. 2017: 299–300), und zwar mit Bezug auf die bahnbrechende Untersuchung von Sonderegger (1979), wo dieses Thema en passant erwähnt wird. An einem Freitag Nachmittag gegen Ende des Semesters, wo die angestrebte Einheit von Lehre und Forschung mehr und mehr einer geistigen Leere weicht, kam mir der Gedanke, dass sich da sehr schnell neue Befunde gewinnen lassen, und über diese möchte ich hier berichten.
Zuerst ein bisschen sprachgeschichtlicher Hintergrund: Der sogenannte i-Umlaut ist eine der phonologischen Veränderungen, die alle altgermanischen Sprachen betrifft (wenn wir einmal großzügig das Gotische ausklammern). Während er im Englischen oder Niederländischen wieder weitgehend beseitigt wurde, ist er im Nordgermanischen in unterschiedlichen Graden erhalten, dümpelt aber sozusagen als Anomalie vor sich hin. Um deutlichsten sind seine Spuren im Isländischen greifbar, wo sich beispielsweise Umlaute ins ganze Paradigma von gestur ,Gast‘ gefressen haben, während das zur selben Deklinationsklasse gehörende staður ,Stelle‘ umlautlos ist. Hier gibt es freilich Wechselwirkungen mit anderen vokalischen Veränderungen, die zu palatalisierten Vokalen führen (siehe dazu Nübling 2013: 22–26), aber dies ändert nichts an dem Befund, dass wir es mit einer phonologischen Sauerei ohne morphologische Aufräumarbeiten zu tun haben. Dieses grobe Bild berücksichtigt nicht die mitunter große dialektale Variabilität, z.B. sind die ostniederländischen Dialekte deutlich umlautfreudiger als ihre westlichen Pendants (Nübling 2013: 26–27).
Nur im Deutschen schaffte es der Umlaut ins morphologische System und führte dort zu tiefgreifenden Veränderungen, die allenthalben bemerkbar sind (Übersicht zusammengestellt aus Wiese 1996: 114, 116; Nübling et al. 2017: Kap. 10.2):
Das bekannteste Beispiel für die Morphologisierung ist die Substantivdeklination: So finden wir beispielsweise bei den i-Stämmen Umlautformen genau in den Paradigmenzellen, die den entsprechenden Auslöser, d.h. stammbildendes i und seine Reflexe enthalten.

Tabelle 1: Ahd. i-Stämme (Formen aus Braune und Heidermanns 2018: 277 und Paul et al. 2007: 185, 187)
Beim Übergang zum Mittelhochdeutschen verschwinden die Kasusumlaute im Gen. und Dat. wieder; auslautendes e (das durch die Nebensilbenabschwächung aus i entstanden ist) wird in diesen Paradigmenzellen apokopiert. In den Pluralformen bleibt der Umlaut demgegenüber erhalten, jedoch zeigt nur noch der Dativ eine eigene Form (im Ahd. sind Genitiv und Dativ noch durch die Flexive -im bzw. -io markiert). Das bedeutet, dass Kasusunterschiede abgebaut werden, die Numerusunterscheidung aber stabil bleibt und teilweise sogar per analogischer Ausdehnung ausgebaut wird (Stichwort: Numerusprofilierung vs. Kasusnivellierung; Hotzenköcherle 1962). So weist das Substantiv Wort (a-Deklination), das ursprünglich einen Nullplural hatte, im Neuhochdeutschen den doppelt markierten Plural Wört-er auf, wobei beide morphologische Zeichen, also der Umlaut und das Suffix -er, per Analogie übertragen wurden. Bei gewissen Substantiven mit den Stammauslaut auf Schwa-Silbe oder silbischem Sonoranten -er, -en und -el kann er als alleiniges Pluralkennzeichen dienen, z.B. Mütter /ɐ/, Gräben /ən/, Vögel /əl/ (siehe dazu Wiese 2009: 138–139). Insbesondere in jenen Dialekten, bei denen die Apokope additive Pluralkennzeichen beseitigt hat, stellt analogischer Umlaut die Pluralkennzeichnung sicher (Schirmunski 1962: 203), geht aber auch über diese Kontexte hinaus. Konkretes Anschauungsmaterial aus meinem Vorarlberger Alemannischen sind Formen wie Taag – Tääg ,Tage‘, Hund – Hünd ,Hunde‘, Nama – Näma ,Namen‘, Broot – Brööter ,Brote‘ usw.
Im Ahd. bzw. frühen Mhd. gibt zum Thema Kasusumlaut noch einiges zu holen. Dies lässt die kleine ReM-Korpusrecherche von Hartmann (2018: 131–132) zu kraft erkennen, die er anhand des Referenzkorpus Mittelhochdeutsch durchführte: Auch noch in der ersten Hälfte des 14. Jahrhunderts findet sich robuste Evidenz für umgelautete Formen im Gen./Dat., wenngleich eine deutliche generelle Tendenz zur Abnahme festzustellen ist. Auch im unlängst erschienen Morphologie-Band der großen Mittelhochdeutschen Grammatik wird auf Vorkommen des Kasusumlauts eingegangen (Klein et al. 2018: 121 und später), aber die Angaben sind etwas inkonklusiv (Danke an Jürg Fleischer für diesen Hinweis).
Zurück zum Thema: Ein bemerkeneswerter Datenbereich, wo sich Reflexe des Kasusumlautes erhalten haben, sind Ortsnamen. Der sprachgeschichtliche Hintergrund ist hier leicht anders gelagert (Infos im Folgenden aus Braune und Heidermanns 2018: 282–287 [§§ 221–224], 309–310 [§§ 255–256]): Auch bei der schwachen Adjektivdeklination finden sich im Gen. und Dat. Sg. Kasusumlaute; diese stimmt mit den maskulinen und neutralen Substantiven der n-Deklination überein (an-Stämme), erkennbar an Formen wie hanin/henin ,Hahn‘ (Gen./Dat.) oder namin/nemin ,Name‘ (Gen./Dat.) In Tabelle 2 sind entsprechende Formen in einer vergleichenden Übersicht zusammengetragen (aus Sonderegger 1979: 309).
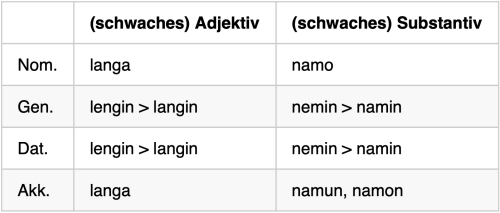
Tabelle 2: Kasusumlaute beim schwachen Adjektiv und Substantiv im Vergleich
Ich habe eine kleine Auswertung zum erstarrten Kasusumlaut bei Ortsnamen durchgeführt. Als Beispiele dienten Langenfeld und Langenbach, bei denen von einer weitgehend unproblematischen Etymologie auszugehen ist, z.B. zi demo langin/lengin fëlde ,bei dem langen Feld‘. Solche Erstarrungen des Dativs als Präpositionalkasus bei lokal-statischer Bedeutung zum Nominativ sind bei der Onymisierung von Ortsnamen häufig zu beobachten (Nübling et al. 2015: 217). Im Einzelnen wäre dies natürlich zur prüfen, insbesondere das Alter der jeweiligen ON (bei nicht-fassbarem Umlaut) zu bestimmen, ist keine triviale Angelegenheit. Hier stößt man schnell auf praktische Probleme, da man ggfs. die verfügbare onomastische Spezialliteratur konsultieren müsste, die nicht immer leicht zu finden oder zu beschaffen ist.
Berücksichtigen konnte ich nur jene Orte, die über Wikipedia verfügbar und deren Geokoordinaten via Scraping abgreifbar sind. Vermutlich gibt es noch zahlreiche weitere Fälle, z.B. Flurnamen, Ortsteile oder Weiler, aber die erste Probebohrung hat durchaus Interessantes zutage gefördert. Die Originaldaten und das dafür verwendete Python-Skript sind über GitHub hinterlegt, mit dem Rede-SprachGIS lassen sich dynamische Punktkarten erstellen und verlinken (blöderweise braucht man einen Benutzeraccount, um die Kartierung ansehen zu können). Hier die statische Version zu direkten Anschauungszwecken:
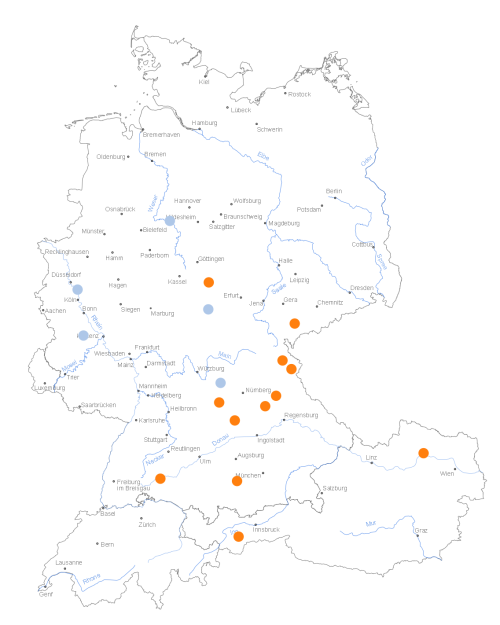
Karte 1: Varianten des Ortsnamens Langenfeld (e/ä-Formen jeweils orange)

Karte 2: Varianten des Ortsnamens Langenbach (e/ä-Formen jeweils orange)
Was sieht man? Wirft man beide Einzelkartierungen in einen Topf, wie dies online einfach möglich ist, erkennt man eine bemerkenswerte areale Häufung von Umlautformen im Oberdeutschen. Dies ist umso erstaunlicher, als insbesondere die erstere Sprachlandschaft als resistent gegenüber dem phonologischen Umlaut gilt (Schirmunski 1962: 201).
Man darf’s mit der rückprojizierenden Kartenexegese à la Frings nicht zu weit treiben, aber einen ersten Anhaltspunkt liefert diese Auswertung allemal.
Braune, Wilhelm und Frank Heidermanns (2018): Althochdeutsche Grammatik. Bd. 1: Laut- und Formenlehre. (Sammlung kurzer Grammatiken germanischen Dialekte –Hauptreihe; 5.1). Berlin, Boston: De Gruyter.
Hartmann, Stefan (2018): Deutsche Sprachgeschichte. Grundzüge und Methoden. (UTB; 4823). Tübingen: Francke.
Hotzenköcherle, Rudolf (1962): Entwicklungsgeschichtliche Grundzüge des Neuhochdeutschen. In: Wirkendes Wort 12: 321–331.
Klein, Thomas, Hans-Joachim Solms und Klaus-Peter Wegera (2018): Mittelhochdeutsche Grammatik. Bd. 2: Flexionsmorphologie. Berlin, Boston: De Gruyter.
Paul, Hermann [et al.] (2007): Mittelhochdeutsche Grammatik. (Sammlung kurzer Grammatiken germanischer Dialekte – Hauptreihe; 2). Tübingen: Niemeyer. 25. Aufl.
Nübling, Damaris (2013): Zwischen Konservierung, Eliminierung und Funktionalisierung: Der Umlaut in den germanischen Sprachen. In: Jürg Fleischer und Horst J. Simon (Hgg.): Sprachwandelvergleich – Comparing Diachronies: 15–42. (Linguistische Arbeiten; 550). Berlin, Boston: De Gruyter.
Nübling, Damaris, Fabian Fahlbusch und Rita Heuser (2015): Namen: Eine Einführung in die Onomastik. (Narr Studienbücher). Tübingen: Narr. 2. Aufl.
Nübling, Damaris [et al.] (2017): Historische Sprachwissenschaft des Deutschen: Eine Einführung in die Prinzipien des Sprachwandels. (Narr Studienbücher). Tübingen: Narr. 5. Aufl.
Schirmunski, Viktor (1962): Deutsche Mundartkunde. Vergleichende Laut- und Formenlehre der deutschen Mundarten. (Veröffentlichungen des Instituts für deutsche Sprache und Literatur; 25). Berlin: Akademie Verlag.
Sonderegger, Stefan (1979): Grundzüge deutscher Sprachgeschichte. Diachronie des Sprachsystems. Bd. 1: Einführung – Genealogie – Konstanten. Berlin, New York: De Gruyter.
Wiese, Richard (1996): Phonological versus morphological rules: on German Umlaut and Ablaut. In: Journal of Linguistics 32: 113–135.
—(2009): The grammar and typology of plural noun inflection in varieties of German. In: Journal of Comparative Germanic Linguistics 12: 137–173.
Zum Jahreswechsel ein Büchertipp. Eigentlich wäre das ja was für den linguistischen Gabentisch gewesen, aber im vorweihnachtlichen Trubel hab ich meine Besprechung einfach nicht mehr fertig bekommen.
NEUTSCH: Grammatik, Wortschatz, Literatur. edition b, 2021, 200 S., 13 x 19,5 cm, Hardcover, ISBN: 978-3-033-08529-9
Dieses höchst amüsante und lesenswerte Büchlein ist der Niederschlag aus zwanzig Jahren kreativer Beschäftigung mit den morphologischen Systempotenzialen des Deutschen: Im Jahre 2002 formierte sich die Gesellschaft zur Stärkung der Verben (GSV), deren erklärtes Ziel es ist, Verben zur Hilfe zu eilen, „die von Schwächung bedroht sind oder die schon immer schwach waren und eine starke Konjugation verdienen“ (S. 11). Diese gestärkte Varietät des Deutschen nennt sich Neutsch.
Ausgangspunkt ist die allseits bekannte Beobachtung, dass es im Deutschen zwei große Verbklassen gibt, die sich in ihren Flexionseigenschaften unterscheiden. Da sind die starken Verben, deren Formenbildung (auch) mittels Stamm-Modulation geschieht. Und es gibt die schwachen, bei denen alles additiv, also mittels Affigierung, vor sich geht. Typische Kennformen, die man quasi als Lackmustest nehmen kann, sind in (1) und (2) angeführt. Wir haben den Ablaut, der der Tempusbildung dient (1a); zu diesem gesellen sich der Umlaut im Konjunktiv (1b) und der 2/3SG Präs., und zwar vor allem bei den ehemaligen Ablautreihen 6–7 (1c). Im letzteren Kontext tritt auch die sogenannte e/i-Hebung auf (2a), die wir auch im Imperativ finden (2b). Die Alternanzen in der 2/3SG sind auch als Wechselflexion bekannt.
(1a) sinken – sank – gesunken
(1b) sänke – sänken usw.
(1c) waschen – wäschst – wäscht
(2a) geben – gibst – gibt
(2b) gib!
Ich übergehe hier großzügige verschiedene (historische) Sonderklassen wie beispielsweise die Modalverben (aka Präteritopräsentien), die Rückumlautverben (à la kennen – kannte – gekannt) oder gar das Uran-238 unter den irregulären Verben, nämlich sein mit seinem stark suppletiven Paradigma: ist – sind – war – gewesen usw.
Die generelle Tendenz ist die, dass die irregulären Verben immer weniger, die regulären immer mehr werden, auch wenn es Ausreißer in beide Richtungen gibt. In allen germanischen Sprachen sind solche Regularisierungstendenzen (bis hin zum Flexionsklassenwechsel) zu beobachten: Im Deutschen sinkt die Zahl starker Verben von 349 im Ahd. über 339 im Mhd. auf 169 im Nhd. (Nübling 1998: 195); Niederländisch hat derer noch ca. 180 (Booij 2002:59–60); bei den skandinavischen Sprachen ist je nach Zählung noch von ca. 100–150 auszugehen. Im Englischen schließlich gibt es nach Harbert (2007: 70) nur noch 70 Vertreter dieser Klasse. Einzentraler Faktor bei der Regularisierung ist die Auftretensfrequenz, jedoch muss man diese differenziert betrachten. Von ca. 4000 Verben im Lexikon sind zwar nur 169 stark, doch unter den 1000 häufigsten Wortformen befinden sich 80 Verben, die zu gleichen Anteilen den beiden Großtypen angehören (detailliertere Frequenzangaben bei Augst 1975: 235, 258).
Für das Englische haben Lieberman et al. (2007) gezeigt, dass die Regularisierungsrate (ehemals) starker Verben mit ihrer Frequenzklasse korreliert. Diese kann man logarithmisch skalieren: Wenn etwa ein Verb zur Frequenzklasse 3 gehört, bedeutet dies vereinfacht gesprochen, dass es im Bereich von tausenden Wortformen vorkommt, Frequenzklasse 4 heißt demgegenüber zehntausende Wortformen usw. Die Regularisierungsrate, d.h. die Zahl der bereits regularisierten Verben, steigt proportional zur Frequenz (Lieberman et al. 2007: 714). Mathematisch gesprochen haben wir es mit einem Zerfallsprozess zu tun, der sich als gewöhnliche Differentialgleichung beschreiben lässt. Irreguläre Verben sind sozusagen radioaktives Material und man kann die Halbwertszeit bestimmen, innerhalb derer die Hälfte der Vertreter der jeweiligen Frequenzklasse bereits regularisiert sind. Also, wer im Zusammenhang mit Sprachwandel von Verfall reden will, der hat in diesem speziellen Kontext meinen Segen.
Im Deutschen wurde ein vergleichbarer Effekt gefunden, auch wenn hier die Regularisierungsrate niedriger ist (Carroll et al. 2012). Entscheidender Faktor ist die jeweilige Ablautklasse. Bei den Gruppen 4 (binden – band – gebunden), 5 (sprechen – sprach – gesprochen) und 7 (gehen – ging – gegangen) liegt diese deutlich höher als bei den anderen (Carroll et al. 2012: 164). Bemerkenswerterweise treten hier dreistufige Ablautunterscheidungen auf, anders als etwa in Gruppe 1 (reiten – ritt – geritten), 2 (ziehen–zog–gezogen) oder 6 (heben–hob–gehoben).
Natürlich wird eine solch krude quantitative Perspektive der Vielschichtigkeit und Komplexität von flexionsklassengebundenen Veränderungen nicht gerecht, denn wir wissen, dass sich diese nicht spontan vollziehen, sondern eine paradigmatische Gerichtetheit aufweisen. So stellt etwa Bittner (1996) die in (3) angeführte implikationelle Hierarchie für Regularisierungsprozesse auf, deren Kennformen in (4) illustriert sind.
(3) Imperativ-Hebung (e > i) →
2./3. Pers. Sg. Präs. (Wechselflexion) → Prät. Sg. (Ablaut) →
Part. Prät. (Ablaut)
(4a) essen – iss!
(4b) läufst, läuft – laufen
(4c) gehe – ging
(4d) trinken – getrunken
Diese Hierarchie macht die Vorhersage, dass Regularisierung in Bezug auf eine Position weiter rechts auch Regularisierung der Positionen weiter links impliziert (aber nicht umgekehrt). Diese Beziehungen können leicht anhand des „schwächelnden“ Verbs melken nachvollzogen werden, das schon seit einiger Zeit Regularisierungstendenzen erkennen lässt. Reguläre Formen haben sich schon bis zum Part. Prät. ausgedehnt: milk/melk(e) → milkst/melkst → molk/melkte → gemolken/gemelkt (in der letzteren Paradigmenzelle sind schwache Formen noch relativ selten, aber gut dokumentiert). Eine Verletzung dieser Hierarchie läge vor, wenn irreguläre Formen im Prät. Sg. dominierten, während dies bei regulären Formen in der 2./3. Sg. Präs. der Fall wäre. Dies ist allerdings nicht der Fall, denn letztere sind in beiden Positionen häufiger.
Wie bereits angedeutet, kommt es immer wieder zum gegenläufigen Effekt, d.h. reguläre Verben können sich Richtung Irregularität bewegen: Man denke etwa an haben, das seine Karriere als schwaches Verb begann, im weiteren Verlauf aber zunehmend irregularisiert wurde und heute ein schwach suppletives Pardigma aufweist, erkennbar an Formen wie habe gegenüber hast oder hätte usw. (Nübling 2001). Die sprachgeschichtlich jüngere Partizipform gewunken passt wunderbar in das Schema der zahlreichen irregulären Verben, die als Präsens- und Infinitivstamm die Kombination ɪ + Nasal und ggfs. einen weiteren Konsonanten aufweisen (z.B. trinken, sinken, stinken, singen usw.), denn es gibt kaum schwache Grundverben mit dieser phonotaktischen Struktur (Köpcke 1998: 55–56). Schließlich können sich schwächelnde Verben in einer Art Auffangbecken (Abklingbecken) sammeln und sich dem 0815-Ablautschema x-o-o (ursprünglich 6. Ablautreihe) angleichen, wie man es historisch etwa bei melken und gegenwartssprachlich bei verschiedenen Kandidaten beobachten kann (Nowak 2013).
Soviel zum allgemeinen sprachgeschichtlichen Hintergrund und zurück zum Jux: Mit den Tücken der deutschen Flexion haben sicherlich schon andere jongliert; eine tiefergehende Recherche wäre eine Fleißaufgabe, die ich mir spare. Spontan musste ich jedenfalls an Karl Valentins genialen Brief aus Bad Aibling denken, wo Stark-Schwach-Zwitter wie aßte oder zogte und ungewöhnliche Ablaute wie schrub (für schrieb) als i-Tüpfelchen auf die satirische Sahnehaube gestreut sind (Valentin 1961: 412–413).
Wie macht man nun aus schwachen Verben neue Kraftpakete? Das erste Mittel der Wahl besteht darin, ihnen das Dentalsuffix zu ziehen und stattdessen Ablautalternanzen zu verpassen (S. 18). Wir haben also beispielsweise lallen – lällt (Wechselflexion) – liel – liele (Konj. 2) – gelallen, also quasi das Analogon zu fallen. Zusätzlich können Konsonanteneinschübe oder -wechsel auftreten, wie wir sie auch vom sogenannten grammatischen Wechsel kennen, also drehen – dreht – drand – drände/dründe – gedranden (wie stehen) oder vermiesen – vermiest – vermor – vermöre – vermoren bzw. schmieden – schmiedet – schmott – schmötte – geschmotten (wie sieden).
Aber auch Ablautalternanzen, die wir vom Deutschen nicht kennen, finden sich im Neutschen, und zwar insbesondere mit [ɔː] (= å) oder œ (= œ), erkennbar in Formen wie blåk (blökte) oder hœle (holte, Konj. 2) sowie mit sonderbaren Diphthongen wie griam (grämte) (S. 19, 21–22). Das morphologische Herz höher schlagen lassen Temsis-Formen à la faulenzen – linzt faul – lonz faul – lönze faul – faulgelonzen (S. 23–24) oder die Coniugatio duplex, die in Formen wie presseschleifen – schleift press – schliff prass – schliffe pröss – prossgeschliffen „die Konjugierzange gleich doppelt“ ansetzt (S. 26). Ich musste dabei an Marga Reis’ Kabinett an defektiven Verben im Deutschen denken, das neben dem allseits bekannten schinden (Prät.?) auch radebrechen (2./3. Sg. Präs.?, Prät.?), willfahren (Prät.?) oder auserkoren (Präs.?) umfasst (siehe Reis 2017: 260). Mein absolutes Favorite ist indes die reduplikative Konjugation bei Modalverben, die uns Bijoux wie können – kann – kekünne – gekönnen beschert (S. 28).
Der Spaß hört nicht bei den Verben auf. Auch gestorkene (gestärkte) Adjektive und Substantive sind im Neutschen zu finden, ich überlasse es dem Entdeckergeist meiner Leserschaft, sich in die entsprechenden Besonderheiten der Formenbildung zu vertiefen (S. 33–42). Auch Singularia. bzw. Pluraliatantum, die semantisch bedingte Numeruslücken aufweisen, müssen dafür nicht büßen, sondern bekomme die fehlenden Formen quasi per Absolution, z.B. Desinteressen, Schwachsinne oder Zetera und Mordien auf der einen sowie die Ferie ,freier Tag‘, die Flause ,einzelner Unsinn‘ auf der anderen Seite; bei das Leut ,einzelne Person‘ treffen sich Blödsinn und sprachgeschichtliche Realität, denn dieses Substantiv existierte in mhd. Zeit tatsächlich als Hybrid Noun (im Sinne von ,Volk‘, vgl. der liut, daʒ liute). In diesem Dunstkreis stehen auch die etwas verwirrend als „dimunitive Singulare“ genannten Formen wie das Ah „der Ehepartner“ oder „der Konfetto“ (Sg.) – gemeint sind wohl Singulative.
Eine morphologische Lücke, die im Deutschen umso gähnender klafft, wenn wir neidvoll auf entsprechende Formen aus dem Neutschen sehen, besteht in verbalen Komparativformen. Kostprobe? „Die haben es noch verkackener als wir.“ (S. 76) Gleiches gilt für Augmentative, die uns allenfalls aus deutschen Dialekten bekannt sind (z.B. Trumm im Bairischen), aber durchaus als schließenswerte onomasiologische Lücke zu sehen sind, etwa der Donnerlitt ,Ausruf größtmöglichen Erstaunens‘ (S. 81).
Last but not least möchte ich noch das Kapitel zu Negationsbildungen und Antonymen hervorheben (S. 87–108), denn hier zeigt sich einmal mehr, wie viel grammatisches Feingespür das Neutsch-Kollektiv unter Beweis stellt. Im Deutschen gibt es zahlreiche Adjektive, die nur in negierter Forme existieren, z.B. unbeholfen (aber *beholfen). Helmut Weiß verdanke ich den Hinweis auf Paradoxien wie nicht unübel: Ein Adjektiv wie unübel ohne freie Negationspartikel existiert nicht, und zu allem Überfluss ist un- hier semantisch leer, denn es bedeutet ja ,nicht übel‘ und nicht ,besonders schlecht‘. Im Neutschen hingegen haben wir ganz selbstverständlich auch Formen wie beholfen ,geschickt‘ (S. 88) oder gefähr ,genau‘ (S. 89), ja nicht einmal vor entsprechenden Lücken bei Konfixbildungen macht der Schöpfergeist halt, z.B. fantil ,reif‘ oder pressiv ,froh, aktiv‘ (S. 91).
In die grammatische und einzellexematische Darstellung des Neutschen eingeflochten sind eine Reihe von dichterischen Schmuckstücken, die zeigen, dass „Unsinnspoesie“ ihrem Namen oft nicht gerecht wird und eher die Gattungsbezeichnung Feinsinnspoesie verdient. Als erste Lesefrucht ein Limerick von Michael Gewalt (S. 43):
Ein Schwachverbenverstärker aus Labenz
stork Verben von morgens bis abends.
Auch Nomen er stork,
wobei er bemork
die Einspar so machen Buchstabens.
Auch wenn das Konsonantenstadl zu strikter Neutralität in Fußballfragen verpflichtet ist, sind folgende Zeilen mit dem Titel Vorsicht, Bayern! von Gerhard Schwenke einfach zu hübsch, um sie Euch vorzuenthalten (S. 31):
Schlönz’ Zidane seine Flanken
Brächt’ er Olli Kahn ins Wanken
Und quasi als Beitrag zum ehrwürdigen Genre der Heideregger-Parodien wirft caru folgende ontologische frage auf (S. 78):
nächte das nichts nicht,
wär’ des nichtses nichte dann
niemand oder nichts?
By the way: Wer sich umfassender mit diesem Thema auseinandersetzen möchte, dem empfehle ich Alfred Liedes monumentales Buch Dichtung als Spiel: Studien zur Unsinnspoesie an den Grenzen der Sprache (Liede 1992a, b). Dort erfährt man u.a. mehr über die sogenannte Tmesis als spielerisches Verfahren: Bei dieser Spielerei „werden Wörter um den Metrums [oder Spaßes; O.S.] willen in Silben oder Silbengruppen zerlegt“ (Liede 1992b: 120).
Der Sprachgeschichtler in mir ist hocherfreut zu sehen, dass das Neutsche auch eine (kurzzeit-)diachrone Dimension hat. Die bisher skizzierten Regularitäten betreffen das sogenannte Nittelhochmeutsche, dem sich Teil I des Buches widmet. Das Deuhochneutsche, wie es im anschließenden, weitaus kürzeren Teil II beschrieben ist, dreht die Eskalationsschraube fröhlich weiter. Es verfügt über einen stolzen Bestand an (Anti-)Kausativen (S. 129–135), aus der Erstarrung erwachten Partizipien (S. 138–143), inhärenten Reflexiven, die sich zu normalen Transitiva aufschwingen (S. 149–151), und einem bunten Strauß an weiteren Irregularisierungsstrategien („Verben stärken für Fortgeschrittene“, S. 158–177).
Man kann die GSV und ihr Wirken als pure Lust am Spielen sehen. Ich erkenne darin aber auch eine augenzwinkernde Replik auf die Sprachverhunzungsphobien und Untergangsphantasien eines Vereins Deutsche Sprache (VDS) und anderer, selbst ernannter Sprachhüter. Das Deutsche, eine Sprache mit ca. 100 Mio Muttersprachlern, ist ganz gewiss nicht dem Untergang geweiht, und zwar weder durch eine drohende Anglizismen-Sintflut noch durch einen vermeintlichen Rückfall ins Gender-Gaga.
Wer übrigens mal eine kreative Pause von der in unserer Zunft fast schon hysterisch geführten Debatte um die sprachliche Sichtbarkeit von Geschlechter:inn:en braucht, dem sei der Reiter Klarmachen zum Gendern! auf der Gesellschafts-Website empfohlen: Man kann sich dem Thema auch spielerisch und nicht so bierernst nähern. Das Ganze wird sich, wie man im österreichischen Deutsch so schön sagt, eh schon richten, denn beim Sprachwandel (for the better or the worse) haben wir alle ein Wörtchen mitzureden.
Ich wünsche der GSV regen Zustrom und diesem Büchlein eine große Leserschaft. In Sonderheit hoffe ich, dass sich der Schluss-Satz im Abschnitt zur Geschichte der GSV (S. 181–189) bewahrheiten wird: Fortsatz kann nicht ausgeschlossen werden!
Augst, Gerhard (1975): Untersuchungen zum Morpheminventar der deutschen Gegenwartssprache. (Forschungsberichte des Instituts für Deutsche Sprache Manneim; 25). Tübingen: Narr.
Bittner, Andreas (1996): Starke ,schwache‘ Verben und schwache ,starke‘ Verben. Deutsche Verbflexion und Natürlichkeit. (Studien zur deutschen Grammatik; 51). Tübingen: Narr.
Booij, Geert (2002): The Morphology of Dutch. Oxford: Oxford University Press.
Carroll, Ryan, Ragnar Scare und Joseph Salmons (2012): Quantifying the evolutionary dynamics of German verbs. In: Journal of Historical Linguistics 2(2): 153–172.
Harbert, Wayne (2007): The Germanic Languages. (Cambridge language surveys). Cambridge: Cambridge University Press.
Köpcke, Klaus-Michael (1998): Prototypisch starke und schwache Verben der deutschen Gegenwartssprache. In: Matthias Butt und Nanna Fuhrhop (Hgg.): Variation und Stabilität in der Wortstruktur: 45–60. (Germanistische Linguistik; 141/142). Hildesheim: Olms.
Lieberman, Erez, Jean-Baptiste Michel, Joe Jackson, Tina Tang und Martin Nowak (2007): Quantifying the evolutionary dynamics of German verbs. In: Nature 449: 713–716.
Liede, Alfred (1992a, b): Dichtung als Spiel. Studien zur Unsinnspoesie an den Grenzen der Sprache. Mit einem Nachtrag Parodie, ergänzender Auswahlbibliographie, Namenregister und einem Vorwort neu herausgegeben von Walter Pape. 2 Bde. Berlin, New York: Walter de Gruyter. 2. Aufl.
Nowak, Jessica (2013): spinnen – sponn? – gesponnen: Die Alternanz x-o-o als Alternative zum „Schwachwerden“. In: Jahrbuch für Germanistische Sprachgeschichte 4(1): 170–185.
Nübling, Damaris (1998): Wie die Alten sungen…: Zur Rolle von Frequenz und Allomorphie beim präteritalen Numerusausgleich im Frühneuhochdeutschen. In: Zeitschrift für Sprachwissenschaft 17(2): 185–203.
—(2001): The development of ‚junk‘. Irregularization strategies of have and say in the Germanic languages“. In: Geert Booij und Jap van Marle (Hgg.): Yearbook of Morphology 1999: 53–74. Dordrecht [u.a.]: Kluwer.
Reis, Marga (2017): Grammatische Variation und realistische Grammatik. In: Marek Konopka und Angelika Wöllstein (Hgg.): Grammatische Variation: Empirische Zugänge und theoretische Modellierung: 255–282. (Jahrbuch des Instituts für Deutsche Sprache [IDS]; 2016). Berlin, Boston: De Gruyter.
Valentin, Karl (1961): Karl Valentin’s Gesammelte Werke. Mit 28 Abbildungen. München: Piper.
Ich bin dieses Semester für den Morphologie-Teil der Einführung in die germanistische Linguistik an der LMU zuständig. Üblicherweise beginnt man hier mit einem Morphem-basierten Ansatz, um die Studierenden später an eine prozessbasierte (Item and Process), gegebenenfalls auch eine wortbasierte Sichtweise auf morphologische Phänomene heranzuführen.
Der Morphem-basierte Ansatz hat natürlich seine Vorzüge. Beispielsweise kann man hierarchische Baumstrukturen dazu nutzen, um die semantischen Verhältnisse bei Ambiguitäten in der Wortstruktur explizit zu beschreiben. So sind für das komplexe Adjektiv undoable die beiden Analysen in (1) möglich (Haspelmath und Sims 2010: 145). Man spricht in diesen Fällen davon, dass die Derivationsaffixe un- bzw. -able einen unterschiedlichen semantischen Geltungsbereich (Skopus) haben.
(1a) [un [do able] ,nicht machbar‘
(1b) [[un do] able] ,rückgängig zu machen‘
Baumdiagramme können auch genutzt werden, um semantische Ambiguitäten zu analysieren, die sich bei manchen Komposita ergeben (Haspelmath und Sims 2010: 143). Ein makabres Beispiel aus dem Deutschen findet sich bei Meibauer u.a. (2015: 35), nämlich Mädchenhandelsschule, für das wir die in Abbildung 1 angeführten Repräsentationen annehmen können.

Abbildung 1: Strukturbäume zu Mädchenhandelsschule
Der Preis, den man für Morpheme zahlt, ist Abstraktion: Sehr natürlich ergeben sich Nullallomorphe, also sozusagen unsichtbare Strukturen, und zwar sowohl in der Flexions- (2a) als auch der Wortbildungsmorphologie (2b, c).
(2a) Fenster [SG] – Fenster-∅ [PL]
(2b) lauf-en → der Lauf-∅
(2c) legal-ize : clean-∅
So hat Olsen (1990) eine Analyse von Konversionsprozessen mittels Nullaffix ausgearbeitet (3), die es ermöglicht, das in der Morphologie gut etablierte Kopf-Rechts-Prinzip aufrechtzuerhalten. Für dieses Nullaffix M könnte man sich den in Abbildung 2 angeführten Lexikoneintrag vorstellen.
(3a) Zelt → zelt-en
(3b) [V [N Zelt ] [M [+V] [+ schwach] ∅ ]]

Abbildung 2: Lexikoneintrag für das stumme Derivationsaffix M (nach Meibauer et al. 2015: 66)
Derzeit populäre Grammatikmodelle wie die Konstruktionsgrammatik bevorzugen demgegenüber einen oberflächenbezogenen Ansatz: „no underlying levels of syntax or any phonologically empty elements are posited“ (Goldberg 2003: 210). Als Konsequenz wird in der Konstruktionsmorphologie (Booij 2010) ein wortbasierter Ansatz vertreten.
An dieser Stelle ein Ceterum Censeo: Nullelemente sind ein alter Zankapfel in der Grammatiktheorie, und insbesondere die Generative Grammatik in ihren verschiedenen Ausformungen hat’s da mitunter übertrieben. Wir können uns, glaube ich, darauf verständigen, dass solche Elemente nicht leichtfertig angenommen werden sollten (Stichwort: Ockhams Rasiermesser), aber die Idee, dass wissenschaftliche Erklärungen nur „sichtbare“ Entitäten involvieren sollten, erscheint mir bizarr.
Es ist eine Binsenweisheit in der Wissenschaftstheorie, dass es keine Theorie-unabhängige Beobachtung gibt (Chalmers 1999: Kap. 1–2). Sogar basale Konzepte wie Phoneme, Morpheme, Wörter oder Phrasen setzen ein gehöriges Maß an Abstraktion voraus; und keinesfalls sind sie direkt beobachtbar. Die wichtigere Frage ist nicht die, ob Leerkategorien „existieren“, sondern ob sie uns erlauben, empirisch adäquatere Generalisierungen zu formulieren und interessante Vorhersagen zu machen (Haider 2018: 65–72). Eine sorfältige und ausgewogene Bewertung findet sich bei Müller (2020: Kap. 19) und insbesondere Gallmann (2020). Auf YouTube gibt es übrigens ein hervorragendes Video zu diesem Thema mit dem hübschen Titel Why linguists believe in invisible words – the story of zeros. Es gibt gute Gründe, einen morphem-basierten Ansatz zu verwerfen und stattdessen einen wortbasierten zu verfolgen. Im Zoo der Morphologie-Theorien und ihren Design-Prinzipien (Stump 2001: Ch. 1; Stewart 2016) kann man auswählen, was am besten zum analysierten Datenbereich passt und was die besten Vorhersagen ermöglicht. Sich aber lediglich zu sichtbarer (oder hörbarer) Morphologie zu bekennen, ist ein seltsamer Fall von linguistischer Orthodoxie.
Zurück zum Thema: Ein Datenbereich, bei dem ein Morphem-basierter, hierarchischer Ansatz schnell an seine Grenzen stößt, sind sogenannte Klammerparadoxe, und diese sind auch in einem wortbasierten Ansatz nicht gratis zu haben. Zwar ist man nicht gezwungen, die Annahme zu machen, dass morphologische Prozesse wie Affigierung informationserweiternd sind, d.h. die entsprechenden Exponenten zusätzliche Bedeutungen einbringen. Wenn aber, wie in der Konstruktionsmorphologie, Merkmalsstrukturen bzw. strukturierte Bedeutungen bestimmte Wortformen lizenzieren (inferentiell-realisierungsbasiert nach Stump 2001: 1–2), dann muss sozusagen das Pferd von der anderen (der funktionalen) Seite aufgezäumt werden, d.h. es ist zu spezifizieren, wie die entsprechenden morphologischen Funktionen zu ihrer Formseite kommen. Dies ist kein spezifisch funktionalen Problem, denn auch generative Modelle wie die HPSG und in diesem Rahmen entwickelte Morphologiekonzeptionen wie die Informationsbasierte Morphologie (Bonami 2016 und Crysmann 2016) sind mit diesem Problem konfrontiert.
Das klassische Beispiel für Klammerparadoxe sind Komparativformen von Adjektiven im Englischen (Pesetzky 1985: 196–197): Einsilbige (4a) und anfangsbetonte zweisilbige Adjektive (4b) können synthetisch gesteigert werden.
(4a) old – old-er
(4b) grumpy – grumpi-er
Mehrsilbige Adjektive müssen demgegenüber immer analytisch (d.h. mit den Steigerungspartikeln more/most) kompariert werden, siehe (5).
(5a) correct – more correct
(5b) restrictive – more restrictive
Aus morphologischen Gründen müsste die Klammerung (6a) vorliegen, denn mehrsilbige Adjektive dürfen nicht mit -er kompariert werden. Semantisch gesehen muss allerdings die Klammerung wie in (6b) sein, denn unhappier bedeutet ,in höherem Maße unglücklich‘, nicht aber: ,nicht glücklicher‘.
(6a) [A un [A happy er]]
(6b) [A [A un happy] er]
Klammerparadoxe finden sich auch im Deutschen (Lüdeling 2001: 104; Müller 2003: 278–279): Mit dem Zirkumfix Ge- … -e können pejorative deverbale Substantive abgeleitet werden. Eine Wortbildung wie Herumgerenne bedeutet ,wiederholte, ziellose Rennen-Ereignisse‘, d.h. semantisch gesehen ist eine Struktur wie (7b) plausibel. Die morphologisch plausible Klammerung ist indes (7a), jedoch liefert diese in Bezug auf die Semantik die falsche Deutung, nämlich ,ziellose, wiederholte Rennen-Ereignisse‘.
(7a) [herum [ge renne]]
(7b) [ge [herum renn] e]
Auch in der Flexionsmorphologie lassen sich relevante Beispiele finden. So ergibt sich die Bedeutung von aufhören nicht kompositional aus der Bedeutung des Verbstammes hör- und der Partikel auf (aufhören ist keine Form von hören). Semantisch gesehen sollte das Infinitivsuffix -en sich auf aufhör- als Ganzes beziehen (Abbildung 3: B); morphologisch betrachtet ist aber die Klammerung [P auf [V hör en]] plausibler (Abbildung 3: A), weil Partikelverben immer die Flexionsklasse ihres Basisverbs erben und somit direkten Zugriff auf die morphologischen Merkmale des Stammes benötigen.

Abbildung 3: Strukturbäume zu aufhören
Bei komplexen Flexionsformen verhalten sich Stamm plus Partikel wie eine (opake) semantische Einheit, die semantischen Informationen der beteiligten Affixe werden aber kompositional mit der Bedeutung von aufhör- verknüpft (z.B. auf-hör-t-est).
Seit längerem bekannt sind auch paradoxe Bezüge, die sich bei NN-Komposita mit modifizierendem Adjektiv ergeben (siehe Bergmann 1980 und zuletzt Maienborn 2020). Bei den Phrasen in (8) scheint es so, als ob sich das attributive Adjektiv semantisch gesehen auf das Erstglied eines nominalen Determinativkompositums, also dessen Nicht-Kopf, beziehe.
(8a) ambulanter Versorgungsauftrag
(8b) milliardenhoher Verlustbringer
(8c) alkoholfreie Getränkeindustrie
(8d) grüner Bohneneintopf
Mit (8a) ist nicht ein ,ambulanter Auftrag zur Versorgung‘ gemeint, sondern ein ,Auftrag zur ambulanten Versorgung‘, d.h. attributives Adjektiv und Nicht-Kopf des Kompositums sind semantisch aufeinander bezogen, wie dies (9a) verdeutlicht; somit wäre die lexikalische Integrität verletzt. Morphosyntaktisch gesehen kongruiert das attributive Adjektive allerdings mit dem Kopf des Kompositums, wie der Kontrast zwischen (9b) und (9c) zeigt.
(9a) [ambulanter Versorgungs]auftrag
(9b) * ambulante Versorgungsauftrag
(9c) ambulante Versorgung
Es ist nicht so, dass es an Lösungsansätzen zu Klammerparadoxien mangeln würde. Sie im Einzelnen zu referieren, ist mühsam und würde wohl dazu führen, dass man den Wald vor lauter – Wortwitz – Bäumen nicht mehr sieht. Fest steht jedenfalls, dass uns die übergreifende, zündende Idee fehlt und uns dieses Phänomen wohl noch einige Zeit beschäftigen wird.
Bergmann, Rolf (1980): Verregnete Feriengefahr und Deutsche Sprachwissenschaft. Zum Verhältnis von Substantivkompositum und Adjektivattribut. In: Sprachwissenschaft 5: 234–265.
Bonami, Olivier und Berthold Crysmann (2016): Morphology in Constraint-based Lexicalist Approaches to Grammar. In Andrew Hippisley und Gregory T. Stump (Hgg.): The Cambridge Handbook of Morphology: 609–656. (Cambridge Handbooks in Language and Linguistics). Cambridge: Cambridge University Press.
Booij, Geert (2010): Construction Morphology. Oxford: Oxford University Press.
Chalmers, Alan F. (1999): What is This Thing Called Science? Berkshire: Open University Press. 3. Aufl.
Gallmann, Peter (2020): Leere Kategorien. Vorlesungsskript, Universität Jena. URL: http://gallmann.uni-jena.de/Wort/Nullkat_C_Relativ.pdf [Stand: 12.12.22].
Goldberg, Adele E. (2003): Constructions: a new theoretical approach to language. In: Trends in Cognitive Sciences 7(5): 219–224.
Haider, Hubert. 2018: Grammatiktheorien im Vintage-Look – Viel Ideologie, wenig Ertrag. In: Angelika Wöllstein et al. (Hgg.): Grammatiktheorie und Empirie in der germanistischen Linguistik: 47–92. (Germanistische Sprachwissenschaft um 2020; 1). Berlin, Boston: De Gruyter.
Haspelmath, Martin und Andrea Sims (2010): Understanding Morphology. London: Hodder Education. 2. Aufl.
Lüdeling, Anke (2001): On Particle Verbs and Similar Constructions in German. (Dissertations in Linguistics). Stanford: CSLI Publications.
Maienborn, Claudia (2020): Wider die Klammerparadoxie: Kombinatorische Illusionen beim Adjektivbezug auf NN-Komposita. In: Zeitschrift für Sprachwissenschaft 39(2): 149–200.
Meibauer, Jörg, Ulrike Demske, Jochen Geilfuß-Wolfgang, Jürgen Pafel, Ramers Karl Heinz, Monika Rothweiler und Markus Steinbach (2015): Einführung in die germanistische Linguistik. Stuttgart [u.a.]: Metzler. 3. Aufl.
Müller, Stefan (2003): Solving the bracketing paradox: an analysis of the morphology of German particle verbs. In: Journal of Linguistics 39: 275–325.
–(2020): Grammatical Theory: From Transformational Grammar to Constraint-based Approaches. (Textbooks in Language Sciences; 1). Berlin: Language Science Press. URL: https://langsci-press.org/catalog/book/287 [Stand: 12.12.22].
Olsen, Susan (1990): Konversion als ein kombinatorischer Wortbildungsprozeß. In: Linguistische Berichte 127: 185–216.
Pesetzky, David (1985): Morphology and Logical Form. In: Linguistic Inquiry 16(2): 193–246.
Stewart, Thomas W. (2016): Contemporary Morphological Theories. A User’s Guide. Edinburgh: Edinburgh University Press.
Stump, Gregory T. (2001): Inflectional Morphology. A Theory of Paradigm Structure. Cambridge: Cambridge University Press.
Ich hoffe, Ihr wart auch alle schön brav. Heute ist Nikolaus. Der Morphologe in mir ist übrigens hocherfreut, dass es der Umlaut im Deutschen bis zu Pluralen wie Nikoläuse gebracht hat. Eine steile Karriere für ein Phänomen, das mal ganz klein (regressive Assimilation) angefangen hat!
Denjenigen unter Euch, die mit Nachwuchs gesegnet sind, empfehle ich eine tagesaktuelle Variante des Wug-Tests:
Das ist das Haus vom ein Nikolaus:

Quelle (CC BY 4.0)
Jetzt kommt da noch ein Nikolaus. Dann sind es zwei …
Update: Meine geschätzte Kollegin Lea Schäfer hat dankenswerterweise eine kleine Umfrage (via Fediverse) zu den Pluralformen von Nikolaus durchgeführt (s.u.). Zwei Punkte:

Eines meiner linguistischen Interessen, das Hubert Haider in mir geweckt hat, sind syntaktische Asymmetrien. Ein gleichermaßen einfaches wie tiefschürfendes Beispiel ist die Beobachtung, dass links- und rechtsköpfige Sprachen sich zwar in der Position von Kopf und Komplement unterscheiden, nicht jedoch in ihrer Verzweigungsstruktur. In der älteren (typologischen) Forschung ging man davon aus, dass dies nicht der Fall ist, d.h. beide Phrasentypen auch einen spiegelbildlichen Aufbau besitzen, wie dies in (1a) bzw. (1b) illustriert ist.
(1a) [[[[Kopf] …] …] …]
(1b) [… [… [… [Kopf]]]]
Seit Barss und Lasnik (1986) wissen wir, dass diese Annahme problematisch ist, denn sie macht u.a. falsche Vorhersagen über Bindungsverhältnisse in der NP: Bei einer linksverzweigenden NP-Struktur wie in (2a) würde das Reflexivum sich nicht von seiner Bezugs-NP c-kommandiert und Bindung wäre somit futsch. Bei einer rechtsverzweigenden Struktur wie (2b) bleibt noch immer die Frage, wie die Kopfposition der Phrase mit einer binär-verzweigenden Struktur kompatibel ist, aber die Bindungsverhältnisse werden korrekt erfasst.
(2a) Die [[Wut des Mannes_i] [auf sich_i]]
(2b) Die [Wut [des Mannes_i [… [auf sich_i]]]] (nach Haider 2013: 3)
Dieser Befund gilt insbesondere auch für die VP. Ausgehend von Larson (1988) bahnbrechendem Artikel hat Hubert die Idee einer Schalenstruktur in modifizierter und detaillierter Form ausgearbeitet. Die Grundidee ist, dass VO-Systeme (mit kopfinitialer VP) „komplexer“ sind, weil sie eine zusätzliche Kopfposition beinhalten, wie sie etwa bei ditransitiven Konstruktionen nötig ist. Man kann damit beispielsweise sehr elegant die klaren Unterschiede in der Distribution von Partikelverben erklären, die in der Germania zu beobachten sind (Haider 1997): In den germanischen OV-Sprachen (Deutsch, Niederländisch, Friesisch) ist die Partikel in Nicht-Verbzweit-Kontexten immer linksadjazent zum Stamm (3a), in den germanischen VO-Sprachen ist sie entweder rechts-adjazent oder rechts-distant. Sprachen wie Norwegisch, Englisch oder Isländisch erlauben beide der letztgenannten Muster, siehe (3b, c).
(3a) [VP den Zweig abschneiden]
(3b) [VP cut off the twig]
(3c) [VP cut the twig off]
Unter der weitgehend unkontroversen Annahme, dass die Partikeldistribution ein Reflex der verfügbaren V-Positionen ist, ergeben sich für eine VO-gestrickte VP zwei solcher Positionen (4a), in OV aber nur eine (4b). Muster wie (3b) umfassen Anhebung von Verb und Partikel (Pied-piping), während in (3c) die Partikel zurückgelassen wird und das Objekt angehoben wird. In ditransitiven Strukturen wie (5) ist die VP sozusagen voll aufgefaltet (Haider 2013: 15).
(4a) [VP [V’ V° … [V’ V° …]]]
(4b) [VP [V’ … V°]]
(5) Susan [VP [V’ V° poured [VP the man [V’ V° out a drink]]]]
Warum schreibe ich das alles? Eine morphologische Asymmetrie, die mich schon lange fasziniert, seitdem ich das erste Mal davon gehört habe (es muss 2013 oder 2014 gewesen sein), ist die sogenannte Suffixpräferenz, d.h. die Tendenz, dass Suffigierung sprachübergreifend viel häufiger auftritt als ihr Gegenstück, Präfigierung. Lange geisterte dieser Befund, von dem ich sozusagen per linguistischem Kaffeeklatsch wusste, durch die hinteren Winkel meines Hirns, bis ich mir einmal im Zusammenhang für ein Typologie-Seminar die Mühe machte herauszufinden, was wir darüber so wissen. Da wir’s heute viel, viel leichter haben als früher und uns insbesondere ein phänomenales Werkzeug wie der World Atlas of Language Structres zur Verfügung steht, ist das gar nicht so wenig.
Im einschlägigen Kapitel 26 und der darauf bezogenen Kartierung finden wir detailierte Informationen dazu. Es wurden insgesamt 10 Flexionskategorien auf die Richtung ihrer additiven Exponenz hin geprüft (u.a. Tempus/Aspekt-Affixe, Negationsaffixe am Verb, Pluralmarkierung am Substantiv usw.). Daraus ergibt sich der Präfigierungs-/Suffigierungs-Index, und zwar nach folgender Arithmetik:
Als Summe dieser Werte ergibt sich ein Affigierungsindex, der wiederum eine Bestimmung der Affigierungsrichtung ermöglicht: Sprachen, die vorwiegend suffigierend sind, haben einen Anteil von mindestens 80% Suffigierung am Affigierungsindex, bei schwach suffigierenden Sprachen liegt er zwischen 60% und 80% usw. Als untere Schwelle gibt es Sprachen, die wenig oder keine Flexionsmorphologie haben (Affigierungsindex < 2).
Die Zahlen sprechen für sich: Der Anteil dominant suffigierender Sprachen überwiegt den von dominant präfigierenden Sprachen bei weitem (6a); bei den schwächeren Typen ist das Gefälle indes deutlich flacher (6b). Wenn wir die Kategorien zusammenfassen und zusätzlich die Sprachen ohne Tendenz in der Affigierungsrichtung dazu nehmen, bekommen wir die Verhältnisse in (6c).
(6a) Strongly suffixing (406 Sprachen) > strongly prefixing (58 Sprachen)
(6b) Weakly suffixing (123) > weakly prefixing (94)
(6c) Suffixing (529) > prefixing (152) > equally prefixing/suffixing (147)
Unter mikrotypologischen Gesichtspunkten, d.h. mit Blick auf die deutsche (oder von mir aus kontinental-westgermanische) Dialektlandschaft, sollten sich keine allzu großen Unterschiede ergeben (aber wissen tu ich’s nicht): Bekannt ist der Verlust des Partizip-Präfixes ge- in vielen niederdeutschen Dialekten, wie er beispielsweise im Sprachatlas des deutschen Reichs dokumentiert ist (WA: Karte 120 [gelaufen]) oder die Abneigung des Bairischen (und anderer oberdeutscher Dialekte gegenüber be-Präfigierungen in der Wortbildung (Weiß 2017: 53–54). Aber diese Fälle drehen die Eskalationsschraube ja ohnehin Richtung Suffix-Präferenz.
Zurück zur Großtypologie: Im Wals gibt es das nice Feature (excuse my Denglisch), dass man Kombinationskarten erstellen kann. So können wir beispielsweise den schon von Greenberg (1963: 73) postulierten Zusammenhang zwischen Adpositionen und Affigierungsrichtung betrachten.
Universal 27: If a language is exclusively suffixing, it is postpositional; if it is exclusively prefixing, it is prepositional.
Die entsprechende Kombinationskarte liefert uns die in Tabelle 1–2 angeführten Zusammenhänge. Tendenziell ist Greenbergs Aussage korrekt, d.h. bei Sprachen mit Suffigierung überwiegen Postpositionen (214 bzw. 50), bei präfigierenden Sprachen Präpositionen (40 bzw. 43). Bei Sprachen mit wenig Affigierung überwiegen Präpositionen gegenüber Postpositionen (90/37); bei Sprachen, die Suffigierung und Präfigierung gleichermaßen einsetzen, gibt es keine deutliche Tendenz für einen Adpositionstyp (61 mit Präpositionen, 52 mit Postpositionen).
 ALT
ALTTabelle 1: Korrelation zwischen Adpositionstyp und Suffigierung
 ALT
ALTTabelle 2: Korrelation zwischen Adpositionstyp und Präfigierung
Ein weiterer Aspekt, der sich unmittelbar aufdrängt, ist der Zusammenhang zwischen Affigierungsrichtung und Grundwortstellung; die entsprechende Kombinationskarte findet sich hier. In Tabelle 3 ist dies zusammengefasst als Wert starke/schwache Präfigierung/Suffigierung und SVO vs. SOV, d.h. ich erlaube mir, etwas Komplexität rauszunehmen. Wir sehen eine deutliche Korrelation zwischen Suffigierung und SOV und einen deutlich höheren Anteil bei Präfigierung in SVO, auch wenn bei diesem Stellungstyp die Suffigierung ebenfalls überwiegt.
 ALT
ALTTabelle 3: Affigierungsrichtung ∼ Basiswortstellung
Ein Datenbereich, wo ich mir eine deutliche Asymmetrie erwarte, ist in Bezug auf die Affix-Abfolge. Bybees (1985) Relevanzprinzip besagt, dass morphologische Kategorien, die die Semantik des Konzepts, das der Basis zugrunde liegt, stärker beeinflussen, auch näher dazu stehen. Wir haben es also mit einer Spielart von diagrammatischem Ikonismus zu tun, ein funktionales Erklärungsmotiv, das sich als sehr leistungsfähig und vor allem unter Sprachverarbeitungs-Gesichtspunkten als valide erwiesen hat (siehe dazu Newmeyer 1998: 114–118, 129–130). Für die Verbalflexion bekommen wir die in (7) angeführte Relevanzhierarchie (Bybee 1985: 34–35), die beispielsweise besagt, dass Tempus- und Aspekt-Affixe deutlich näher am Stamm stehen bzw. sogar über fusionale Exponenz in diesen verlagert werden, während Person und Numerus demgegenüber weniger relevant und peripherer sind.
(7) Verbstamm < Aspekt < Tempus < Modus < Numerus < Person
Die Begründung liegt darin, dass Tempus und Aspekt die zeitliche und interne Kohärenz einer Situation modifizieren, während Person und Numerus lediglich etwas über die an dieser Situation beteiligten Aktanten aussagen (siehe die Diskussion bei Bybee 1985: 20–24).
Das Relevanzprinzip macht auch mit Blick auf Sprachwandel-Prozesse interessante Vorhersagen, die sich, wenn wir einmal bei den germanischen Sprachen bleiben, unmittelbar validieren lassen. So haben die skandinavischen Sprachen Person und Numerus in großen Teilen der Verbflexion weitgehend abgebaut, während Tempus nach wie vor robust ausgedrückt wird: So haben wir beispielsweise im Norwegischen, wie in (8) illustriert, nur noch einen Tempuskontrast zwischen Präsens und Präteritum bzw. Partizip Präteritum (Askedal 2005: 1597). Englisch stellt quasi eine Zwischenstufe dar, denn dort ist lediglich die 3SG per additiver Exponenz markiert (-s). Im Standarddeutschen treten Person und Numerus mit Ach und Krach noch in Erscheinung (wenngleich mit Synkretismus), aber sobald wir in die Dialekte gehen, finden wir größerflächig auch Einheitspluralformen (König et al. 2019: 128), d.h. Person wird im Plural nicht mehr ausgedrückt: in (9) ist jeweils ein einschlägiges Beispiel aus dem Niederdeutschen und dem Westoberdeutschen angeführt (übernommen aus Roelcke 2011: 117).
(8) kasta ,werfen‘ (INF) – kastar (PRES) – kasta (PRET/PTCP)
(9a) mir machet – ihr machet – sie machet (Schwäbisch)
(9b) wi maaket – ji maaket – se maaket (Niedersächsisch)
Bybee geht nicht ausführlicher auf diesen Aspekt ein, aber eine Vorhersage des Relevanzprinzips ist die, dass bei Präfigierung die Affix-Reihenfolge spiegelbildlich zu der bei Suffigierung sein sollte, d.h. die einzelnen Affixe lagern sich quasi zwiebelschalenartig um den Verbstamm (10). Ich kenne keine Untersuchung, die sich dieser Frage widmet und bin sehr dankbar für entsprechende Hinweise.
(10) … Modus > Tempus > Aspekt > Verbstamm
Meine Vermutung ist die, dass es durchaus Asymmetrien geben muss, denn in diesem Fall gibt es einen Mismatch zwischen Verarbeitungsrichtung und diagrammatischem Ikonismus. Mit engerem Blick auf einzelne morphologische Kategorien sind morphologische Asymmetrien durchaus zu finden, so zeigen etwa Kasusaffixe eine besonder starke Suffixpräferenz, wie die entsprechende Kartierung im Wals erkennen lässt (Wals, Kap. 51 und Karte 51A).
Was ist die Erklärung für diese Asymmetrie? Aus einer psycholinguistischen Perspektive ist erwogen worden, dass exzessive Präfigierung einen Verarbeitungsnachteil mit sich bringt, indem der entsprechende Stamm bei der inkrementellen Verarbeitung später zugänglich ist als bei Suffigierung. Dies unter der Annahme, dass Stämme und Affixe getrennt voneinander verarbeitet werden und Wortanfänge salienter als andere Wortbestandteile sind (Cutler et al. 1985). Das Problem ist hierbei, dass entsprechende Befunde beinahe ausschließlich auf dem Englischen basieren, das eindeutig suffix-prominent ist. Eine brandaktuelle Studie zu Kîîtharaka, einer in Kenia gesprochenen Bantu-Sprache, die eine stark präfigierende Flexionsmorphologie aufweist, lässt Zweifel an der Valdität dieser Parsing-basierten Erklärung aufkommen. Martin und Culbertson (2020) haben mittels eines ausgefeilten Studiendesigns nachgewiesen, dass Sprecher/innen dieser Sprache die Ähnlichkeit oder Unähnlichkeit von Wortformen präferiert vom Wortende aus beurteilen (siehe unten). Dabei kamen sowohl sprachliche Stimuli in Form von Silbenfolgen als auch Anordnungen geometrischer Objekte zur Anwendung.
Welche Lautfolge ist ähnlicher zu tako?
(a) motako
(b) takomo
Dass sich auch bei der letzteren Klasse von Stimuli gleichgerichtete Präferenzen ergaben, deutet darauf hin, dass die Linkspräferenz bei dieser Sprechergruppe eine domänenübergreifende Dimension hat.
Das bemerkenswerte Fazit:
“(…) our results suggest that no universal preceptual preference for suffixes over prefixes exists. (…) Experience with a suffixating language such as English leads to perception of beginnings as most salient for determining similarity, whereas experience with a prefixing language such as Kîîtharaka leads ending to be more salient.” (Martin und Culbertson 2020: 1114)
Wenn eine Parsing-basierte Erklärung für die Suffixpräferenz mit Problemen konfrontiert ist, was ist dann die Alternative? Eine offensichtliche Antwort ist die Diachronie, und dies ist eine Perspektive, die von Bybee et al. (1990) verfolgt wird, übrigens einer der substanziellsten Beiträge zur Affix-Problematik, den ich kenne.
Ausgehend von einer ausgewogenen Stichprobe von 71 Sprachen betrachten sie neben der Affix-Position relativ zum Stamm auch die Abfolge freier Morpheme, die in einer Selektions- oder Modifikationsbeziehung zueinander stehen (z.B. Auxiliar – Vollverb), d.h. die relative Position ihrer potentiellen Spender. Hintergrund ist die Annahme, dass für letztere deutliche Sollbruchstellen zwischen Sprachen mit unterschiedlicher Grundwortstellung auszumachen sind (das ist hinlänglich bekannt, siehe z.B. Dryer 1992) und dass Morphologie auffällig oft „gefrorene Syntax“ repräsentiert. Man denke an Givóns (1971) bekannten Slogan „Today’s morphology is yesterday’s syntax“. Bei den drei grundlegenden Stellungstypen final (SOV), medial (SVO) und initial (VOS, VSO) zeigen sich wiederum auffällige Korrelationen (Bybee et al. 1990: 5–7):
Morheme an peripheren Positionen in der Satzstruktur werden häufiger zu Affixen verwurstet, während bei internen Morphemen (… M-V-M …) die Bedeutung und insbesondere ihre Relevanz der entscheidende Faktor sind: Am häufigsten treten Valenz/Diathesen-Morpheme auf, gefolgt von Aspekt und Tempus (Bybee et al. 1990: 31). Mit anderen Worten (ebd.):
“In V-medial languages, the most highly relevant grams [freie und gebundene Morpheme; O.S.] will more readily become affixes that is, be entered in the lexicon as part of the verb, than will the less relevant ones.”
Sehr anregend finde ich auch die Diskussion zu phonologischen Einflussfaktoren (Bybee et al. 1990: 19–27), die auch eine eingehendere Betrachtung im Kleinen, also in der hiesigen Dialektlandschaft, lohnen würde:
Wir sehen also:
Gebundene Morpheme zeigen eine auffällige Asymmetrie in ihrer Auftretensfrequenz, die sich aus einem komplexen Wechselspiel zwischen Diachronie und Typologie ergibt.
Liebgewonnene Verarbeitungs-bezogene Erklärungen (Cutler et al. 1985) sind weniger leistungsfähig als erhofft, da ihre Datenbasis alles andere als repräsentativ ist (Stichwort: Euro- bzw. Englisch-Zentrismus). Ob sich bei eingehenderer Betrachtung die Zwiebelschalen-Vorhersage der Relevanztheorie bestätigen lässt, bleibt offen. Grundsätzlich ist es wohl aber so, dass komplexe Präfixketten weniger Chancen haben, grammatikalisiert zu werden als ihr Spiegelbild.
Ich möchte mit einer weiteren bemerkenswerten morphologischen Asymmetrie schließen, die sich bei Komposita beobachten lässt (Haider 2013: Kap. 8). Zwar besteht für die meisten Sprachen mit Komposita das bekannte Kopf-rechts-Prinzip, d.h. der morphologische (und oft gleichzeitig semantische) Kopf steht bei entsprechenden Worbildungen rechts (siehe dazu grundlegend Williams 1981). Linksköpfige Komposita gibt es ebenfalls, am bekanntesten sind sie wohl in den romanischen Sprachen. Während es aber sehr komplexe rechtsköpfige Komposita gibt, scheinen komplexe linksassoziative Strukturen sprachübergreifend ausgeschlossen zu sein (Beispiele aus Delfitto et al. 2008; zit nach Haider 2013: 192). Das bedeutet, dass es zwar einfache linksköpfige Komposita gibt (11a), aber diese nicht iteriert werden können (11b).
(11a) pesce zebra ,Zebrafisch‘, pesce spada ,Schwertfisch‘
(11b) *pesce zebra spada ,Schwertzebrafisch‘
By the way: Es ist ein linguistischer Mythos, dass nur das Deutsche Komposita-Ungetüme kennt – ungewöhnlich ist nur die orthographische Konvention, sie zusammenzuschreiben. Wie Gereon Müller in einem populärwissenschaftlichen Vortrag hinweist, lassen sich auch im Englischen Würste wie high voltage electricity grid systems supervisor ,Hochspannungsnetzüberwachungsmeister‘ (oder ähnlich) finden.
Askedal, Jon Ole (2005): The standard languages and their
systems in the 20th centry III: Norwegian. In: Oskar Bandle et al. (Hgg.): The Nordic Languages. An International Handbook of the History of the North Germanic Languages, Bd. 2: 1584–1602. (Handbücher zur Sprach- und Kommunikationswissenschaft; 22). Berlin, New York: de Gruyter.
Barss, Andrew und Howard Lasnik (1986): A Note on Anaphora and Double Objects. In: Linguistic Inquiry 17(2): 347–354).
Bybee, Joan L. (1985): Morphology: a study of the relation between meaning and form. (Typological studies in language; 9). Amsterdam: Benjamins.
Bybee, Joan L., Willian Pagliuca und Revere D. Perkins (1990): On the Asymmetries in the Affixation of Grammatical Material. In: William Croft, Keith Denning und Suzanne Kemmer (Hgg.): Studies in Typology and Diachrony: Papers Presented to Joseph H. Greenberg on his 75th Birthday: 1-42. (Typological Studies in Language; 20). Amsterdam: John Benjamins.
Cutler, Anne, John Hawkins und Gary Gilligan (1985): The suffixing preference: a processing explanation. In: Linguistics 23: 723–758.
Delfitto, Denis, Antonio Fábregas und Chiara Melloni (2008): Compounding at the Interfaces. Unpubliziertes Manuskript, Universitäten Verona und Tromsö.
Dryer, Matthew S. (1992): The Greenbergian Word Order Correlations. In: Language 68(1): 81–138.
Givón, Thomas (1971): Historical syntax and synchronic morphology: an archeologist’s field trip. In: Papers from the Regional Meeting of the Chicago Linguistic Society 7: 394–415.
Greenberg, Joseph H. (1963): Some Universals of Grammar with Particular Reference to the Order of Meaningful Elements. In [ders.] (Hg.): Universals of Human Language: 73–113. Cambridge (Mass.): MIT Press
Haider, Hubert (1997): Precedence among Predicates. In: The Journal of Comparative Germanic Linguistics 1: 3–41.
—(2013): Symmetry Breaking in Syntax (Cambridge Studies in Linguistics; 136). Cambridge: Cambridge University Press.
König, Werner, Stephan Elspaß & Robert Möller. 2019. dtv-Atlas Deutsche Sprache. 19th edn. München: Deutscher Taschenbuch Verlag.
Larson, Richard K. (1988): On the Double Object Construction. In: Linguistic Inquiry 19(3): 335–391.
Martin, Alexander und Jennifer Culbertson (2020): Revisiting the Suffixing Preference: Native-Language Affixation Patterns Influence Perception of Sequences. In: Psychological Science 31(9): 1107–1116.
Newmeyer, Frederick J. (1998): Language form and language function (Language, speech, and communication). Cambridge (Mass.): MIT Press.
Roelcke, Thorsten (2011): Typologische Variation im Deutschen: Grundlagen – Modelle – Tendenzen. Berlin: Erich Schmidt Verlag.
Weiß, Helmut (2017): Warum gibt es (im Bairischen) keine kochenden Hausfrauen, sondern nur kochendes Wasser? Über seltsame Lücken und Beschränkungen. In: Sonja Zeman, Martina Werner und Benjamin Meisnitzer (Hgg.): Im Spiegel der Grammatik. Beiträge zur Theorie sprachlicher Kategorisierung: 53–67. (Stauffenburg Linguistik; 95). Tübingen: Stauffenburg.
Williams, Edwin (1981): On the notions „Lexically Related“ and „Head of a Word“. Linguistic Inquiry 12: 245–274.
Beim Lesen von Andrea Sims’ Buch über Inflectional Defectiveness ist mir bewusst geworden, dass es im Alemannischen eine bemerkenswerte morphologische Lücke gibt: Bei verbalen Diminutiven wie möölala ,malen, kritzeln‘ usw. gibt es keine 1SG und auch keinen IMP.SG. Ich habe dazu ein Squib verfasst, das über LingBuzz zugänglich ist. Ich beschreibe dort die Datenlage im Vorarlberger Alemannischen, wie ich es spreche. Die empirische Unterfütterung ist noch nicht soo groß, ich muss noch weitere Sprecher und Sprecherinnen befragen, aber in den Weihnachtsferien wird’s hoffentlich Gelegenheit dazu geben. An alle Mannen und Frouwen da draußen, die Westoberdeutsch ihre Muttersprache nennen: Wie sieht’s in Euerem Idiom aus? Würde mich sehr interessieren!
Winter is coming und die kurz und kürzer werdenden Tage lassen sich nutzen, wieder einen Blog-Artikel rauszuhauen. Schon länger treibt mich die Frage um, wie wir linguistische (oder, etwas weniger hoch gegriffen: dialektologische) Forschung auf transparentere Weise durchführen können. Die betrifft nicht nur die möglichst barrierefreie Publikation der Ergebnisse (Stichwort: Open Access), sondern auch die Zugänglichkeit der zugrundeliegenden Daten.
Als persönlichen Testlauf möchte ich eine kleine Fallstudie zur Verfügung stellen, die ich in den letzten Monaten durchgeführt habe. Sie betrifft die Modalverb-Eigenschaften von brauchen. Dieses Phänomen ist sehr gut geeignet für ein solches Unterfangen, da wir direkte Referenzpunkte haben, um die erhobenen Daten auf ihre Validität, insbesondere aber auch ihre Reliabilität hin abzuklopfen.
Also, worum geht’s genau? Ich habe zwei Korpusuntersuchungen zur Infinitivrektion sowie zur 3SG durchgeführt. Wie schon seit längerem bekannt, nähert sich brauchen flexionsmorphologisch mehr und mehr dem Paradigma der Modalverben an, erkennbar u.a. an der variablen Rektion eines zu- oder Nullinfinitivs, Formen der 3SG ohne finales -t, analogischem (nicht-lautgesetzlichem) Umlaut im Konjunktiv 2 oder dem Ersatzinfinitiv. Bei den meisten dieser Eigenschaften zeigen sich deutliche areale Unterschiede in der Verbreitung der relevanten Varianten, was man als Indiz für die geschichtete Diffusion von sprachlichen Neuerungen deuten kann (Layering). Grundlage meiner Auswertungen ist das Zwirner-Korpus, das über die Datenbank Gesprochenes Deutsch verfügbar ist. Alle Daten und die für die Auswertung/Kartierung verwendeten R-Skripte sind als GitHub-Repositorium zugänglich, die Vorgangsweise und Ergebnisse sind dort dokumeniert. Ursprünglich wollte ich das Zeug für einen Artikel verwurschten, letztlich zeigte sich aber, dass das dort zu weit geführt hätte, und bevor das Zeug auf meiner Festplatte rumfermentiert, stelle ich es zur allgemeinen Verfügung. Wer Fehler findet oder programmiertechnisch etwas beizusteuern hat, ist herzlich dazu eingeladen, dies zu tun. Vielleicht ist dieser Datensatz auch für Lehrzwecke ganz nützlich, denn er zeigt den großen Nutzen, den das Zwirner-Korpus auch für morphologische bzw. morphosyntaktische Fragestellungen aufweist.
Ja, dieser Blog ist über Linguistik. Am 3. Mai hatte Otto Behaghel Geburtstag, stolze 162 Lenze würde er inzwischen zählen. Also kein runder Geburtstag, keine Primzahl oder sonstwas. Da der Konsonantenstadel nicht den Ereignissen hinterher hinkt, sondern über ihnen steht, folgt jetzt (erst) ein Artikel über ihn – mit leichten Gonzoelementen und einer Portion Linguistik.
Am vergangenen Wochenende machte ich mich mit meinem bezaubernden Kollegen (und baldigem Koautoren) Carsten Becker auf nach Gießen (by the way: „nach Gießen auf“ klingt in diesem Zusammenhang irgendwie markiert), um dem Altmeister zu huldigen. Bei dieser Pilgerfahrt ist die Idee geboren worden, Gräber von berühmten Linguisten zu besuchen und peu à peu ein einschlägiges Fotoarchiv anzulegen; quasi LingPhot für Verblichene – und mit Gräbern. Der Österreicher in mir ist morbid genug, dies erbaulich zu finden, der Deutsche in mir gründlich genug, die Aktion auch tatsächlich durchzuführen. Komische Assoziation, aber mir kommt dazu sofort ein Helmut Qualtinger zugeschriebenes Zitat in den Sinn, der über seine Heimatstadt Folgendes geäußert haben soll: „In Wien mußt’ erst sterben, damit sie dich hochleben lassen. Aber dann lebst’ lang.“ Hoffentlich gilt das nicht für Gießen (oder gleichgar die Linguistik).
Behaghel liegt am Neuen Friedhof jener Stadt begraben, in der er auch als Professor für Deutsche Philologie die größten Teile seiner akademischen Karriere verbracht hat und von wo aus er 1936 in die ewigen linguistischen Jagdgründe (aka die ewigen topologischen Felder) eingegangen ist. Ich möchte mich nicht weiter mit seiner Biographie aufhalten, dazu kann man an einschlägiger Stelle genug lesen – gelegentlich auch Widersprüchliches, denn so vermerkt etwas die Deutsche Biographie, er sei in München gestorben, während ihn (die Uni) Gießen vollständig für sich beansprucht (vgl. das Porträt auf dem dortigen Webangebot). Ich kann dazu nur mit einem bekannten Mem Stellung nehmen: „Gießen kills slowly.“

Der Autor dieses Blogs huldigt dem Altmeister
Man tritt dem Guten sicher nicht zu nahe, wenn man ihm attestiert, dass seine Hauptinteressen im Bereich der Syntax lagen. Dass Behaghel sich intensiv mit Sprachgeschichte beschäftigte, war kein Alleinstellungsmerkmal, sondern entsprach dem Geist der Zeit – nur wenige haben es aber so meisterhaft getan wie er. Früh erkannte er auch die Bedeutung der Gegenwartssprache und insbesondere der Dialekte für die Erhellung und Klärung diachroner Entwicklungen (so der ungefähre Wortlaut in der Deutschen Biographie). Vor diesem Hintergrund überrascht es auch nicht, dass sein Schüler Friedrich Maurer (von dem die oben zitierte Skizze stammt) in seinen Untersuchungen über die deutsche Verbstellung in ihrer geschichtlichen Entwicklung (1926) auch ausführlich auf die Verhältnisse in den damals rezenten Dialekten eingeht. Mehr zu Maurer – übrigens eine ideologisch höchst zweifelhafte Figur – an anderer Stelle.
Dass Behaghel im Dunstkreis der sogenannten Junggrammatiker steht (siehe dazu grundlegend Einhauser 2001: 1339), zeigt sich wohl nicht zuletzt an seinen „Gesetzen“, die vom Deutschen ausgehend sprachübergreifende Wortstellungsregeln erfassen sollten und denen wir (also pluralis majestatis) uns hier ausführlich widmen wollen. Behaghels „Hauptwerk“ ist seine vierbändige Deutsche Syntax – eine geschichtliche Darstellung, die zwischen 1923 und 1932 erschienen ist; dieses opus magnum ist von der UB Gießen digitalisiert worden und online verfügbar. Ich sage meinen Studis immer, dass es so viele tolle Dinge gibt, die man sich LEGAL runterladen kann:
Was die Anlage der Deutschen Syntax anlangt, ist man schnell wieder beim Hashtag „Jungrammatiker“ und ihrem grundsätzlich historischem Ansatz, der später auch durch eine deutliche Aufwertung der Gegenwartssprache gekennzeichnet sei (siehe u.a. Einhauser 2001: 1348). In diesem Sinn kann man auch das folgende Zitat aus dem Vorwort des letzten Bandes der Deutschen Syntax verstehen:
Mein Buch will eine deutsche Syntax im engeren Sinne des Wortes sein; seine Quellen sind also grundsätzlich alle Äußerungen in deutscher Sprache, vom 8. Jahrhundert herab bis auf die lebendige Rede der Gegenwart, wobei allerdings Erscheinungen der Mundarten nur gelegentlich berücksichtigt werden. Und ich suche in streng geschichtlichem Verfahren die Erscheinungen zu verfolgen von ihrem frühesten Zustand bis zur neuesten Zeit.
(Behaghel 1923: X)

Auch heute noch ist am Grabmal von Otto Behaghel mit Paparazzi-Attacken zu rechnen.
Auch in methodologischer Hinsicht gab Behaghel im Zusammenhang mit seinem sogenannten Stichprobenverfahren wichtige Impulse, wenngleich man sich aus heutiger Perspektive einig ist, dass man für ein linguistisch informiertes Bild gerade auch Daten zu den quantitativen Verhältnissen benötigt:
Bei diesen Untersuchungen habe ich das Verfahren beobachtet, das sich mir bei meiner Arbeit über die Zeitfolge bewährt hat, das Verfahren der Stichproben, das gewisse Stücke gewisser Denkmäler vollständig auszubeuten sucht. Wer danach andere Stücke und andere Quellen durchmustert, wird vielleicht wertvolle Ergänzungen bieten können, aber das von mir Gefundene kaum gänzlich umwerfen.
(Behaghel 1923: VIII)
Ein moderner Fortsetzer dieses Prinzips sind die „30 Normalseiten“, die für die Anlage des Bonner Frühneuhochdeutschkorpus und sein Schwesterprojekt, das Mittelhochdeutsche Referenzkorpus als Leitseil dienten (siehe z.B. Wegera 2000). Leider reicht diese Textmenge für bestimmte Belange nicht (wie man – ein Selbstzitat pro Blogeintrag sei mir erlaubt – auch in Fleischer & Schallert 2011: Kap. 5.2 nachlesen kann), so dass man sich nicht davor scheuen sollte, bestimmte Quellen einfach „vollständig ausbeuten“, sei es auf elektronischem Wege (wenn möglich) oder zur Not auch „zu Fuß“. In einem Schachtelsatz: Qualitative Evidenz ist ein wichtiges und unverzichtbares Mittel, um sich überhaupt in der Materialfülle orientieren zu können, welche die Sprachgeschichte bereithält, je weiter man in ihr Richtung Gegenwart hinaufsteigt. Aber wichtig sind halt auch quantitative Aspekte – ça veut dire: Was ist häufig? Was ist idiosynkratisch? Wie verschieben sich die Gewichte zwischen verschiedenen Konstruktionsmustern und wie interagieren sie miteinander?
Aber nun zum Kern der Sache: Wofür Behaghel heute auch außerhalb der Germanistik bekannt ist, sind die nach ihm benannten „Gesetze“. Anhand des Deutschen formulierte er die folgenden fünf Wortstellungsregeln, die sprachübergreifende Gültigkeit für sich beanspruchen (vgl. dazu Behaghel 1909, 1930a, b und vor allem Behaghel 1932, § 1426):
Das bekannteste der fünf Gesetze ist sicherlich die Nummer vier, also die titelgebenden wachsenden Glieder [WG]. Wären wir mit dem Zug nach Gießen gefahren, hätten wir uns an Sätzen wie dem Folgenden ergötzen können:
Auf Gleis 3 fährt ein [NP der IC 2270 Schwarzwald von Konstanz nach Stralsund].
Ich hatte mir kurz überlegt, einfach aus didaktischen Gründen zu schreiben, wir seien mit dem Zug gefahren (CO2-Bilanz und all das), aber beim Thema Eisenbahn sind schon ganz andere Schreiberlinge ins Schleudern gekommen. Aber nun ein Kommentar zum Bahnsatz: Wie der Kontrast zwischen diesem Beispiel und den beiden hier angeführten Wortspenden zeigt, können im heutigen Deutschen Präpositionalphrasen im Gegensatz zu Nominalphrasen im Nachfeld auftreten. Letztere können nur dann im Nachfeld stehen, wenn sie besonders umfangreich („schwer“) sind.
Ich hab geträumt [PP von dir]. (Matthias Reim)
*Niemand wird bezweifeln [NP sein Alibi].
Schwere-Effekte sind in zahlreichen Sprachen zu finden, u.a. auch im Englischen:
The prosecution showed [pictures of gruesome details of the victim’s wounds] [to the jury].
The prosecution showed [to the jury] [pictures of gruesome details of the victim’s wounds].
(Wasow 1997: 83)
Wodurch solche Effekte genau bedingt sind (Konstituenten-Länge, syntaktische Komplexität im Sinne der Zahl der Verzweigungen usw.), ist nicht einfach zu beantworten und Gegenstand psycholinguistischer Forschung (siehe dazu grundlegend Wasow 1997: 84–87). Man kann, glaube ich, mit einigem Recht sagen, dass Behaghel einer der Pioniere im Bereich parsingbasierter Erklärungen für Wortstellungsvariation war. So sieht John Hawkins (1994: 119) das von ihm formulierte Verarbeitungsprinzip Early Immediate Constituents (EIC) als Synthese bzw. Verallgemeinerung der ersten beiden Behaghelschen Gesetze. Vereinfacht besagt dieses Prinzip, dass der menschliche Parser Strukturen bevorzugt, die eine möglichst schnelle Identifikation der unmittelbaren Konstituenten eines gegebenen Mutterknotens ermöglichen (siehe dazu Hawkins 1994: 69–83). Zur Illustration ein Beispielpaar aus Hawkins’ aktueller Monographie:
[A] The man [VP looked_1 [PP1 for_2 his_3 son_4] [PP2 in_5 the dark and quite derelict building]].
[B] The man [VP looked_1 [PP2 in_2 the_3 dark_4 and_5 quite_6 derelict_7 building_8] [PP1 for his son_9]].
(Hawkins 2014: 12)
Während in [A] lediglich fünf Wörter abgefrühstückt werden müssen, um die drei unmittelbaren Konstituenten V, PP1 und PP2 zu postulieren, sind es in [B] ihrer 9 (!). Man sieht also – Behaghel ist aktueller denn je.
Besonders in den ersten beiden Gesetzen wird man umschwer Bezüge zu dem erkennen, was heute im Zusammenhang mit informationsstrukturellen Kategorien wie Thema/Rhema (heute oft nur noch „givenness“) oder Topik/Kommentar quasi zum grammatiktheoretischen Einmaleins gehört. Selbstverständlich möchte ich hier nicht die Verdienste der Prager Funktionalisten (Daneš, Firbas, Beneš usw.) kleinreden, denen wir letztlich auch die ganze Terminologie verdanken, aber Behaghel kann man als Indiz nehmen, dass einiges davon sozusagen schon in der Luft lag. Aber auch Gesetz Nummero fünf [TG] hat sowohl Tradition als auch Nachwirkung: Schon vor Behaghel formulierte Ries (1907) ein vergleichbares euphonisches Prinzip, das folgendermaßen lautet (siehe dazu Speyer 2010: 55):
[…] rhythmischer Wohllaut eines Satzes kann weder durch unvermittelte Nebeneinanderstellung mehrerer starkbetonter Worte erzeugt werden, noch verträgt er sich mit der Zusammenhäufung vieler unbetonter, er beruht vielmehr in erster Linie auf der Abwechslung (Ries 1907: 91–92).
In der neueren Forschung wird dieses Prinzip wieder aufgenommen und präziser formuliert, z.B. im Zusammenhang mit dem Clash Avoidance Requirement (Speyer 2010).
Wieviel haben wir von was?
[A] /ÄPfel haben wir \drEI. Und /ORANgen \FÜNF.
[B] # Wir haben /DREI \ÄPfel und /FÜNF \ORANgen
(nach Speyer 2010: 126, Bsp. 40)
Kommentar dazu: Unter Fokussierung versteht man die intonatorische Hervorhebung von Phrasen- bzw. Phrasenteilen gegenüber kontextuell verfügbaren Alternativen (oben markiert mit Großbuchstaben). Interessanterweise gibt es bei Sätzen mit zwei Foki die deutliche Tendenz, die jeweiligen Fokusexponenten nicht unmittelbar nebeneinander stehen zu lassen, d.h. [B] klingt gegenüber [A] markiert.
Behaghel hat an verschiedener Stelle darauf hingewiesen, dass diese einzelnen Gesetze miteinander wechselwirken (z.B. 1930b: 32). Einerseits können sie jeweils „zusammenwirken in derselben Richtung“, mitunter „aber auch sich entgegenarbeiten“ (Behaghel 1932: 5). Wer in diesen Äußerungen optimalitätstheoretisches Gedankengut avant la lettre zu erkennen glaubt, liegt sicher nicht ganz daneben und hat sich einen „pointing finger“ (☞) verdient. Als Beispiel für einen Konflikt zwischen [GEZ] und [WSU] nennt der Grammatiker neben der bekannten Spaltung von Pronominaladverbien (da kann ich nichts mit anfangen) insbesondere Pronomina in der sogenannten Wackernagelposition. Einerseits repräsentieren sie alte Information, haben also eine „enge geistige Beziehung zum Vorhergehenden“, andererseits sind sie, wie im Falle von (inhärenten) Reflexiva auch eng mit dem Verb verbunden:
[A] Er hatte sich jetzt mit dem größten Heerführer seiner Zeit gemessen (Schiller)
[B] Er kann durch die Kraft seines Willens aus dem Zustande der Bedrückung sich reißen (Schiller)
Kommentar dazu: In [A] ist [GEZ] verletzt (sich gehört zum Verb), aber [WSU] erfüllt; in [B] sind die Verhältnisse genau umgekehrt. In diesem Zusammenhang ein kleiner Ausflug in die Stilistik: Der bekannte Philosoph Theodor W. Adorno (1903–1969) hatte die Eigenart, Reflexivpronomen tief im Mittelfeld zu platzieren, d.h. er fühlte sich wohl stärker dem [GEZ] verpflichtet. Hier ein einschlägiges Beispiel: „Die fast unlösbare Aufgabe besteht darin, weder von der Macht der anderen, noch von der eigenen Ohnmacht sich dumm machen zu lassen.“ (Adorno 1994: 67)
Ein Konflikt zwischen [WG] und [GEZ] kann man im folgenden Beispiel erkennen (S. 6), bei dem sich das leichte Kopulaverb „ist“ zwischen Kopfnomen und Genitivattribut schleicht:
weil sie schöpferische Kraft ist eines primitiven Menschentums
Das sind sie, die Behaghelschen Gesetze, und aus ihnen speist sich sozusagen der normale (deutsche) Satzbau:
In diesen mehr oder weniger fest überlieferten Regeln hat eine ganz ruhig, gleichmäßig dahinfließende Rede ihre stets wiederkehrende Gestalt gefunden.
(Behaghel 1932: 8)
Sozusagen orthogonal zu den obigen Regeln unterscheidet Behaghel (1932: 3, 8) zwischen der gebundenen (auch: habituellen, usuellen) Wortstellung mit unterschiedlichem Geltungsbereich (z.B. nur auf Nebensätze bezogen) und Bedarfsstellungen (z.B. „durch das Bedürfnis des Gegensatzes“); letztere würde man heute als „markierte Abfolgen“ ansprechen. Dazu ein einschlägiges Beispiel (ähnliche Beispiele finden sich z.B. bei Behaghel 1930a: 88):
[A] Gestern habe ich ein Gedicht der/dem xy gewidmet.
[B] M Gewidmet habe ich gestern ein Gedicht der/dem xy.
[C] M Ein Gedicht habe ich der/dem xy gestern gewidmet.
Kommentar: [B] und [C] sind markierte Abfolgen, d.h. sie können nur in spezifischeren Gesprächskontexten auftreten, während [A] die Normalwortstellung darstellt. Als einfachen Test kann man sich fragen, welchen der obigen Sätze man sozusagen „out of the blue“, also quasi beim Hereinspazieren durch die Türe äußern könnte.
Auch an diesen Überlegungen zeigt sich, dass Behaghel einer der Pioniere auf dem Forschungsfeld der Informationsstruktur war, verstanden im allgemeinsten Sinne als Verpackung von Information, die den unmittelbaren kommunikativen Bedürfnissen der Gesprächspartner folgt (siehe dazu grundlegend Krifka 2007).

Leicht vor schwer, alt vor neu, das war sein Motto. So kennen und schätzen wir ihn – Behaghels Otto.
Literatur
Adorno, Theodor W. (1994): Minima Moralia. Frankfurt am Main: Suhrkamp. 22. Aufl.
Behaghel, Otto (1909): Beziehungen zwischen Umfang und Reihenfolge von Satzgliedern. Indogermanische Forschungen 25: 110–142.
—(1923–1932): Deutsche Syntax. Eine geschichtliche Darstellung. Bd. 1 (1923), Bd. 2 (1924), Bd. 3 (1928), Bd. 4 (1932). Heidelberg: Carl Winter Universitätsverlag.
—(1930a): Von deutscher Wortstellung. Zeitschrift für den deutschen Unterricht 44(2): 81–89.
—(1930b): Zur Wortstellung des Deutschen. Language 6(4): 29–33 (Language Monograph No. 7: Curme Volume of Linguistic Studies).
Einhauser, Eveline (2001): Die Entstehung und frühe Entwicklung des junggrammatischen Forschungsprogramms. In: Sylvain Auroux [u.a.] (Hgg.): Geschichte der Sprachwissen-schaften. Ein internationales Handbuch zur Entwicklung der Sprachforschung von den An-fängen bis zur Gegenwart. (Handbücher zur Sprach- und Kommunikationswissenschaft; 18.2.) Berlin, New York: De Gruyter, 1338–1350.
Fleischer, Jürg und Oliver Schallert (2011): Historische Syntax des Deutschen – eine Einfüh-rung. (Narr Studienbücher.) Tübingen: Narr.
Hawkins, John A. (1994): A performance theory of order and constituency. (Cambridge studies in linguistics; 73). Cambridge [u.a.]: Cambridge University Press.
—(2014): Cross-linguistic variation and efficiency. New York: Oxford University Press.
Krifka, Manfred (2007): Basic notions of information structure. In: Caroline Féry, Gisbert Fanselow und Manfred Krifka (Hgg.): The notions of information structure. (Working Pa-pers of the SFB 632; 6). Potsdam: Universitätsverlag Potsdam, 13–55.
Ries, John (1907): Die Wortstellung im Beowulf. Halle a. d. Saale: Niemeyer.
Speyer, Augustin (2010): Topicalization and stress clash avoidance in the history of English. (Topics in English linguistics; 69.) Berlin, New York: De Gruyter.
Wasow, Thomas (1997): Remarks on grammatical weight. Language Variation and Change 9: 81–105.
Wegera, Klaus-Peter (2000): Grundlagenprobleme einer mittelhochdeutschen Grammatik. In: Besch, Werner, Anne Betten, Oskar Reichmann und Stefan Sonderegger (Hgg.) (2000): Sprachgeschichte. Ein Handbuch zur Geschichte der deutschen Sprache und ihrer Erforschung. (Handbücher zur Sprach- und Kommunikationswissenschaft 2.1–2.4.). Berlin, New York: Mouton de Gruyter, 1304–1320. 2., vollständig neu bearbeitete Auflage.
Jürg Fleischer verdanke ich einen interessanten Hinweis. Bei seinen Untersuchungen zur Syntax der Wenkermaterialien ist er auf den unten wiedergegebenen Beleg gestoßen, der aus dem österreichischen Bundesland Kärnten stammt. Eigene Recherchen in toten halben Stunden (zwischen irgendwelchen Terminen) haben einen weiteren Fund zutage gefördert, der hier ebenfalls angeführt ist.
Wo gehst den hin, a derfi mit dir gehn? (Bogen 44320: Bad Eisenkappel)
Wo gehst den hin, a sollmr mit dir gehn. (Bogen 44278: Markt Griffen)
Dialektologisch gehören diese Belege übrigens zum südbairischen Sprachgebiet, was ich hier en passant erwähne, aber einmal ein interessantes Thema für einen eigenen Beitrag wäre. Man muss dazu sagen, dass Jürg für seine Untersuchungen „lediglich“ eine Teilmenge der insgesamt weit über 50000 Bögen verwendet (alles andere wäre auch für mendelianisch veranlagte Forschertypen nicht leistbar): Ausgehend von einem Quadranten-Netz, das das gesamte Erhebungsgebiet des „Deutschen Sprachatlas“ umfasst, wählt er jeweils den zentralsten Bogen pro Quadrant aus. Wenn es keinen solchen gibt bzw. dieser aus verschiedenen Gründen nicht verwendet werden kann, kommt jeweils der nächstzentralere Bogen zum Zug usw. Schlussendlich gelangt er zu einem Sample, das noch immer 2310 (!) Orte umfasst (Fleischer 2015: 194).
Sei’s, wie’s sei: In der Auswertung zu Wenkersatz 12, der hier in
voller standarddeutscher Pracht wiedergegeben ist, ist das obige Fundstück zu finden.
Wo gehst Du hin? Sollen wir mit Dir gehn?
Ohne Validierung durch alternative Quellen sollte man solchen Findlingen mit der gebotenen Skepsis begegnen, denn das Wenkermaterial ist für seine gelegentlichen Quatsch-Strukturen bekannt. Dialektologische Geister außerhalb des Marburger Dunstkreises wie etwa der 2010 verstorbene Arno Ruoff waren sogar dazu geneigt, dem einzelnen Bogen jeglichen Aussagewert abzusprechen. Seiner Auffassung zufolge liege „der hohe Wert des Materials […] eben ausschließlich in der Dichte des Belegnetzes: nirgends wird Quantität so sehr zur Qualität wie hier; das einzelne Formular ist nahezu wertlos“ (Ruoff 1965: 109). Dass der Wert des einzelnen Bogens, aber auch der sich bei der Auswertung bzw. Kartierung ergebenden Raumstrukturen nicht a priori fest steht, gilt inzwischen als dialektologischer Konsens; „beide bedürfen (wie übrigens jedes empirische Datum) einer sorgfältig abwägenden Interpretation bzw. einer Validierung durch alternative Datentypen“ (Schallert 2013: 227).
Anyhow, ein Blick in Heinz-Dieter Pohls „Kleine Kärntner Mundartkunde“ (1989) zeigt, dass an der Sache etwas dran ist. Er führt u.a. die folgenden Belege an (die ich – nicht inhaltlich – leicht angepasst habe):
Südbairisch in Kärnten: Pohl (1989: 64)
a we:r khimp(t)’n då
„wer kommt denn da?“
a khe:man Se hait?
a Se khe:man hait?
„kommen Sie heute?“
Es zeigt sich also, dass die Fragepartikel a sowohl in Ergänzungs- als auch Entscheidungsfragesätzen auftritt, und zwar immer in präverbaler Position. Pohls Angaben zufolge ist beim letzteren Typ die typische Spitzenstellung des Finitums nicht obligatorisch, so dass mit Zusatz der Partikel auch Verbzweit-Stellung möglich ist.
Interessant ist nun aber besonders der folgende Zusatz (ebd.): „Diese Partikel ist im Südbairischen weit verbreitet“. In diesem Sinne äußert sich übrigens auch das Wörterbuch der bairischen Mundarten in Österreich, wo dieses Element als „Fragepartikel“ vermerkt wird, und zwar „in dieser Verwendung vor allem in Kä[rnten].“ Weiterhin liest man dort: „In der südbair. Bauernmda. vor Fragewörtern; awę̄’r wer; awō’ wo“. Danke an Ingeborg Geyer für den Hinweis.
Was ist – abgesehen von der Lust an subtilen dialektologischen Jagden – interessant an diesen Strukturen? Fragepartikeln wirken aus germanistischer Brille wie ein Kuriosum, aus typologischer Perspektive sind sie allerdings eine stinknormale Erscheinung. Die entsprechende Karte (zu Entscheidungsfragesätzen) im World Atlas auf Language Structures zeigt dies sehr schön: Von 955 (!) Sprachen im Sample kennen 585 dieses Muster, wobei es freilich auch in Kombination mit anderen grammatischen Mitteln auftreten kann, allen voran der für diesen Satztyp charakteristischen steigenden Intonation. Ein typisches Beispiel aus dem Türkischen sei hier angeführt, aber auch das zu Kärnten unmittelbar benachbarte Slowenische verwendet in ja/nein-Fragen eine Fragepartikel, nämlich ali, umgangssprachlich a (und hier sollten die Sprachkontakt-Alarmglocken klingeln).
Türkisch: Péteri (2013: 875)
Ali dün Ístanbul’a gitti mi?
Ali gestern Istanbul-nach geh-PST INT
„Ging Ali gestern nach Istanbul?“
Die oben erwähnte Wals-Karte ist insofern auch höchst erhellend, als sie zeigt, dass es im zugrundeliegenden Sample nur wenige Sprachen (insgesamt 13) gibt, die Entscheidungsfragesätze durch Wortstellungsvariation ausdrücken, also dem „deutschen Typ“ entsprechen. Bis auf wenige Ausnahmen sind diese auf Europa beschränkt.
Damit hier uns richtig verstehen: Modalpartikeln wie denn (in den Dialekten oft als klitische Form n) kann man nicht mit den Fragepartikeln in einen Topf werfen, da sie in der Standardsprache (und wohl auch den meisten Dialekten) weniger stark grammatikalisiert sind, wenngleich in Bezug auf die grammatischen Eigenschaften sehr deutliche Affinitäten zwischen beiden Klassen festzustellen sind. Der augenscheinlichste Unterschied zwischen dem kärntnerischen a und dem n ist ihre Position: ersteres immer präverbal, letzteres postverbal, in der sogenannten „Wackernagelposition“, dem sicheren Hafen in der deutschen Satzstruktur für schwachtonige Elemente. Für einen ausgezeichneten Überblick zu Fragesätzen in den deutschen Dialekten sei dem interessierten Leser der Überblicksartikel von Helmut Weiß (2013) anempfohlen, besonders S. 769–774.
Fragepartikeln wirken (trotz Überschneidungen mit den Modalpartikeln) aus der Perspektive des heutigen Deutschen recht exotisch, im Althochdeutschen waren sie jedoch noch zu finden (siehe dazu u.a. Axel 2007: 41–43; Fleischer und Schallert 2011: 156–158).
Althochdeutsch: Fleischer und Schallert (2011: 157)
eno tuot her thanne managerun zeichan | thanne theser tuot
PART tut er denn viele Zeichen als dieser tut
„Tut er denn nicht etwa mehr Zeichen, als dieser tut?“ (Tatian 169, 15)
Natürlich liegt im Falle des Kärtnerischen die Vermutung nahe, dass der Sprachkontakt hier seine unsichtbare Hand im Spiel hatte, denn Fragepartikeln sind aus dem Slowenischen wohlbekannt (was übrigens auch in der oben erwähnten Wals-Karte ersichtlich ist bzw. entnommen werden kann (dort wird als Referenz Priestly 1993: 430 zitiert). Auch im Kärntner Slowenischen muss man nicht lange nach dieser Erscheinung suchen, wobei man in den Wenkermaterialien sowohl die standardnähere Variante ali als auch das dialektale bzw. umgangssprachliche a antrifft; für letzteres hier ein Beispiel:
Kam hreš ti, a hremo s tbo? (Bogen 44317: Zell)
Interessant ist in diesem Zusammenhang auch die Beobachtung, dass Fragepartikeln auch aus den alpinromanischen Dialekten, in Sonderheit dem Ladinischen und verschiedenen norditalienischen Varietäten bekannt sind (darauf verweist übrigens auch Pohl 1989: 67, wenn auch unter einem etwas missverständlichen Header). Wer sich genauer für diese Erscheinung interessiert, sei auf Franziska Hacks ausgezeichnete Arbeiten zu diesem Thema verwiesen (z.B. Hack 2012).
Grödnerisch: Hack und Kaiser (2013: 145)
Compra pa la mutans versura?
kaufen PA die Mädchen Obst
„Kaufen die Mädchen Obst?“
Ob die kärnterischen Fragepartikeln das Zeug dazu haben, Guido Seilers Alpensprachbund-Hypothese (siehe Seiler 2004) zu untermauern, sei dahingestellt. Aus Perspektive des Bairischen sieht die Sache ja eher nach „reinem“ Sprachkontakt aus und nicht – so Guidos These – nach einer kontaktinduzierten Innovation, die über die Kontaktzone hinausschwappt. Dennoch gibt es Phänomene, die ganz gut in diese Kiste passen, beispielsweise Doubly-filled COMPs, wie man sie in eingebetteten (und im Romanischen auch selbstständigen) Fragesätzen sieht. Mehr dazu zu gegebener Zeit, denn ich arbeite gerade mit zwei Kollegen (Alex Dröge und Jeff Pheiff) an einem Paper zu dieser Phänomen.
Nimmt man Pohls Hinweis ernst, wonach die Fragepartikel a eine durchaus verbreitete Erscheinung im Südbairischen ist, dann stellt sich die allgemeinere Frage, ob es auch noch andere Dialekte des Deutschen gibt, die diese Erscheinung kennen. Ich schwanke zwischen Optimismus und Pessimismus: Wenn es das Phänomen anderswo gäbe, wäre es sicher schon mal einem Dialektologen aufgefallen. Andererseits gehörte die Syntax-Pragmatik-Schnittstelle nie wirklich zur dialektologischen Kernagenda – man denke an Ernst Schwarz’ oft zitiertes Wort von der Syntax als „Stiefkind der Mundartforschung wie der deutschen Sprachforschung überhaupt“ (Schwarz 1950: 118) –, d.h. es kann genauso gut sein, dass dieses Phänomen gerade unterhalb der Wahrnehmungsschwelle ist. Darum seien hiermit Fragepartikeln zur Fahndung ausgeschrieben. Ob sich eine Rasterfahndung mittels Wenkermaterialien (z.B. mittels engermaschigem Ortsnetz bzw. lokal beschränkten Teilauswertungen) lohnt bzw. ergiebig ist, kann ich nicht beurteilen, aber probieren kann man’s ja mal.
Literatur
Axel, Katrin (2007): Studies on Old High German syntax. Left sentence periphery, verb placement and verb second. Amsterdam, Philadelphia: John Benjamins.
Fleischer, Jürg (2015); PRO-DROP und Pronominalenklise in den Dialekten des Deutschen. Eine Auswertung von Wenkersatz 12. In: Michael Elmentaler, Markus Hundt und Jürgen Erich Schmidt (Hgg.): Deutsche Dialekte. Konzepte, Probleme, Handlungsfelder. Akten des 4. Kongresses der Internationalen Gesellschaft für Dialektologie des Deutschen (IGDD). Stuttgart: Steiner, 191–209.
Fleischer, Jürg und Oliver Schallert (2011): Historische Syntax des Deutschen – eine Einführung. Tübingen: Narr.
Hack, Franziska Maria (2012). The syntax and prosody of interrogatives: evidence from varieties spoken in northern Italy. Dissertation, University of Oxford.
Hack, Franziska Maria und Georg A. Kaiser (2013): Zur Syntax von Fragesätzen im Rätoromanischen. In: Georges Darms (Hg.): Aktes des V. Rätoromanischen Kolloquiums: Lavin 2011. Tübingen: Francke, 137–161.
Hornung, Maria (Hg.) (1970): Bayerisch-österreichisches Wörterbuch. Bd. 1: A–Azor. Wien: Österreichische Akademie der Wissenschaften.
Péteri, Attila (2013): Satztypen und Sprachkontrast. In: Jörg Meibauer, Markus Steinbach und Hans Altmann (Hgg.): Satztypen des Deutschen. Berlin, New York: de Gruyter, 874–901.
Pohl, Heinz-Dieter (1989): Kleiner Kärntner Mundartkunde mit Wörterbuch. Klagenfurt: Heyn.
Priestly, Tom (1993). Slovene. In: Bernard Comrie und Greville G. Corbett (Hgg.): The Slavonic Languages. London: Routledge, 388–451.
Ruoff, Arno (1965): Wenkersätze auf Tonband? In: Sprachen – Zuordnung – Strukturen. Festgabe seiner Schüler für Eberhard Zwirner. Den Haag: Nijhoff, 94–113.
Schallert, Oliver (2013): Syntaktische Auswertung von Wenkersätzen: eine Fallstudie anhand von Verbstellungsphänomenen in den bairischen (und alemannischen) Dialekten Österreichs. In: Rüdiger Harnisch (Hg.): Strömungen in der Entwicklung der Dialekte und ihrer Erforschung: Beiträge zur 11. Bayerisch-Österreichischen Dialektologentagung in Passau September 2010. Regensburg: Edition Vulpes, 208–233, 513–515.
Schwarz, Ernst (1950): Die deutschen Mundarten. Göttingen: Vandenhoeck & Ruprecht.
Seiler, Guido (2004): Gibt es einen Alpensprachbund? In: Elvira Glaser, Peter Ott, and Rudolf Schwarzenbach (Hgg.): Alemannisch im Sprachvergleich. Beiträge zur 14. Arbeitstagung für alemannische Dialektologie in Männedorf (Zürich) vom 16.–18.9.2002. Stuttgart: Steiner, 485–493.
Weiß, Helmut (2013): Satztyp und Dialekt. In: Jörg Meibauer, Markus Steinbach und Hans Altmann (Hgg.): Satztypen des Deutschen. Berlin, New York: de Gruyter, 764–785.
Dies ist mein erster Blogeintrag. Komisches Format. Viele schreiben Blogartikel, was ich grundsätzlich eine feine Sache finde, wenngleich ich nicht weiß, ob Blogartikel auch im selben Ausmaß gelesen werden. Aber Texte sind nicht nur für die Leser geschrieben.
Was ist die Idee hinter diesem Blooooaag? Schon länger habe ich mich mit der Idee getragen, so etwas anzugehen, aber das Ganze ist dann immer schnell versandet. Diesmal nicht. Ischwöre.
Ich sehe diese Textsorte als Möglichkeit, Gedanken, Beobachtungen und Ideen zu teilen, ins Unreine zu denken und die Netzintelligenz als Input und Orakel zu nutzen: Sowohl für meine „Forschung“ als auch das, was mich sonst so umtreibt. Gelegentlich möchte ich auch andere Leute einladen, um über Themen zu schreiben, zu denen ich nichts Intelligentes bzw. Informiertes sagen kann, die mich aber gleichwohl in Bann schlagen (z.B. Mathematik, Sprache und Musik usw.). Soviel dazu. Wer noch brennende Fragen hat, möge den FAQ-Abschnitt konsultieren, den ich nun in bewährter Netzmanier folgen lasse. Andernfalls könnt Ihr auch direkt zum ersten „echten“ Blogeintrag begeben (sorry, ist ein bisschen akademisch geworden; ist noch neu, die Textsorte).
FAQs: