
Abstract
Identification of individuals with increased risk of major adverse cardiovascular events (MACE) is important. However, algorithms specific to the elderly are lacking. Data were analysed from a randomised trial involving 18,548 participants ≥ 70 years old (mean age 75.4 years), without prior cardiovascular disease events, dementia or physical disability. MACE included coronary heart disease death, fatal or nonfatal ischaemic stroke or myocardial infarction. Potential predictors tested were based on prior evidence and using a machine-learning approach. Cox regression analyses were used to calculate 5-year predicted risk, and discrimination evaluated from receiver operating characteristic curves. Calibration was also assessed, and the findings internally validated using bootstrapping. External validation was performed in 25,138 healthy, elderly individuals in the primary care environment. During median follow-up of 4.7 years, 594 MACE occurred. Predictors in the final model included age, sex, smoking, systolic blood pressure, high-density lipoprotein cholesterol (HDL-c), non-HDL-c, serum creatinine, diabetes and intake of antihypertensive agents. With variable selection based on machine-learning, age, sex and creatinine were the most important predictors. The final model resulted in an area under the curve (AUC) of 68.1 (95% confidence intervals 65.9; 70.4). The model had an AUC of 67.5 in internal and 64.2 in external validation. The model rank-ordered risk well but underestimated absolute risk in the external validation cohort. A model predicting incident MACE in healthy, elderly individuals includes well-recognised, potentially reversible risk factors and notably, renal function. Calibration would be necessary when used in other populations.
Similar content being viewed by others


Introduction
Atherothrombotic cardiovascular disease (CVD) is a very important non-communicable disease worldwide and associated with high morbidity and mortality [1,2,3,4]. The WHO has declared CVD as one of the priority diseases within their action plan, aiming to reduce CVD-related mortality by 25% by 2025 [5]. A key requirement to achieve this goal is to improve the prediction of incident CVD events. This requires identification of individuals at highest risk of major adverse cardiovascular events (MACE) to target effective interventions.
Modifiable and non-modifiable risk factors have been incorporated in algorithms aimed to estimate an individual’s risk of future cardiovascular events [4, 6,7,8,9]. These algorithms include traditional risk factors, and estimate the future risk of fatal or nonfatal events, over a period of 5 or 10 years. An important limitation of most risk scores is that the population cohort data from which they were derived have included individuals whose median age is typically less than 70 years. However, with the ageing of high-income countries, most cardiovascular events now occur in the elderly, beyond the range of most existing equations.
As an example, the European Society of Cardiology (ESC) Systematic COronary Risk Evaluation 2 (SCORE2) is limited to the age range from 40 to 65 years and the median age of the recently published LIFE-CVD cohorts was approximately 60 years [9, 10]. Several studies have demonstrated that SCORE, Framingham and other similar algorithms are less effective in predicting cardiovascular events in the elderly [11, 12]. Thus, recent ESC guidelines have not recommended their use in individuals over 70 years, as the risk for cardiovascular events might be overestimated due to competing causes of death [4, 13].
CVD risk prediction models developed specifically for use in the elderly also have important limitations. The recently published SCORE2 Older Persons (OP) equation estimates future risk of incident CVD events [14]. However, it is only based on established risk factors included in the original SCORE project and in addition, high-density lipoprotein cholesterol (HDL-c) and diabetes, while predictors such as renal function or comorbidities were not considered. Prediction algorithms developed from the PROSPER and ARIC studies were based on smaller and less contemporary cohorts and had a shorter duration of follow-up [15, 16]. More recent findings also suggest that traditional risk factors for CVD might be weaker predictors of future risk in the elderly while the strength of other factors such as chronic kidney disease increases with ageing [11]. Therefore, improved prediction of CVD events in the elderly represents an unmet clinical need.
Given these limitations, we aimed to develop a risk prediction model for incident MACE from subjects enrolled in a large clinical trial in initially healthy, elderly individuals and to validate the model in a large primary care dataset.
Methods
Derivation dataset
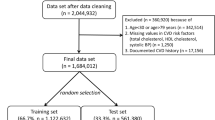
For the derivation of the risk model, data from the ASPirin in Reducing Events in the Elderly (ASPREE) study was analysed. Details of the ASPREE study have been reported previously [17,18,19]. Briefly, it was a randomised, placebo-controlled trial investigating the effect of low-dose aspirin on disability-free survival in healthy, elderly people. Cardiovascular events were amongst the prespecified secondary endpoints. In total, 19,114 community-dwelling individuals aged ≥ 70 years (≥ 65 for US minorities), without prior CVD events, dementia or physical disability were recruited in Australia and the USA. Specific exclusion criteria are reported in the Supplementary Material. For the present analyses, we also excluded all participants aged < 70 years, as they comprised US minorities. All participants provided written informed consent. The study was approved by local Ethics Committees and is registered on clinicaltrials.gov (NCT01038583).
Potential predictors investigated
All baseline variables were investigated as potential predictors and collected as part of the standardised recruitment process. The initial selection of such predictors was based on prior research and risk models, and included age, sex, smoking history, systolic and diastolic blood pressure, current use of antihypertensive agents, HDL-c, non-HDL-c, serum creatinine, diabetes, body mass index (BMI), haemoglobin, family history of myocardial infarction (MI) and an area-based measure of socioeconomic status (the Index of Relative Socio-economic Advantage and Disadvantage (IRSAD) score). Details concerning these predictors are provided in the Supplementary Material.
Endpoint
The primary endpoint for our analyses was a composite of incident MACE. This included coronary heart disease (CHD) death, nonfatal MI and fatal or nonfatal ischaemic stroke. Causes of CHD death included MI, sudden or rapid cardiac death and other CHD death, but not death from heart failure which was not attributable to CHD. All events were adjudicated by expert committees blinded to treatment allocation, as described previously [18].
External validation dataset
The PREDICT cohort study, which has been described before in detail, was used as an external validation dataset [8]. Briefly, PREDICT is an ongoing cohort study in New Zealand, which automatically enrols participants without prior events having absolute CVD risk assessment in primary care. Using linkage to national hospitalisation and mortality databases based on International Classification of Disease (ICD) codes, incident events are captured. For the present analyses, we only considered PREDICT participants aged 70–79 years at baseline, of self-reported European ethnicity and without CVD. To replicate the ASPREE exclusion criteria, we further excluded PREDICT participants having certain ICD codes, particularly related to cancer at baseline or the prior 5 years (Supplementary Material). The MACE endpoint in the validation dataset was based on ICD codes and included MI, ischaemic stroke and death from CHD (Table S1).
Statistical analyses
Cox proportional hazard regression models were used to calculate the 5-year predicted risk of MACE. Participants who died for reasons other than MACE were censored at the time of death. To allow estimation of predicted risks in the external data, baseline survival probability at 5 years was obtained by computing the survival function of a reference participant. A reference participant was a subject whose all covariates were equal to zero.
As the amount of missing data for most variables was low (< 5%), and it was reasonable to be considered as missing at random, a complete case analysis was used to develop prediction models [20]. However, the IRSAD score was missing in all US participants and was therefore only considered in sensitivity analyses.
Prior to variable selection, we tested for potential non-linear relationships of continuous variables and the outcome by modelling them as restricted cubic spline functions with two degrees of freedom. From the initial selected predictors, a variable was incorporated in the final model if it showed a strong association with the outcome in the data (p < 0.05 in univariable analyses) or because it was an established CVD predictor in prior research.
To validate the variable selection, we additionally performed a machine-learning variable selection using the least absolute shrinkage and selection operator (lasso) in combination with bootstrapping. Sex-specific models were examined as an exploratory analysis.
Regarding model performance, the cumulative/dynamic receiver operating characteristic curves and the area under the curve (AUC) for 5-year risk were used to evaluate discrimination with each of the selected predictors and the final model. To assess the agreement between predicted and observed risks at 5 years, we used calibration plots [21]. The model performances were corrected for overfitting by internal bootstrap validation. Specifically, the selected predictors were fitted to each bootstrap sample to obtain bootstrap final models. The optimism due to overfitting was then obtained by comparing the performance of the bootstrap final models on the original dataset and bootstrap datasets. We calculated the bias-corrected model performance by subtracting the estimated optimism from the original model performance. The derived model was then applied in the validation dataset, and AUC and calibration evaluated. Finally, we aimed to compare the model performance with the recently published SCORE2-OP model.
All analyses were performed using R version 3.6.1 (R Foundation for Statistical Computing, Vienna, Austria, www.r-project.org).
Results
Baseline characteristics of the derivation dataset
The derivation dataset consisted of 18,548 participants with a mean age of 75.4 years, of whom 10,426 (56.2%) were female (Table 1). The majority were in the age categories ranging from 70 to 74 years (57.1%) and 75 to 79 years (27.1%), while only 3.9% were aged above 85 years. When comparing males and females, only minor differences were observed (Table S2). Most continuous variables in the dataset showed only low to moderate correlation (Figure S1).
Development of the prediction model
During the median follow-up time of 4.7 years (interquartile range 3.6–5.7), 594 incident MACE were recorded (Table S3). In univariable regression analyses, diastolic blood pressure, BMI and family history of MI were not significant predictors for incident MACE (Table S4, Figure S2).
When considering all predictors in one model, only age, sex, current smoking, systolic blood pressure, non-HDL-c, HDL-c, serum creatinine and intake of antihypertensive agents were significant predictors (Table S5). Thus, diastolic blood pressure, BMI, haemoglobin and family history of MI were not considered for the final model. However, diabetes was forced into the model, because it is an established cardiovascular risk factor.
The final algorithm was developed from 17,742 individuals (Table 2). Increasing age, being a current smoker or having diabetes, taking antihypertensive agents, or having higher systolic blood pressure, non-HDL-c or serum creatinine increased the risk of MACE, while being female or increasing HDL-c decreased the risk of MACE (Figure S3). The final model had an AUC of 68.11 (95% confidence interval [CI] 65.86; 70.36) (Table S6). The final model demonstrated good calibration in the derivation dataset, with similar predicted and observed risks of MACE (Fig. 1). This finding was also confirmed, when evaluating calibration separately for males and females (Figure S4). The internal validation of the model showed a bias-corrected AUC of 67.52 (Table S6). Application of the SCORE2-OP model in the ASPREE population resulted in an AUC of 66.31 (95% CI 64.00; 68.61) (Table S6).

Calibration plot of the prediction model. The black dots compare the observed and the predicted MACE probability together with the 95% confidence intervals. The blue crosses for the validation dataset represent biased-corrected predicted risk based on 200 bootstrap samples
In an alternative approach to variable selection based on machine-learning, age, sex, serum creatinine, non-HDL-c, HDL-c and systolic blood pressure were identified as the most important predictors, with each of them being selected in more than 50% of cases (Table 3).
External validation
The external validation dataset consisted of 25,138 participants whose baseline characteristics were similar to the derivation dataset (Table S7). Their mean age was 73.2 years (SD 2.62), 53% were females, 5% were current smokers, 13% had diabetes, mean systolic blood pressure was 136 mmHg (SD 14.9), mean non-HDL-c concentration was 3.6 mmol/L (SD 0.99) and mean serum creatinine concentration was 0.91 mg/dL (SD 0.21).
During a median follow-up time of 6.4 years, 2,340 MACE were observed (Table S3). The final model showed an AUC of 64.16 (95% CI 62.77; 65.55, Table S6). The model effectively rank-ordered risk of MACE; however, the score clearly underestimated absolute risk in the validation cohort (Fig. 1).
Sensitivity analyses
In sensitivity analyses, we included the IRSAD score as an indicator of socioeconomic status, but it was not shown to be an independent predictor of MACE (Table S8). When also including the IRSAD score in the lasso selection, this showed a low inclusion frequency (Table S9).
We also calculated the model for males and females separately (Table S10, Figure S3). In males, age, current smoking, systolic blood pressure, non-HDL-c and serum creatinine remained independent predictors, while HDL-c, diabetes and intake of antihypertensive agents were not. In females, age, current smoking, non-HDL-c and intake of antihypertensive agents remained independent predictors, while systolic blood pressure, HDL-c, diabetes and serum creatinine were not.
Discussion
In a large, contemporary population of healthy, elderly individuals in Australia and the US who volunteered for a clinical trial, we developed a model predicting incident MACE. This model includes age, sex, current smoking, systolic blood pressure, HDL-c, non-HDL-c, serum creatinine, diabetes and intake of antihypertensive agents as predictors and resulted in good discrimination and calibration in internal validation analyses (Fig. 2). Importantly, the model was externally validated in a large dataset of older people undergoing cardiovascular risk assessment in primary care in New Zealand. The model effectively ranked older individuals in order of MACE risk but significantly underestimated the absolute risk in this validation cohort.

Summarising figure
Most established risk prediction models have excluded elderly individuals. This applies to the well-established ESC SCORE2, which is only recommended for individuals aged below 66 years [10]. The atherosclerotic CVD score is also limited to an upper age of 79 years [22] and has been shown to perform substantially worse in older than in younger individuals [12].
There are relatively few specific risk models for elderly individuals. The SCORE2 Older Persons risk model is the most recognised [14], and was validated in different external cohorts. Another risk model was based on the PROSPER study, which included 5,146 elderly individuals without CVD [16]. The PROSPER cohort was substantially different from ASPREE. It is no longer contemporary, as recruitment commenced in 1997, and it represents a high-risk population with 33% current smokers and mean systolic blood pressure very high, being 157 mmHg.
In contrast to these previous models, the ASPREE model was derived from a contemporary, healthy population with fairly well-controlled risk factors, a high degree of antihypertensive or lipid-lowering drug use, contributing to a lower CVD event rate than expected from prior data. Importantly, due to rigorous screening at baseline, we can be confident that all participants had no prior CVD events.
Although caution is needed in comparing findings from different cohorts, the discrimination of the model, with an AUC of 0.68, was higher than observed with other models in older people. The atherosclerotic CVD score resulted in an AUC of 0.62 and the original validation of the SCORE2-OP in an AUC of 0.63 [12, 14, 23]. When the SCORE2-OP model was applied in ASPREE, it resulted in an AUC of 0.66. However, the AUC was lower compared to the performance of other risk models developed in younger individuals, where the AUC usually ranged between 0.70 and 0.75 [24]. This could be explained by the greater importance of competing mortality risks in the elderly and the fact that their more frequent multimorbidity makes MACE adjudication more difficult. This older cohort also has a narrow age range and therefore more homogeneous, limiting capacity for discrimination.
The model was externally validated in the large PREDICT cohort, which consists of community-dwelling people without prior CVD events undergoing absolute CVD risk estimation. The primary care environment is ideal for validation of the model, as it is the setting in which application in clinical practice typically occurs. Importantly, we were able to mimic the ASPREE population in the validation dataset by applying ICD codes for prior CVD events, cancer diagnoses and cognitive impairment. As usually expected in validation studies, the discrimination was lower in PREDICT compared to ASPREE. Importantly, absolute CVD risk was significantly underestimated in the validation cohort. There are several possible explanations for this. These include the relatively low risk of the ASPREE population, likely contributed to by a healthy-volunteer effect. Event ascertainment was also different, as ASPREE used the strict adjudication process of a clinical trial, while PREDICT used ICD codes. Furthermore, inter-country differences in CVD risk between Australia and New Zealand may be important. Finally, there remain some differences between the derivation and validation populations, as individuals with major physical disability, atrial fibrillation or serious illness were excluded in ASPREE, but not in PREDICT. Therefore, recalibration of the ASPREE model according to the risk in the particular population in which the equation would be applied should be undertaken. This has for example been done for the ESC SCORE, distinguishing low- and high-risk countries [4].
An important difference from previous models is also the time frame for risk prediction. Most established risk models provide estimates for events over 10 years. However, a shorter time horizon of 5 years may be more appropriate in the elderly, due to their limited life expectancy and the high frequency of competing causes of death, especially cancer [15]. This shorter time frame also enables more precise modelling and presentation of the potential impact of evidence-based interventions as it approximates the duration of most CVD prevention trials. Furthermore, focus group testing of elderly has found that consumers value nearer life years more highly and discounted events further into the future [25].
In our analyses, we provide significant support for the relevance of traditional predictors in elderly individuals. That age remains the dominant predictor was expected. This was also confirmed in a recent analysis of 12 predictors using artificial intelligence which also found that age was the most important [26]. Sex, smoking, lipids, systolic blood pressure and intake of antihypertensive agents are also well-established risk factors and remain important predictors in the elderly. The persisting relevance of modifiable risk factors emphasises the role of primary prevention in the elderly. This particularly applies to elevated blood pressure, as shown in the SPRINT trial [27], as well as to elevated lipids. Here, recent data suggests not only an association of elevated lipids with MACE but also a benefit of statin treatment in elderly people [28, 29]. The reversibility of the risk of CVD conferred by elevated lipids and the benefit of statin treatment in elderly people are also being addressed in the ongoing STAREE and PREVENTABLE trials (NCT02099123, NCT04262206).
After age and sex, we found impaired renal function to be the third most frequently selected predictor in our machine-learning analysis. Although common in an elderly population, measures of impaired renal function have not been included in risk models developed in younger individuals, in whom impaired renal function is less frequent. In a recent analysis of the atherosclerotic CVD score in elderly individuals, the estimated glomerular filtration rate (eGFR) was substantially lower in elderly [12] and the PROSPER risk model included the eGFR as risk factor [16]. In our analysis, we focused on serum creatinine instead of the eGFR, as creatinine is more widely available and the adjustment for age contained in the eGFR model was less relevant.
Intriguingly, diabetes, although included in our model, was not identified as a significant predictor of MACE. This contrasts with recent analyses in elderly participants from three population-based studies, in which diabetes was a significant predictor for CHD events [12]. Only one study, the Finland Italy Netherlands Elderly study, did not show diabetes to be a significant predictor in elderly individuals [30]. This raises the question about whether the importance of diabetes as a risk factor might depend on the age at the time of diagnosis and therefore duration of exposure to risk. It is also noteworthy that a high proportion of the ASPREE participants were receiving treatment with statins and blood pressure lowering agents, particularly angiotensin converting enzyme inhibitors which may have impacted on the risk conferred by diabetes (Table S11). Finally, some diabetic patients would have been identified at initial study recruitment as part of screening.
The current burden of CVD in communities of advanced age is well established, with numerous studies documenting the increased requirement for hospital and community-based health services, as well as increased use of residential care facilities after CVD events [31]. Those who experience a CVD event are often unable to continue their usual activities, with many of those affected becoming increasingly reliant on government support [32, 33]. The identification of individuals at risk of MACE and successful early preventative intervention can thus have society-wide benefits. Given the ageing of populations globally [34], and thus the increasing numbers of individuals at high risk of CVD events, avoidance of the costs associated with CVD is a priority for governments. The routine use of a specific MACE prediction model offers an important way of minimising these costs.
This present investigation not only has certain strengths but also limitations. The major strength is the contemporary, high-quality dataset, which was used for the analyses. ASPREE, being a randomised controlled trial with a prespecified secondary outcome focused on CVD, provides systematic measurement of risk factors at baseline in a unique dataset of elderly individuals, free of CVD events at baseline. The robust ascertainment and adjudication process of all MACE outcomes also represents an important strength compared to other population-based studies. Another strength is clear definition of the population to whom these data are generalisable. Finally, we were able to apply the risk model in the family practice environment in the large PREDICT cohort, which shares important similarities with ASPREE. This resulted in a total of 43,686 elderly individuals available for our analyses.
Amongst the limitations, the data were obtained from a large clinical trial rather than a random sample from the general population. However, recruitment to a clinical trial allows formal exclusion of those with prior CVD events. In addition, the validation in the community-based PREDICT cohort showed similar findings particular in rank-ordering risk, albeit underestimating absolute risk. Amongst other limitations, the number of events in the derivation dataset was lower than would be expected in a general population. This is very likely explained by the healthy cohort effect resulting in better health status of the participants at baseline. Finally, our analyses were derived from a mainly Caucasian population and thus care may be needed in applying the model to other populations.
In conclusion, the ASPREE population reflects the increasingly large group of Caucasian individuals aged 70 years and over without CVD events, in general good health and who would be considered for primary prevention strategies [15]. In our analyses, we confirmed the importance of age, sex, systolic blood pressure, smoking and lipids for prediction of future MACE in a population of healthy, elderly individuals. We also identified impaired renal function as an important predictor, which has not been recognised in prior CVD risk models.
References
Roth GA, Mensah GA, Johnson CO, Addolorato G, Ammirati E, Baddour LM, et al. Global burden of cardiovascular diseases and risk factors, 1990–2019: update from the GBD 2019 study. J Am Coll Cardiol. 2020;76(25):2982–3021.
Yusuf S, Joseph P, Rangarajan S, Islam S, Mente A, Hystad P, et al. Modifiable risk factors, cardiovascular disease, and mortality in 155 722 individuals from 21 high-income, middle-income, and low-income countries (PURE): a prospective cohort study. Lancet. 2019.
Naghavi M, Abajobir AA, Abbafati C, Abbas KM, Abd-Allah F, Abera SF, et al. Global, regional, and national age-sex specific mortality for 264 causes of death, 1980–2016: a systematic analysis for the Global Burden of Disease Study 2016. Lancet. 2017;390(10100):1151–210.
Piepoli MF, Hoes AW, Agewall S, Albus C, Brotons C, Catapano AL, et al. 2016 European Guidelines on cardiovascular disease prevention in clinical practice: the Sixth Joint Task Force of the European Society of Cardiology and Other Societies on Cardiovascular Disease Prevention in Clinical Practice (constituted by representatives of 10 societies and by invited experts) developed with the special contribution of the European Association for Cardiovascular Prevention & Rehabilitation (EACPR). Eur Heart J. 2016;37(29):2315–81.
WHO. Global action plan for the prevention and control of NCDs 2013–20202013.
Piepoli MF, Hoes AW, Agewall S, Albus C, Brotons C, Catapano AL, et al. 2016 European Guidelines on cardiovascular disease prevention in clinical practice. Rev Esp Cardiol. 2016;69(10):939.
Yusuf S, Hawken S, Ounpuu S, Dans T, Avezum A, Lanas F, et al. Effect of potentially modifiable risk factors associated with myocardial infarction in 52 countries (the INTERHEART study): case-control study. Lancet. 2004;364(9438):937–52.
Pylypchuk R, Wells S, Kerr A, Poppe K, Riddell T, Harwood M, et al. Cardiovascular disease risk prediction equations in 400000 primary care patients in New Zealand: a derivation and validation study. Lancet. 2018;391(10133):1897–907.
Jaspers NEM, Blaha MJ, Matsushita K, van der Schouw YT, Wareham NJ, Khaw KT, et al. Prediction of individualized lifetime benefit from cholesterol lowering, blood pressure lowering, antithrombotic therapy, and smoking cessation in apparently healthy people. Eur Heart J. 2020;41(11):1190–9.
groupSw, collaboration ESCCr. SCORE2 risk prediction algorithms: new models to estimate 10-year risk of cardiovascular disease in Europe. Eur Heart J. 2021;42(25):2439–54.
Dalton JE, Rothberg MB, Dawson NV, Krieger NI, Zidar DA, Perzynski AT. Failure of traditional risk factors to adequately predict cardiovascular events in older populations. J Am Geriatr Soc. 2020;68(4):754–61.
Nanna MG, Peterson ED, Wojdyla D, Navar AM. The accuracy of cardiovascular pooled cohort risk estimates in U.S. older adults. J Gen Int Med. 2020;35(6):1701–8.
Rossello X, Dorresteijn JA, Janssen A, Lambrinou E, Scherrenberg M, Bonnefoy-Cudraz E, et al. Risk prediction tools in cardiovascular disease prevention: a report from the ESC Prevention of CVD Programme led by the European Association of Preventive Cardiology (EAPC) in collaboration with the Acute Cardiovascular Care Association (ACCA) and the Association of Cardiovascular Nursing and Allied Professions (ACNAP). Eur J Prev Cardiol. 2019;26(14):1534–44.
groupSOw, collaboration ESCCr. SCORE2-OP risk prediction algorithms: estimating incident cardiovascular event risk in older persons in four geographical risk regions. Eur Heart J. 2021;42(25):2455–67.
Saeed A, Nambi V, Sun W, Virani SS, Taffet GE, Deswal A, et al. Short-term global cardiovascular disease risk prediction in older adults. J Am Coll Cardiol. 2018;71(22):2527–36.
Stam-Slob MC, Visseren FL, Wouter Jukema J, van der Graaf Y, Poulter NR, Gupta A, et al. Personalized absolute benefit of statin treatment for primary or secondary prevention of vascular disease in individual elderly patients. Clin Res Cardiol. 2017;106(1):58–68.
McNeil JJ, Nelson MR, Woods RL, Lockery JE, Wolfe R, Reid CM, et al. Effect of aspirin on all-cause mortality in the healthy elderly. N Engl J Med. 2018;379(16):1519–28.
McNeil JJ, Wolfe R, Woods RL, Tonkin AM, Donnan GA, Nelson MR, et al. Effect of aspirin on cardiovascular events and bleeding in the healthy elderly. N Engl J Med. 2018;379(16):1509–18.
McNeil JJ, Woods RL, Nelson MR, Reid CM, Kirpach B, Wolfe R, et al. Effect of aspirin on disability-free survival in the healthy elderly. N Engl J Med. 2018;379(16):1499–508.
White IR, Royston P, Wood AM. Multiple imputation using chained equations: issues and guidance for practice. Stat Med. 2011;30(4):377–99.
Harrell FE. Regression modeling strategies: with applications to linear models, logistic and ordinal regression, and survival analysis. New York: Springer; 2015.
Arnett DK, Blumenthal RS, Albert MA, Buroker AB, Goldberger ZD, Hahn EJ, et al. 2019 ACC/AHA Guideline on the primary prevention of cardiovascular disease: a report of the American College of Cardiology/American Heart Association Task Force on Clinical Practice Guidelines. Circulation. 2019;140(11):e596–646.
Verweij L, Peters RJG, Scholte Op Reimer WJM, Boekholdt SM, Luben RM, Wareham NJ, et al. Validation of the Systematic COronary Risk Evaluation-Older Persons (SCORE-OP) in the EPIC-Norfolk prospective population study. Int J Cardiol. 2019;293:226–30.
Damen JA, Hooft L, Schuit E, Debray TP, Collins GS, Tzoulaki I, et al. Prediction models for cardiovascular disease risk in the general population: systematic review. BMJ. 2016;353:i2416.
Hill S, Spink J, Cadilhac D, Edwards A, Kaufman C, Rogers S, et al. Absolute risk representation in cardiovascular disease prevention: comprehension and preferences of health care consumers and general practitioners involved in a focus group study. BMC Public Health. 2010;10:108.
Sung JM, Cho IJ, Sung D, Kim S, Kim HC, Chae MH, et al. Development and verification of prediction models for preventing cardiovascular diseases. PloS one. 2019;14(9):e0222809.
Group SR, Wright JT Jr, Williamson JD, Whelton PK, Snyder JK, Sink KM, et al. A randomized trial of intensive versus standard blood-pressure control. N Engl J Med. 2015;373(22):2103–16.
Gencer B, Marston NA, Im K, Cannon CP, Sever P, Keech A, et al. Efficacy and safety of lowering LDL cholesterol in older patients: a systematic review and meta-analysis of randomised controlled trials. Lancet. 2020;396(10263):1637–43.
Mortensen MB, Nordestgaard BG. Elevated LDL cholesterol and increased risk of myocardial infarction and atherosclerotic cardiovascular disease in individuals aged 70–100 years: a contemporary primary prevention cohort. Lancet. 2020;396(10263):1644–52.
Houterman S, Boshuizen HC, Verschuren WM, Giampaoli S, Nissinen A, Menotti A, et al. Predicting cardiovascular risk in the elderly in different European countries. Eur Heart J. 2002;23(4):294–300.
Lesyuk W, Kriza C, Kolominsky-Rabas P. Cost-of-illness studies in heart failure: a systematic review 2004–2016. BMC Cardiovasc Disord. 2018;18(1):74.
Schofield D, Kelly S, Shrestha R, Passey M, Callander E, Percival R. The long term financial impacts of CVD: living standards in retirement. Int J Cardiol. 2012;155(3):406–8.
Schofield D, Shrestha R, Percival R, Passey M, Callander E, Kelly S. The personal and national costs of CVD: impacts on income, taxes, government support payments and GDP due to lost labour force participation. Int J Cardiol. 2013;166(1):68–71.
Bloom DE, Chatterji S, Kowal P, Lloyd-Sherlock P, McKee M, Rechel B, et al. Macroeconomic implications of population ageing and selected policy responses. Lancet. 2015;385(9968):649–57.
Acknowledgements
We thank the ASPREE trial staff and participants, and the general practitioners and staff of the medical clinics who cared for the participants. And we acknowledge the work of the New Zealand Vascular Informatics and Epidemiology using the Web (VIEW) research programme for collation and curation of the PREDICT data.
Funding
Open Access funding enabled and organized by Projekt DEAL. The work was supported by grants (U01AG029824 and U19AG062682) from the National Institute on Aging and the National Cancer Institute at the National Institutes of Health, by grants (334047 and 1127060) from the National Health and Medical Research Council of Australia, and by Monash University and the Victorian Cancer Agency. The PREDICT validation data was supported by Health Research Council of New Zealand project grants 03/183, 08/121, and programme grant 11/800. J.N. is recipient of a research fellowship by the Deutsche Forschungsgemeinschaft (NE 2165/1–1). C.M.R. is supported through a NHMRC Principal Research Fellowship (APP 1136372). KKP holds the New Zealand Heart Foundation Hynds Senior Fellowship.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Andrew M. Tonkin and John J. McNeil contributed equally and should be considered as shared last authors.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Neumann, J.T., Thao, L.T.P., Callander, E. et al. Cardiovascular risk prediction in healthy older people. GeroScience 44, 403–413 (2022). https://doi.org/10.1007/s11357-021-00486-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11357-021-00486-z