Download presentation
Presentation is loading. Please wait.

1
Linux in High-Availability Environments
Alan Robertson IBM Linux Technology Center October 2005

2
OSS in HA Environments Why OSS for High Availability Environments?
What is High-Availability (HA) Clustering? What can HA do for me? DRBD Data Replication The Linux Virtual Server Load Balancer The Linux-HA project? Linux-HA applications and customers Thoughts about cluster security
 Clustering What can HA do for me DRBD Data Replication. The Linux Virtual Server Load Balancer. The Linux-HA project Linux-HA applications and customers. Thoughts about cluster security.")
3
Why OSS In High-Availability Environments?
Openness Broad Range Of Environments Stability Breadth of Support Options Lack of Vendor Lock-In

4
Openness Extensive Peer Review System
Source code freely available Source code reviewed by outside parties Changes discussed openly – often in great detail Ability to obtain uncensored product information Mailing lists archives contain contain uncensored comments from Users with deep expertise Users with little expertise Users who are very happy Users with problems

5
Broad Range of Environments
OSS typically runs on many platforms, often on different OSes too Users often find very creative uses for the software Freedom to try something at low cost decreases perceived risks and encourages this behavior Creative uses find their way into mailing list (archives) and sometimes into the OSS product
 and sometimes into the OSS product.")
6
Thoughts about Stability
OSS software is commonly perceived as being more stable than much commercial software Close contact between customers and developers encourages fixes to be developed quickly OSS users help with testing – providing more breadth in test environment and lowering testing costs Typical commercial support optimized to keep fixes out of the product – testing costs are a big factor

7
Support for OSS Systems
Mailing lists consist of hundreds to thousands of users who are very knowledgeable and helpful – usually regarded as very responsive – typically located in most time zones across the world Can choose support vendor freely: Hardware, OS or OSS supplier Independent consulting/support organizations In-house expertise (most motivated) OSS mailing lists Any combination of the above
 OSS mailing lists. Any combination of the above.")
8
No Vendor Lock-In Does not rely on a vendor's future plans being compatible with yours (risk mitigation) Obsolescence more readily manageable Does not rely on a single vendor in another company or country Contributing to the product (or paying someone else to) provides you a voice in future direction Compatibility with other systems typically better than with proprietary products
 provides you a voice in future direction. Compatibility with other systems typically better than with proprietary products.")
9
What Is HA Clustering? A group of computers which cooperate and trust each other to provide a service even when cluster components fail When one machine goes down, others take over its work This involves IP address takeover, service takeover, etc. New work comes to the “takeover” machine Not primarily designed for high-performance

10
What Can HA Clustering Do For You?
It cannot achieve 100% availability – nothing can. HA Clustering designed to recover from single faults It can make your outages very short (improving MTTR) From about a second to a few minutes It is like a Magician's (Illusionist's) trick: When it goes well, the hand is faster than the eye When it goes not-so-well, it can be reasonably visible A good HA clustering system adds a “9” or two to your availability 99->99.9, >99.99, >99.999, etc. Complexity is the enemy of reliability!
 From about a second to a few minutes. It is like a Magician s (Illusionist s) trick: When it goes well, the hand is faster than the eye. When it goes not-so-well, it can be reasonably visible. A good HA clustering system adds a 9 or two to your availability. 99->99.9, 99.9->99.99, >99.999, etc. Complexity is the enemy of reliability!")
11
The Desire for HA systems
Who wants low-availability systems? Why are so few systems High- Availability?

12
Why isn't everything HA? Cost Complexity

14
Single Points of Failure (SPOFs)
A single point of failure is a component whose failure will cause near-immediate failure of an entire system or service Good HA design eliminates of single points of failure

15
How Does HA work? Manage redundancy to improve service availability
Like a cluster-wide-super-init on steroids Even complex services are now “respawn” on node (computer) death on “impairment” of nodes on loss of connectivity for services that aren't working (not necessarily stopped) managing very complex dependency relationships
 death. on impairment of nodes. on loss of connectivity. for services that aren t working (not necessarily stopped) managing very complex dependency relationships.")
16
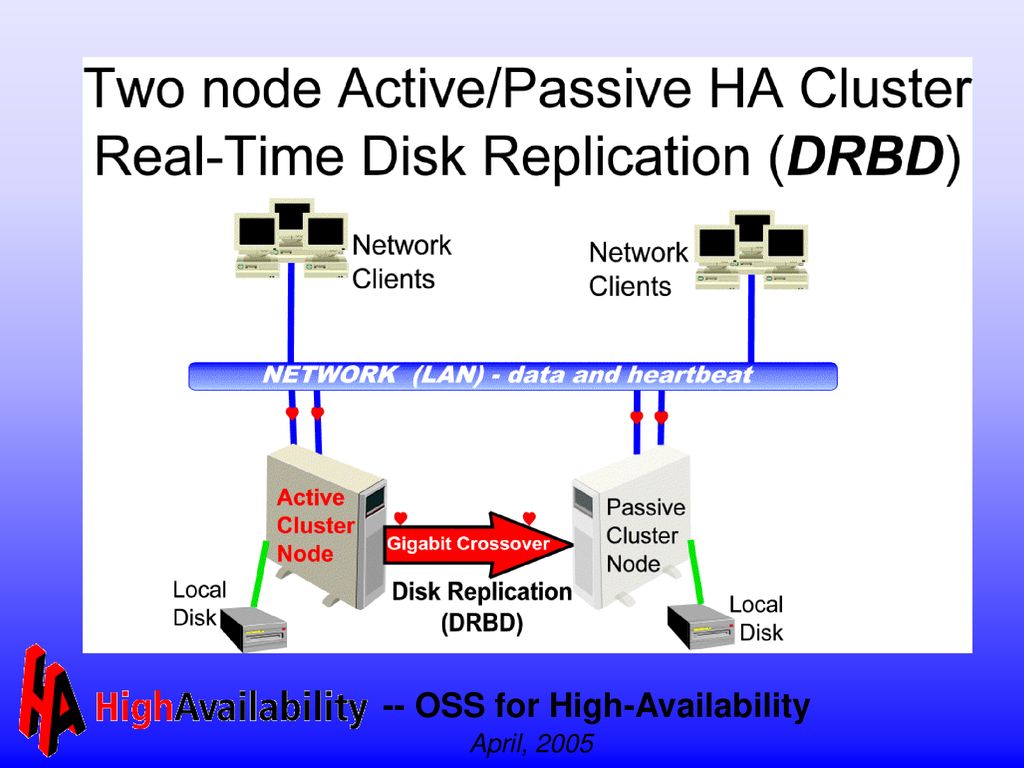
DRBD – RAID over the LAN Block-device (filesystem) level replication
Clever synchronization methods make resyncs faster, decrease latency, preserve integrity Useful for both HA and Disaster Recovery NO single point of failure Extremely cost-effective $200 (max) instead of $20,000 (min) ($USD) Probably not suitable for some high-end write- intensive applications Supportable by IBM Support Line
 instead of $20,000 (min) ($USD) Probably not suitable for some high-end write- intensive applications. Supportable by IBM Support Line.")
18
LVS – The Linux Virtual Server Project
LVS is the standard Linux Load Balancer Called "ipvs" in the standard Linux kernel Stable, fast, flexible Especially suitable for large "server farms"

19
LVS IN Action

20
“Plays Well With Others”
Each of these independent services can work together to scale to large systems All single points of failure can be eliminated High-Availability, Load Balancing work together nicely

21
Linux Virtual Server, Linux-HA and DRBD

22
The Linux-HA Project Linux-HA is the oldest high-availability project for Linux, with the largest associated community The core piece of Linux-HA is called “heartbeat” (though it does much more than heartbeat) Linux-HA has been in production since 1999, and is currently in use on about ten thousand sites Linux-HA also runs on FreeBSD and Solaris, and is being ported to OpenBSD and others Linux-HA is shipped with every major Linux distribution except one.
 Linux-HA has been in production since 1999, and is currently in use on about ten thousand sites. Linux-HA also runs on FreeBSD and Solaris, and is being ported to OpenBSD and others. Linux-HA is shipped with every major Linux distribution except one.")
23
Linux-HA Release 1 Applications
Database Servers Load Balancers Web Servers Custom Applications Firewalls, routers, DNS, DHCP Retail Point of Sale Solutions Authentication File Servers Proxy Servers Medical Imaging Almost any type server application you can think of – except SAP

24
Selected Linux-HA customers
Los Alamos (US) National Labs – linear accelerator badge reader Emageon – medical imaging for hospitals and clinics ISO New England manages power grid using ≈ 20 Linux-HA clusters Various Firewall, DNS, DHCP products use Linux-HA basically embedded Karstadt, Circuit City, Autozone use Linux-HA in each of several hundred stores MAN Nutzfahrzeuge AG – truck manufacturing division of Man AG Autostrada – 230 clusters across Italy BBC – Internet Infrastructure Citysavings Bank in Munich (infrastructure) Bavarian Radio Station (Munich) coverage of 2002 Olympics in Salt Lake City The Weather Channel (weather.com) Sony (manufacturing) Incredimail bases their mail service on Linux-HA on IBM hardware University of Toledo (US) – 20k student Computer Aided Instruction system
 National Labs – linear accelerator badge reader. Emageon – medical imaging for hospitals and clinics. ISO New England manages power grid using ≈ 20 Linux-HA clusters. Various Firewall, DNS, DHCP products use Linux-HA basically embedded. Karstadt, Circuit City, Autozone use Linux-HA in each of several hundred stores. MAN Nutzfahrzeuge AG – truck manufacturing division of Man AG. Autostrada – 230 clusters across Italy. BBC – Internet Infrastructure. Citysavings Bank in Munich (infrastructure) Bavarian Radio Station (Munich) coverage of 2002 Olympics in Salt Lake City. The Weather Channel (weather.com) Sony (manufacturing) Incredimail bases their mail service on Linux-HA on IBM hardware. University of Toledo (US) – 20k student Computer Aided Instruction system.")
25
Linux-HA Release 1 capabilities
Supports 2-node clusters Can use serial, UDP bcast, mcast, ucast comm. Fails over on node failure Fails over on loss of IP connectivity Capability for failing over on loss of SAN connectivity Limited command line administrative tools to fail over, query current status, etc. Active/Active or Active/Passive Simple resource group dependency model Requires external tool for resource monitoring SNMP monitoring

26
Linux-HA Release 2 capabilities
Built-in resource monitoring Support for the OCF resource standard Much Larger clusters supported (>= 8 nodes) Sophisticated dependency model with rich constraint support (resources, groups, incarnations, master/slave) (needed for SAP) XML-based resource configuration Configuration and monitoring GUI Support for cluster filesystems (GFS, OCFS, etc.) Multi-state (master/slave) resource support Initially - no IP, SAN monitoring
 Sophisticated dependency model with rich constraint support (resources, groups, incarnations, master/slave) (needed for SAP) XML-based resource configuration. Configuration and monitoring GUI. Support for cluster filesystems (GFS, OCFS, etc.) Multi-state (master/slave) resource support. Initially - no IP, SAN monitoring.")
27
Resource Objects in Release 2
Release 2 supports “resource objects” which can be any of the following: Primitive Resources OCF, heartbeat-style, or LSB resource agent scripts Resource Incarnations – need “n” resource objects - somewhere Resource groups – a group of resources with implied co- location and linear ordering constraints Multi-state resources (master/slave) Designed to model master/slave (replication) resources (DRBD, et al)
 Designed to model master/slave (replication) resources (DRBD, et al)")
28
Basic Dependencies in Release 2
Ordering Dependencies start before (implies stop after) start after (implies stop before) Mandatory Co-location Dependencies must be co-located with cannot be co-located with
 start after (implies stop before) Mandatory Co-location Dependencies. must be co-located with. cannot be co-located with.")
29
Resource Incarnations
Resource Incarnations allow one to have a resource which runs multiple (“n”) times on the cluster This is useful for managing load balancing clusters where you want “n” of them to be slave servers Cluster filesystems Cluster Alias IP addresses
 times on the cluster. This is useful for managing. load balancing clusters where you want n of them to be slave servers. Cluster filesystems. Cluster Alias IP addresses.")
30
Security Considerations
Cluster: A computer whose backplane is the Internet If this isn't scary, you don't understand... You may think you have a secure cluster network You're probably mistaken now You will be in the future

31
Secure Networks are Difficult Because...
Security is not often well-understood by admins Security is well-understood by “black hats” Network security is easy to breach accidentally Users bypass it Hardware installers don't fully understand it Most security breaches come from “trusted” staff Staff turnover is often a big issue Virus/Worm/P2P technologies will create new holes especially for Windows machines

32
Security Advice Good HA software should be designed to assume insecure networks Not all HA software assumes insecure networks Good HA installation architects use dedicated (secure?) networks for intra-cluster HA communication Crossover cables are reasonably secure – all else is suspect ;-)
 networks for intra-cluster HA communication. Crossover cables are reasonably secure – all else is suspect ;-)")
33
References http://linux-ha.org/ http://linux-ha.org/download/

34
Legal Statements IBM is a trademark of International Business Machines Corporation. Linux is a registered trademark of Linus Torvalds. Other company, product, and service names may be trademarks or service marks of others. This work represents the views of the author and does not necessarily reflect the views of the IBM Corporation.

Similar presentations


 to –complex global system(thousands PCs) Distinguish by the distances that the network.>")








 An enterprise-wide plan for managing and implementing corporate data assets.>")








