
Truly agile estimation - more than one way to peel an orange

Estimation is a thorny, divisive topic amongst agile practitioners. It helps to agree on the value you're seeking from the process and on the fundamentals of agile estimation concepts. There are a number of strategies you can employ to make estimation effective.
- To estimate project scope at the end of an inception, use warp speed estimation or Nigel Thurlow's large effort estimation to conduct efficient, synchronous estimation workshops.
- You can play the velocity game asynchronously using online forms, so you can forecast your team's raw velocity.
- Contingency planning doesn't need to be synchronous. Project managers can use data from estimation sessions and the velocity game to asynchronously assemble the plan.
- When in development, avoid estimation meetings. Instead, use online forms to gather estimates and conduct meetings only if the estimates vary wildly.
- If your stakeholders only want a measure of productivity, drop estimates and measure story througput and cycle time instead.
- Teams that are building an established product can drop estimates altogether and consider Ryan Singer's "Shape up" approach to drop estimation and adopt a lightweight planning approach.
Before starting any conversation about estimation, I’d be remiss not to acknowledge how polarising a topic this is. There are practitioners who believe that estimates are a software development legacy we can do without. In other words, we estimate because we’ve always estimated. The practitioners on this side of the fence say that estimates have no inherent value, particularly because:
they’re guesses, and these guesses are usually wrong.
and what you estimate usually changes, since scope is never a constant.
This argument isn’t without merit. Let’s consider a few data points. The Standish Chaos report of 2015 reported a few startling facts about our industry.
56%
projects were not on budget
60%
projects were not on time
44%
projects did not satisfy their clients or their users
Critics of estimation say that you lose precious time estimating when you could instead execute. “Working software is the primary measure of progress.”, as the Agile manifesto says, so why not focus on that instead? The idea is to use the team’s actual progress to forecast their achievements in the future.
On the other side of the fence, there are practitioners who admit that estimates are often wrong. We just need to do them better. There are many reasons you need estimates.
Stakeholders may need estimates to make a go/ no-go decision. Organisations need to examine their spending appetite for a project and estimates help with that.
In many organisations, there are interdependencies between teams. By providing estimates, one team can let another team know when they can expect to resolve these dependencies.
In my world of professional IT consulting, clients may need estimates from service providers to decide who to contract. I admit this isn’t ideal, and has all sorts of conflicts of interest, but let’s acknowledge that reality before we think about fixing it.
Many teams also use estimates to measure productivity. They do so by quantifying scope complexity through estimates and then showing how much scope they’ve delivered over time. This is not the only way to measure productivity, but for now let’s acknowledge the practice.
Of course, I’d be lying if I told you that asynchronous work will sort out these debates for you and fix the problems of our industry. So, in today’s post, we’ll examine a few realities and how you can include asynchronous or pragmatically synchronous estimation techniques in those situations. Or do away with estimates altogether! Identify the situation that closely resembles your own. Part advocate, part guerrilla - that’s our approach to change. Be a guerrilla and improve your situation. If you also identify a state you’d like to be in sometime in the future, be an advocate and make the case for it.
Fundamentals, fundamentals, fundamentals

“You've got to get the fundamentals down, because otherwise the fancy stuff is not going to work.”
Before we get into any more detail about what’s an already confusing topic, let’s agree on a few fundamentals. Estimates try to address three key questions and typical agile teams answer these questions with a few common practices. Let’s explore each of these.
How big is it?
Most agile teams separate the notion of time and size. There are a few reasons to do this.
You take away the skills and experience of the person providing the estimate out of the equation. Different people on the same team could take varying amounts of time to complete the same work. This is irrespective of the inherent complexity of the work.
People feel under pressure when you ask them to estimate time. One may feel they need to give a lower time estimate, if only to seem competent.
We can all be victims to the planning fallacy; a term Daniel Kahneman and Amos Tversky coined. Our predictions about how much time a certain piece of work will take suffer from an optimism bias. We usually underestimate the time we’ll need.
To decouple size and time, agile teams apply the practice of “relative sizing”. To size one user story for example, you compare its complexity to another reference story and assign it a size. A common measure of relative size is “story points”. How big a story point is, differs from team to team. However, within a team the understanding of what is one story point should be consistent.
So, two story points are exactly two times as big as one story point and three story points are three times as big. When you already have a reference story that’s, say, one story point big, you can compare another story to it and say how big it is in relation.
How fast can we build it?
This is a question teams often must address when starting a large piece of work. By this point teams would have already built a cumulative notion of how big the scope of work is, using relative sizing.
Agile teams play the “velocity game” to answer this question. As a prerequisite, the team agrees on two parameters:
how long each sprint will be.
and an assumption of team size, i.e., the number of developers.
Next, the team hides all estimates and tries to fill up a few such sprints to capacity. The key here is to stop adding stories to a sprint when it “feels full”. The facilitator can then reveal the estimates and take an average of the sum of estimates across sprints. This average is what we refer to as “raw velocity” - i.e., the number of story points a team of a certain size can deliver per sprint, in ideal conditions.
Sometimes teams repeat the exercise till they feel comfortable with the raw velocity.
How risky is our plan?
The raw velocity is rarely the true velocity of the team. There are many factors that can affect the actual velocity of the team when it’s in flight.
Team capacity can vary depending on holidays, vacations, training events or sickness. Certain individuals may be part of the team only in a part time capacity.
Production issues can take away development capacity as well.
Depending on the team’s maturity with continuous delivery, each release can generate an overhead of work that'll slow the team down.
Churn in the team can also impact velocity. New people will take time to contribute to the team at full capacity. Adding new people doesn’t always make the team faster either. Communication complexity can slow the team down.
Moreover, the scope you’ve agreed will change as well. This is an inevitability. There are two reasons for this.
You don’t understand the full complexity of the scope you’re aware of.
You’ve not uncovered all the scope you need to deliver.
At first blush, this may seem like a bad thing, but most agile practitioners will agree that this is a feature of agile development and not a bug! First, we’re able to avoid big upfront design and analysis by leaving scope negotiable. Second, we’re able to keep ourselves open to feedback from both the market and the team so we make decisions in the interest of the product. So, scope variation is not just unavoidable, it’s necessary.
Project managers, however, need to take velocity and scope variation into account and they do so with “contingency planning”. They quantify these variations and build optimistic, likely, and pessimistic versions of the plan so they’re transparent with stakeholders about these risks.
A reading of these questions and the associated practices to answer them, should lead us to a few conclusions.
You can make meaningful estimates only when you break requirements down into smaller, constituent parts, such as user stories. This needs analysis and the team needs to engage with the problem deeply. This is why estimates from a sales proposal are less meaningful than estimates from an inception.
All practices don’t need a synchronous implementation. For example, contingency planning can be a quiet, asynchronous activity.
Every team and every project will not need all these practices. Each activity I described in the table above takes time to execute and certain teams may see more value in using that time to build software instead.
Last but certainly not least, we’ve discussed earlier that scope is the only true negotiable. Delivering “all the scope” is a myth and that’s a good thing. Agile teams benefit from delivering early and often and getting fast feedback. Even if that’s at the cost of reduced scope. Effective project managers fix time, cost and quality and flex scope instead.
What’s wrong with synchronous estimation?

A typical deck of planning poker cards.
Before we dive into estimation techniques, let’s ask ourselves what problem we’ve set out to solve. Synchronous estimation on agile teams follows a wideband Delphi or a mini-Delphi technique (estimate, talk, estimate). If that sounds like gobbledegook, allow me to explain. Agile teams play a “game” called “planning poker”. The product owner or the business analyst has a bunch of stories that need estimates. Depending on the state of the project, these stories may just have broad assumptions, or they could be fully detailed. The developers in the estimation session provide the estimates. Here’s how the process unfolds.
Each developer has a stack of planning poker cards. The cards each have a number on them corresponding to the same number of story points. These numbers often follow a Fibonacci sequence, i.e., 1, 3, 5, 8, 13. When a developer plays one of these cards, it’s their estimate for the user story in question. There are many variations to this - e.g., writing estimates on index cards and online, just typing the estimate into a chat box.
The product owner reads out the story. The developers can ask questions to clarify their understanding of the story.
Each developer then lays down a card representing their estimate, face down on the table. Face down, so they don’t influence anyone else. These estimates should be proportional to previously identified reference stories.
Once everyone’s laid their cards on the table, everyone gets to flip them at the same time to reveal the estimates. In a remote, synchronous setting, people may combine steps #3 and #4 by sharing their estimates in a chat box at the count of three.
If everyone agrees with each other’s estimates, the product owner makes a note of them and records the estimate against the user story. If estimates vary widely however, the team discusses their difference in opinion. They then repeat the process until they arrive at some consensus. Estimate, talk, estimate. Product owners can choose to time-box these discussions using a timer.
This process repeats for every single story in the list for that estimation session. Anyone who has been in such a session knows that these meetings can go on forever. Despite the best efforts to limit bias there can often be bias cascades where if someone influential speaks first, their opinion sways the opinions of the rest of the group. This doesn’t just affect the estimate of a single story but can influence an entire estimation session.
To get over these disadvantages, I have a few broad suggestions and the techniques I’ll suggest are in line with those suggestions.
At the start of a project, during or right after an agile inception, the team isn’t yet doing development work. If anything, the team’s doing a mix of workshops and synthesis. In these situations, synchronous estimation works, especially if you optimise for speed. I’ll show you two techniques to estimate a large backlog in a short amount of time.
Once you start development, synchronous estimation interrupts your team’s flow. I can’t remember a single developer I’ve worked with who enjoys these sessions. You may find yourself in one of two possible project situations.
If the initial estimates were primarily for a go/ no-go or a budgeting decision but the client or the stakeholder doesn’t need you to correlate every story back to those initial numbers.
You need to correlate the estimate of each story back to the estimates you generated at the start. This is so you can quantify and log scope change and report how much scope you’ve delivered from the originally agreed plan.
If you have an established product and your management team cares more about the value you deliver to your customers than the estimates for each story, you can drop the estimation process altogether. I’ll show you how such a process could work in practice.
Now that we’ve got some of the fundamentals out of the way, let’s explore how to execute some of these techniques in an async-first agile environment.
Estimating size at the start of a project
Make speed your ally. The most important fact to remember about estimates is that they’re guesses. Agile estimation methods already build in some risk mitigation. For example, when you use a Fibonacci series (1,2,3,5,8,13…) you recognise that the larger the estimate the more likely that you’ve overlooked some complexity. So, the next estimate after 5 is an 8. The estimate after 8, is 13.
Second, you’re not trying to estimate the project as a whole. You’re breaking down the project into its constituent parts and using the sum of estimates instead. This gives you another level of de-risking. So don’t fuss over being precise with your low-level estimates. Instead, you want to be accurate with your overall project estimate. With that said, let me describe two speedy techniques to get reasonably accurate project estimates after an inception.
Technique 1 - warp speed estimation

Identify the smallest story and designate it as the 1-point reference.
This is a technique that I’ve used many times with success. There are a few steps to this technique. It all starts with the backlog you’ve derived from your inception. You’ll need to use an electronic whiteboard for this exercise. First, organise the stories into t-shirt sized buckets as you see in the image above. Your t-shirt sizes can be small, medium, large, and extra-large.
Second, identify the smallest of the small stories. Remember, relative sizing starts with a frame of reference - so this becomes your reference one point story. Now you can get a bit finer grained with your estimates.

Divide the tshirt-sized buckets further into Fibonacci lanes.
It’s time to divide the t-shirt sized buckets further. The image above shows how you can do this.
Divide the small bucket into two buckets of 1 point and 2 points each.
Designate the medium as 3 points.
The large bucket represents 5 points.
Label the extra-large bucket as 8 points.
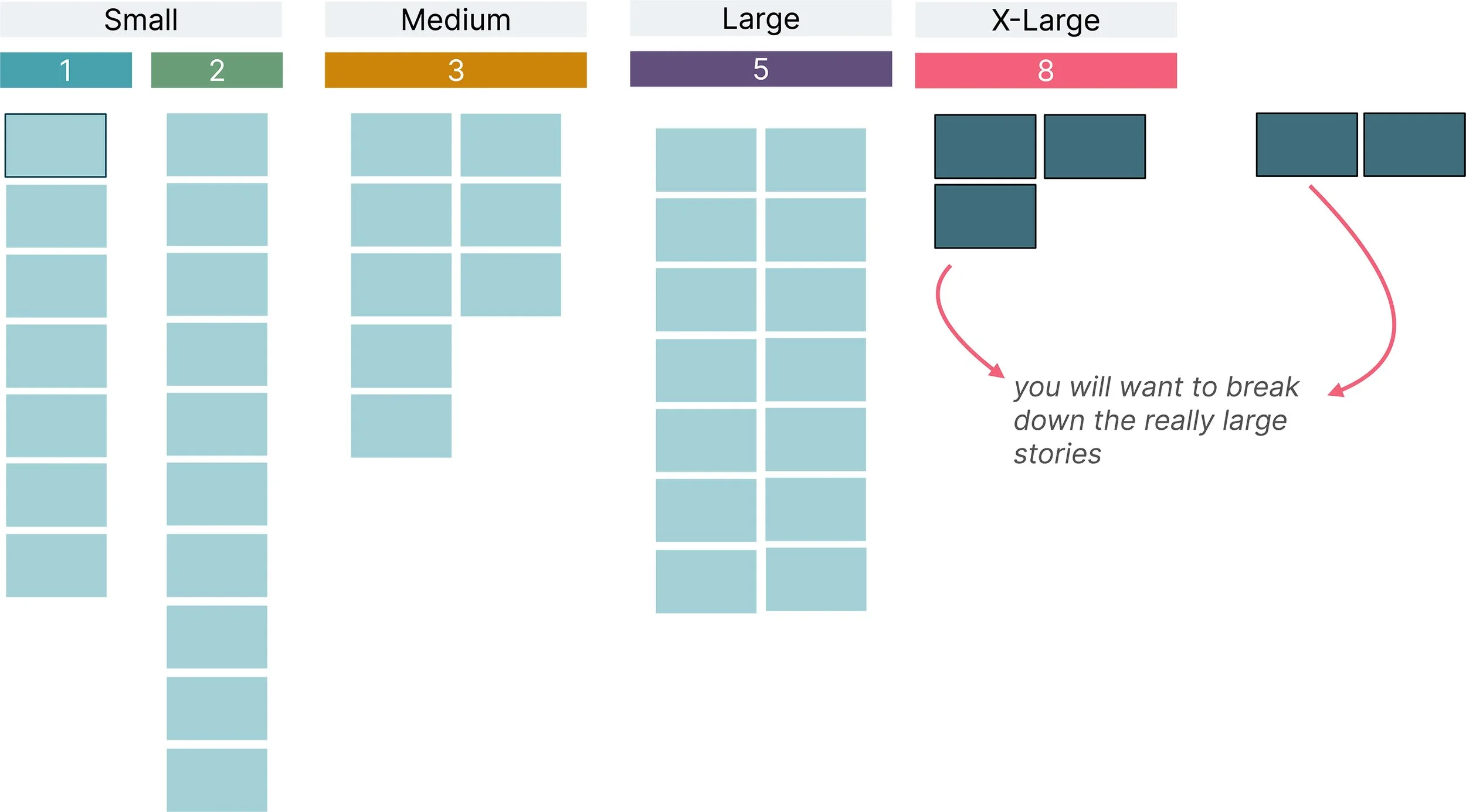
Move stories into roughly the right lanes and break down the large stories.
This is where you and your team should examine the buckets closely and move stories into what seems roughly the right lane. Remember, it’s not about precision. If it looks bigger than a 3, but smaller than an 8, chuck the story into the 5 lane. Once you reorganise your stories into these new lanes your board will look a bit like the image above. You’ll probably also end up with some big stories. You should break them down and then work with your developers to add them to the right lane. The rule of thumb I follow is to break down anything that’s 8 points or larger. This helps spread the risk across multiple smaller stories.
Once you feel comfortable with the overall grouping, you can sum the estimates and you’ll have a notion of raw scope. A project manager still needs to do all the contingency planning, but you’ve completed the foundational estimation work.
Technique 2 - Nigel Thurlow’s large effort estimation

Structure your backlog across levels like in a user story map.
This next technique isn’t mine. Nigel Thurlow and Dave Slayton came up with this approach at Toyota. The technique works very well in conjunction with Jeff Patton’s story mapping technique. No worries if you aren’t familiar with that. You need to structure the product backlog from your inception at three different levels.
Themes - these can be categories, features, or system capabilities.
Epics - these are large stories that are just too big to deliver in a single sprint.
Stories and tasks - these are fine grained items that you can deliver within a sprint.

Size your themes and epics independently from one another.
Once you have your three-tier backlog in place, you need to relatively size the themes. Let’s imagine a backlog with three themes, which your developers have sized at 5, 8 and 3 respectively. Next you need to independently size the epics under any one of the epics. By “independently”, I mean that the sizes at a level have nothing to do with the level above or below it. Let’s take the theme sized “3” and assume that the epics under it have the sizes 1,3 and 5. Your estimated story map should look a bit like the above diagram now.

Estimate the stories under one epic
Next, pick any of the epics and independently size the stories and tasks underneath it. In the interest of simplicity let’s take the epic sized “1” in our example. Let’s imagine that the sum estimates for stories underneath that epic is 8 points. This is where you can start extrapolating. Let’s estimate the entire backlog for the example we’re discussing.
3 theme points = 9 epic points
Therefore, 1 theme point = 3 epic points
1 epic point = 8 story points
Therefore 1 theme point = 3 epic points = (3 x 8) story points = 24 story points
Our entire backlog has three themes.
The sum of theme points = 5 + 8 + 3 = 16
Therefore, the size of the entire backlog (24 story points per theme point) = 16 x 24 = 384 story points
And there you have it. By diving deep into one epic from your story map you can extrapolate your estimates to the entire backlog. Nigel says that you don’t need to do more than one chunk. It doesn’t make you any more accurate.
“We found that just taking one chunk, breaking that all the way down to user stories and then being able to extrapolate that to size; was around 90% accurate, we couldn't get it to be any worse than that. We thought, well, if it was 70% accurate, we'd be happy. But in the end, it turned out we were incredibly accurate.” - Nigel Thurlow
Both these methods are incredibly fast to execute. They make for efficient, synchronous workshops to size your initial backlog and get a sense of your raw scope. Next you have a choice. Whether to play the velocity game synchronously or asynchronously.
Playing the velocity game asynchronously
I’ve already described how to play the velocity game synchronously. To play the game asynchronously all you need to do is create a form with a random list of 20 stories from your backlog. Represent each of these stories as a checkbox item underneath the following question.
“Select all the stories you think we can complete in a sprint of two weeks, with a team of 1 dev pair.”
You can create a spreadsheet with this same list of stories and any details you know about them at this point. Provide the link in the form itself. That way if the developer looking at the form needs to inspect the details they know where to look. Just make sure you don’t reveal the estimates.
Send the form to the developers who are on the team right now and have them fill out the form independently. You can include multiple pages on the form with different story sets, so you can simulate multiple runs of the velocity game.
Once the developers have responded to the survey, compute the sum of story sizes for each sprint they’ve filled and take an average. That average will represent the raw velocity for your project. A project manager can now use your raw scope, the raw velocity and the team’s prediction of scope change or scope addition, to build a contingency plan and a forecast.
Estimating stories in flight
When your project is in flight though, your team needs as few interruptions as possible. People want to do deep work, in a state of flow. Long estimation meetings are the last thing you want at this stage. It’s also a reality that some projects need to report how much scope (in story points) they’re delivering in each sprint. Not only is this a measure of throughput, but it also helps:
track where the team is with respect to delivering the initial scope.
and forecast if the team needs to negotiate the scope of the upcoming release, based on what they know of their velocity right now.
These are perfectly legitimate needs from teams, clients, and stakeholders. To answer these, agile teams estimate every story threadbare during standalone estimation sessions or long, sprint planning meetings. A better way is possible. Remember the idea is not to be precise at the story level, but to be accurate at the project level. So, you shouldn’t fuss with minor estimation errors, because over the lifetime of a release errors will cancel out each other. I suggest going back to basics with the wideband Delphi method.
Back in the day when agile still wasn’t a thing, wideband Delphi estimation involved anonymously filling out forms. You can do the same thing now, but more efficiently with online forms. Let’s say you have a list of 10 user stories up for estimation. Here’s how you can go about things.
Create a form with two fields per row. On one field you have the name of the user story. In another field you have a drop-down list for developers to choose their estimate. This drop-down should have the Fibonacci numbers. You can add an optional text field so developers can explain the rationale behind their estimates.
Link the name of each user story to its description on your task board. That way if a developer needs to see the details they know where to look.
Send the form to a few developers and request them to estimate the stories. Give them enough time to respond, otherwise there’s no point doing this asynchronously.
Once all developers have responded, then average out all the estimates to derive the estimate for each story.
Only if estimates for specific stories vary quite wildly between developers, do you need a meeting to discuss differing points of view. In general, if the product owner describes stories clearly and the stories are small, you can reduce the chances of variation.
Be sure to include links to reference stories so your developers know what a 1, 3 and 5 pointer look like. They can use these reference stories to relatively size the stories on hand.
This asynchronous approach will not just save you time, but it’ll also leave a record of your decision-making process for you. By limiting your meetings only to resolve wide differences of opinion, you’ll also ensure that you don’t interrupt your team if it’s not necessary.
Do you really need estimates?
Now that we’ve discussed a bunch of estimation techniques let me tell you what I’d do if I have the chance. This won’t be a surprise because I’ve mentioned this to you when we discussed sprint ceremonies. If you’re not reporting back on a contracted delivery, then your focus as a leader should be on two things.
The ability to deliver continuously. This brings down release pressure, because at least in theory, you can release functionality to your users whenever you want.
Managing an efficient delivery process, characterised by:
High throughput - i.e., stories delivered per sprint.
And a low cycle time - i.e. the time it takes for a “ready for dev” story to get “done”.
The key to this approach is to size all stories similarly. The smaller, the better. You can still negotiate scope at the story and the release level, but your focus is to get more done, fast. No estimates necessary!
Consider using the shape up approach

The “Shape-up” timeline
If you have an established product, then you’re probably less concerned about big release plans. Instead, your priority will be to enhance your product regularly. For such situations, I’m a big fan of Ryan Singer’s “Shape up” approach. This approach has no estimates. No velocity tracking. Not even a backlog. Ryan’s written a book on the topic that goes into details; but let me explain the approach at a high level.
Anyone can come up with ideas to improve the product. Before any of these ideas go into development, a group of people “shape up” the work.
The product of the shaping process is a pitch document. This document summarises the problem, the constraints, the solution, and the go/ no-go areas. It doesn’t have wireframes or mock-ups. No stories, or architectural diagrams either. Designers and developers can figure out those details if they end up working on the problem. The document uses fat marker sketches and box-and-arrow diagrams to illustrate the potential solution.
Not all pitches make it to development. Each cycle, all shaped pitches go to a “betting table”. This is where a team of people who’re responsible to make decisions about a product decide which pitches to bet on. By betting on a pitch, they commit a team for six weeks, solve that problem. Why six weeks? Singer says that it’s long enough for a team of two or three people to finish substantial work and short enough to plan for.
A key feature of the shaping process is the notion of a “capped downside”. The shaping team must be confident that a development team can execute the idea in six weeks. The six-week time-box is also a circuit breaker. If the development team can’t ship in 6-weeks, then it represents a shaping problem. Work stops and the idea goes back into shaping.
The corollary to the capped downside is that development teams get uninterrupted time to work on their problem. They also have the freedom and autonomy to “hammer scope”; i.e., focus only on the absolute must-haves to solve the problem in their six-week cycle.
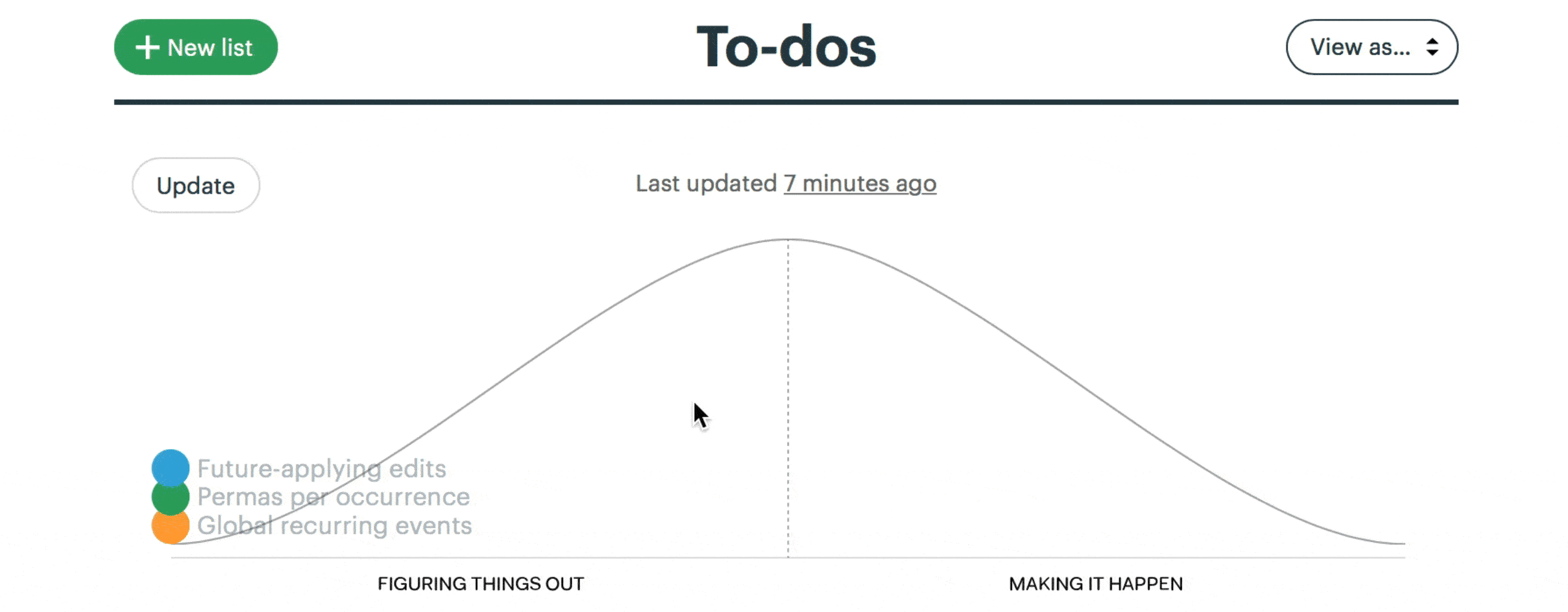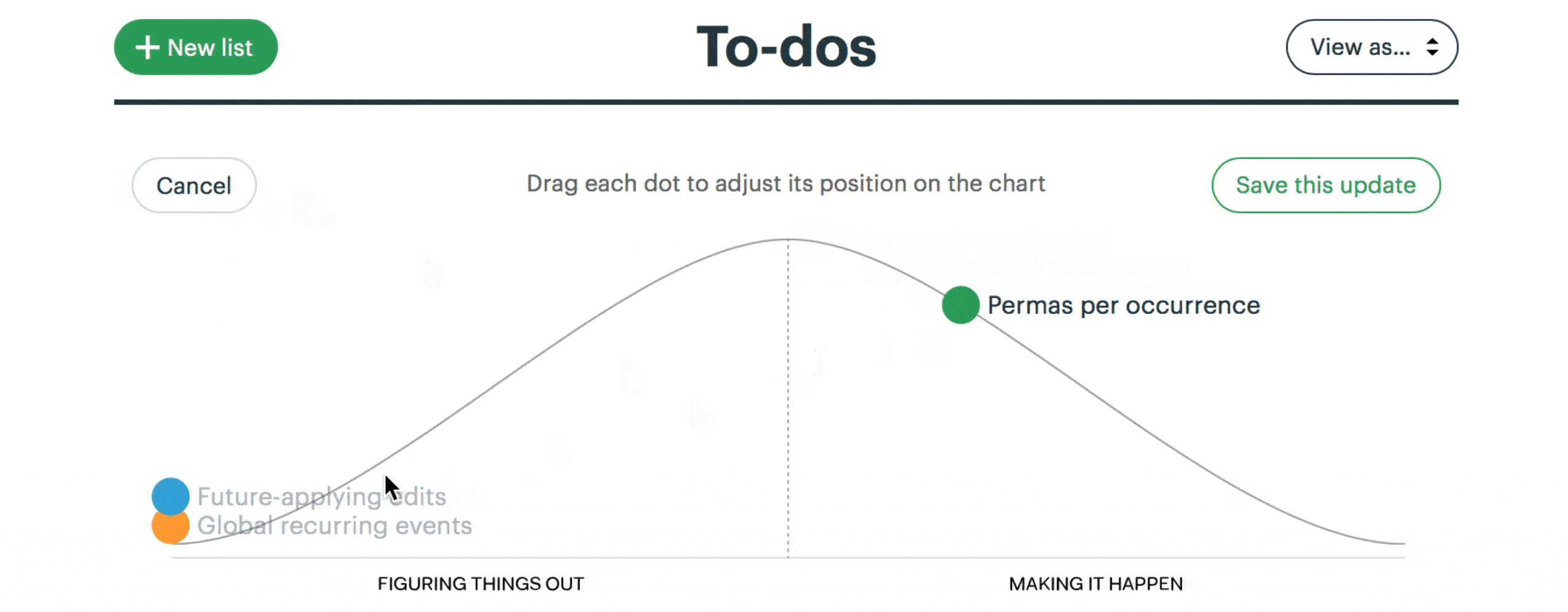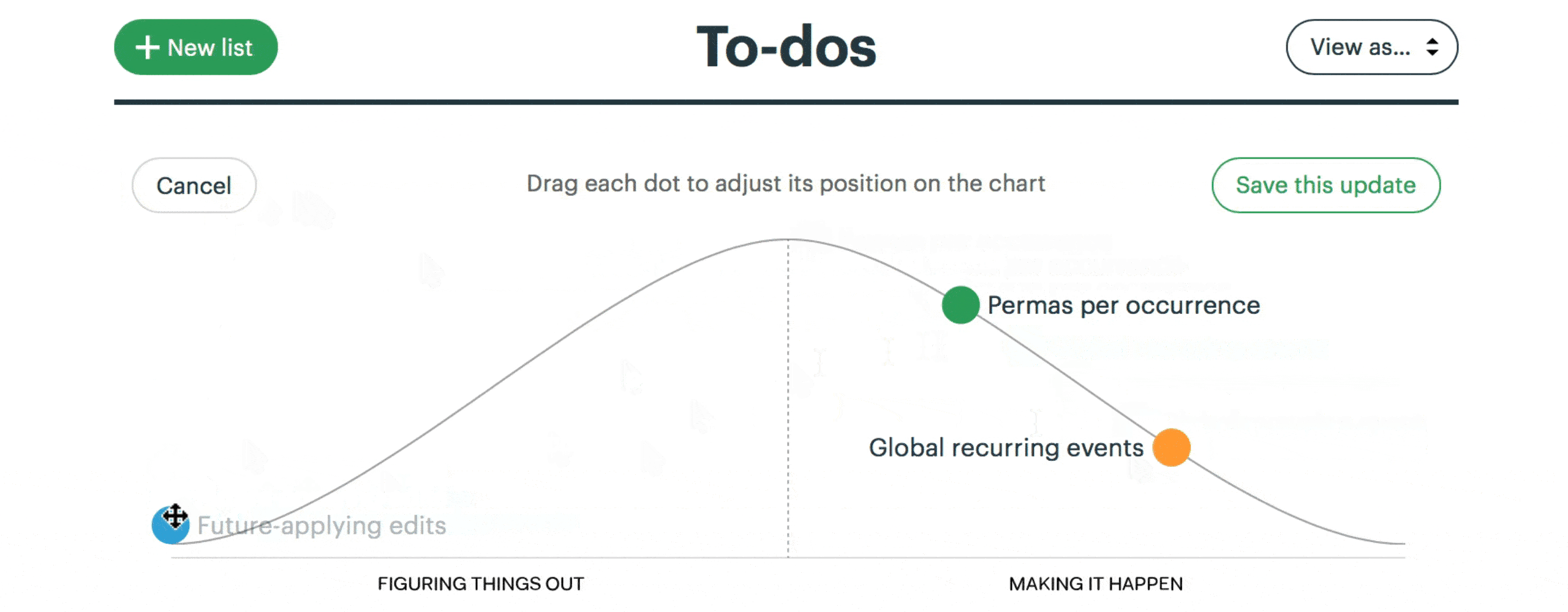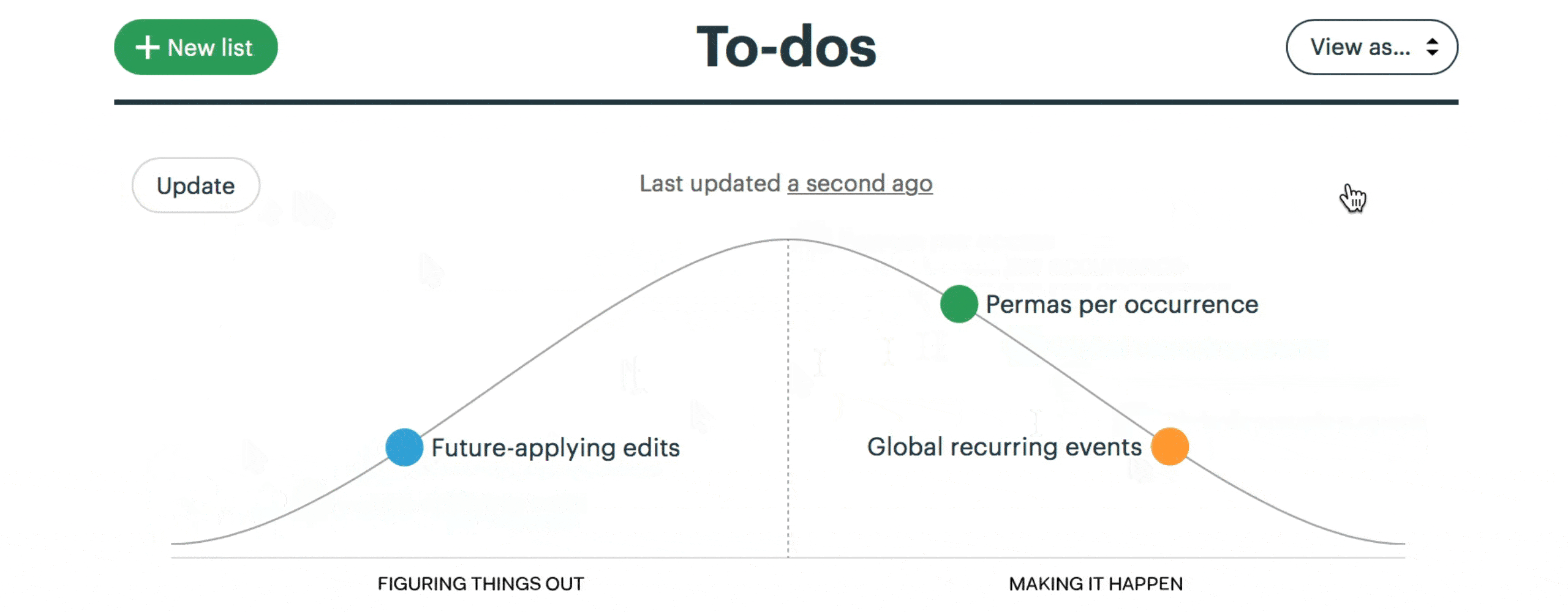
Development teams divide their six-week project into broad scopes and constituent tasks. They communicate status asynchronously and transparently using hill charts. On the left-hand side of the chart are scopes where you’re still figuring out what to do. On the right you’re getting things done. One view with click throughs to detail can show you where the team is at. When you compare different states of the chart you get a sense of progress.
Shape up follows a two-track approach. While development teams hammer away at their respective problems, the shaping team creates pitches to bring to the betting table. At the end of six weeks, the dev teams ship their software into the wild and get two weeks to cool-down. This is time to not just get a breather but to also tie up some loose ends, maybe make some minor bug fixes. This is also the time when the shaping team brings pitches to the betting table. Every eight weeks the cycle repeats itself.
I encourage you to pick up Ryan’s book and read it cover to cover. If you’re responsible for an established product, you’ll find that this approach allows you to facilitate autonomous teams. At the same time, you forecast only a few weeks at a time, to keep your product and your ideas fresh.
Phew! There you have it - estimation ideas for a remote, async-first team. Estimation is always a thorny topic amongst agile practitioners, and I wanted to give it the detail it deserves. Detail of course makes the post longer than I’d have liked, so if you read this far you deserve a medal.
What I’d like you to take away from this post though, is that there are different approaches to estimation and planning depending on the outcomes you’re looking for and the context you’re operating in. As a practitioner or a leader, you may want to influence change in a certain direction when it comes to estimation and planning. In which case I hope this post gives you some ideas to take to work. Estimation is also a practice where we can’t be async-zealots. Meetings are still the last resort, but let’s recognise that in some contexts these meetings may be necessary. And if they are necessary, our job is to make them efficient.
Of course, if you can do away with estimates and adopt a more lightweight method for planning and measuring productivity, then you should go right ahead. That’s where my bias is as well!