Gossip Protocol: Failure Detection in Distributed Systems
A cluster can have multiple nodes communicating to each other based on use cases. To communicate with another node, the current node should be aware of many important things like - API contracts, supported network protocols, the health of the other node (alive or dead), detecting failures, etc.
This article is more about failure detection in distributed systems. In a cluster, a node can fail due to various reasons but another node should be informed about it and avoid any cascading failures.
Before diving deep into failure detection, let's understand about -
How a System can communicate about its health?
Heartbeat(PUSH): The node itself periodically sends heartbeats to some centralized server about their health. If the centralized system does not receive the heartbeat of other nodes for a specified amount of time it registers that node as failed until it starts receiving the heartbeat.

Health API(PULL): Each node exposes a simple health API that returns basic information about the health of the system. Example -
Failure Detection in Distributed Systems:
Now, Let's start with the core concept of this article. To detect failures in distributed systems there can be two ways with which we can achieve this -
A centralized service that has the responsibility of listening to heartbeats or pulling health information about other nodes periodically and keeping the records of all the dead and alive nodes. All communication to other services will route through this centralized service.
Peer-to-peer communication between nodes is another way that we will talk about in detail going forward. This is a scalable and efficient solution.
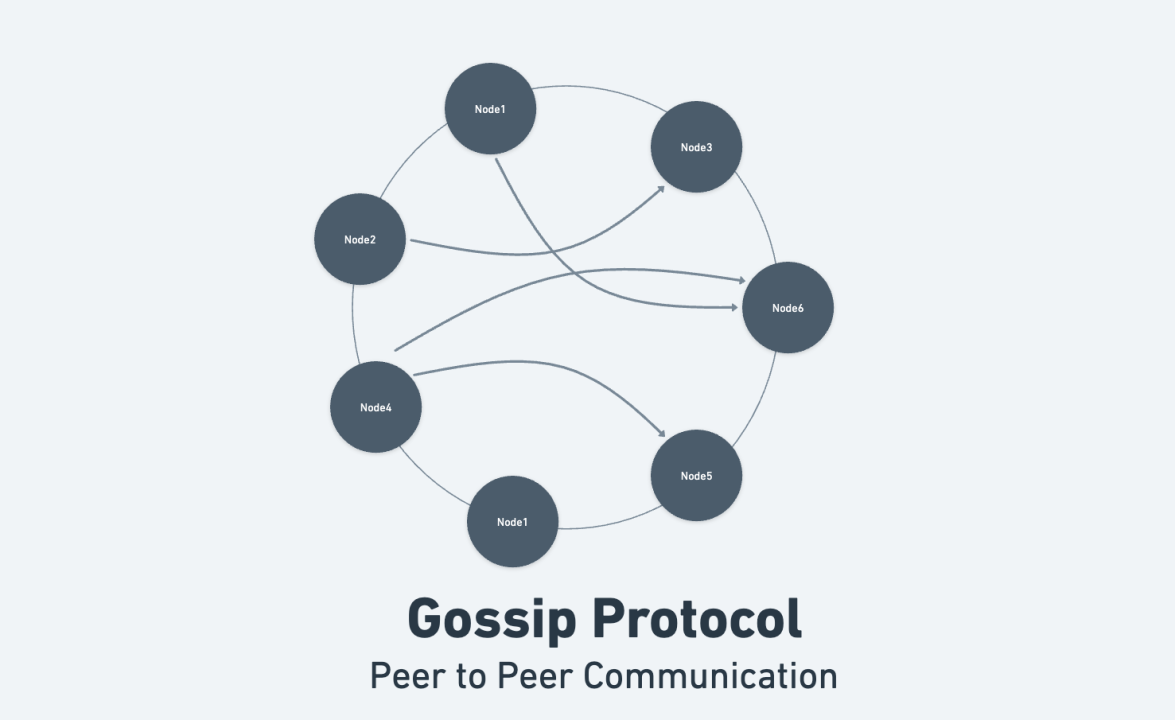
Gossip Protocol to detect failures in the system:
According to the definition from Wikipedia:
A gossip protocol or epidemic protocol is a procedure or process of computer peer-to-peer communication that is based on the way epidemics spread. Some distributed systems use peer-to-peer gossip to ensure that data is disseminated to all members of a group.

So the basic idea is that nodes transmit health data about other nodes to a random node. It sends basic info like the timestamp of the data, health info, etc If a node receives two data about the same node it trusts the recent data and ignores the outdated data.
The node that receives the information does exactly the same thing. The information is periodically sent to N targets, N is called fanout. Metrics are -
Cycle: Number of rounds to spread a rumor.
Fanout: Number of nodes a node gossips within each cycle. When a node wants to broadcast a message, it selects t nodes from the nodes at random and sends the message to them.
With fanout = 1, then O(Log N) cycles are necessary for the update to reach all.
Property | Real estate
8mothank u so much for sharing