
Genomic Analysis of the Rare Slightly Halophilic Myxobacterium “Paraliomyxa miuraensis” SMH-27-4, the Producer of the Antibiotic Miuraenamide A

Department of Applied Biosciences, Graduate School of Bioagricultural Sciences, Nagoya University, Nagoya 464-8601, Aichi, Japan
*
Author to whom correspondence should be addressed.
Microorganisms 2023, 11(2), 371; https://doi.org/10.3390/microorganisms11020371
Submission received: 31 October 2022
/
Revised: 30 January 2023
/
Accepted: 31 January 2023
/
Published: 1 February 2023
(This article belongs to the Section Microbial Biotechnology)
Abstract
:Halophilic/halotolerant myxobacteria are extremely rare bacteria but an important source of novel bioactive secondary metabolites as drug leads. A slightly halophilic myxobacterium, “Paraliomyxa miuraensis” SMH-27-4, the producer of the antifungal antibiotic miuraenamide A, was considered to represent a novel genus. This study aimed to use the whole-genome sequence of this difficult-to-culture bacterium to provide genomic evidence supporting its taxonomy and to explore its potential as a novel secondary metabolite producer and its predicted gene functions. The draft genome was sequenced and de novo assembled into 164 contigs (11.8 Mbp). The 16S rRNA gene sequence-based and genome sequence-based phylogenetic analyses supported that this strain represents a novel genus of the family Nannocystaceae. Seventeen biosynthetic gene clusters (BGCs) were identified, and only five of them show some degree of similarity with the previously annotated BGCs, suggesting the great potential of producing novel secondary metabolites. The comparative genomic analysis within the family Nannocystaceae revealed the distribution of its members’ gene functions. This study unveiled the novel genomic features and potential of the secondary metabolite production of this myxobacterium.
1. Introduction
Myxobacteria are famous for their complex life cycle of multicellular fruiting body formation and cooperative preying behavior. They are considered as a template for the study of bacterial social behavior [1,2,3]. Aside from this, their potential for immense secondary metabolite production also makes them candidates for a next-generation microbial drug factory [4,5,6]. Since their first description as a novel taxon in 1892 [7], myxobacteria were considered terrestrial bacteria until 1998, when the first isolation of obligate halophilic marine myxobacteria was reported by Iizuka et al. [8]. Although the difficulty with isolation and cultivation obstructs the discovery of halophiles, the limited number of strains already shows great potential for producing novel bioactive leads with unique molecular scaffolds and activities [9,10,11,12]. To date, all discovered and cultivable halophilic myxobacteria are grouped into the suborder Nannocystineae, which consists of two families, Kofleriaceae and Nannocystaceae [10].
In 2006, the myxobacterium strain SMH-27-4 was isolated from a near-seashore soil in Japan and tentatively named “Paraliomyxa miuraensis” [13]. The phylogenetic analysis based on a partial 16S rRNA gene sequence suggested that it represents a new genus of the family Nannocystaceae [13,14]. Nannocystaceae is the most ecologically diverse myxobacterial family and, besides Paraliomyxa, contains four genera: two marine-derived genera Plesiocystis and Enhygromyxa, a brackish water genus Pseudenhygromyxa, and a terrestrial genus Nannocystis [15]. In 2016, Iizuka reported the chemotaxonomic and physiological characteristics of the strain SMH-27-4 and provided the descriptions of “Paraliomyxa” gen. nov. and “Paraliomyxa miuraensis” sp. nov. (Reference S1) [14]. The optimal salt concentrations for the growth of “P. miuraensis” SMH-27-4 were determined as 0.5–1.0% (w/v) NaCl, and requires Mg2+ and Ca2+ for its growth [13]. On the agar plate, the strain swarms in a radial pattern and sometimes cleaves the agar gel matrix [14]. The major cellular fatty acids are iso-C15:0 and iso-C17:0. They do not degrade filter papers or grow in a yeast medium, such as VY/2 agar, generally used for terrestrial myxobacteria. The above characteristics were shared with the slightly halophilic myxobacteria Pseudenhygromyxa [14,16]. However, its major cellular quinone is MK-8, and long-chain polyunsaturated fatty acids were not detected. These two properties are the same as the terrestrial strain Nannocystis exedens DSM 71 [14,17]. No distinct fruiting body was observed for this strain, which made it more enigmatic [13,14]. The major secondary metabolite of “P. miuraensis” SMH-27-4, miuraenamide A (Figure 1), exhibited potent antifungal activity, especially against the phytopathogenic oomycete Phytophthora capsici at a minimum inhibition dose of 25 ng/disk by inhibiting the mitochondrial respiratory chain [13]. It was also shown to significantly change the morphology of the cytoplasm and nucleus of a tumor cell line by stabilizing actin filaments [18]. Over the last decade, its total synthesis and biological activity as an actin filament stabilizer have been broadly explored [19,20,21,22,23,24,25,26]. The potential of miuraenamide A for medical applications makes this strain more worthy of investigation.
To confirm the taxonomy of “P. miuraensis” SMH-27-4 as well as the productivity of other secondary metabolites and the distribution of gene functions, we comprehensively analyzed its draft genome sequence.
2. Materials and Methods
2.1. Cultivation and Genomic DNA Isolation
Isolation of “P. miuraensis” SMH-27-4 was previously described [13]. The strain is registered in DBRP as STAJ0000000110262 and deposited in NBRC (Kisarazu, Chiba, Japan) as NBRC 111985. On the VY/2-1/5SWS agar plate [13], the strain swarms in a radial pattern and burrows into the agar. The outer edge of the swarm was cut out of the agar strip and frozen as glycerol stock in 12% (w/v) glycerol solution at −80 °C [14]. After thawing, the glycerol stock was washed with autoclaved Milli-Q water and planted on the Vy5.S75.15 agar plate (see below). The plates were cultured for 14 days at 27 °C. Ten 0.5 cm square agar strips were cut out of the swarm edge and added to 750 mL of N2.0-S75.10 broth (see below) in a 2 L Erlenmeyer flask, which was shaken at 180 rpm. The cells tended to aggregate together, forming cell masses in the liquid broth. After 14 days of cultivation, the broth was filtrated by suction, and the orange or yellow cell mass on the filter paper was collected. Approximately 50 mg (wet weight) of the cells was used for the isolation of genomic DNA by a QIAGEN Genomic-tip 100/G (QIAGEN, Venlo, Nederland) and Genomic DNA Buffer Set (QIAGEN) according to standard protocols.
Vy5.S75.15 medium: 0.5% (w/v) yeast cake, 0.01% (w/v) Bacto™ yeast extract (Thermo Fisher Scientific, Waltham, MA, USA) and 1.5% (w/v) NaCl were suspended in 75% Sea Water Solution (SWS) [8], and pH was adjusted to 7.2–7.4 with 1 M NaOH before autoclaving. Vitamin B12 (0.5 mg/1 mL water) was sterilized by filtration and added to the autoclaved solution (1 L). Yeast cake: Dried yeast (Mitsubishi Tanabe Pharma, Osaka, Japan) was suspended in Milli-Q water (10% (w/v)). The supernatant was discarded after centrifugation (10,000× g rpm, 5 min), and the yeast cake was washed three times with water by suspending, vortexing, and centrifugation. The cake was stored at −30 °C until use. N2.0-S75.10 medium: 2% (w/v) casein sodium (FUJIFILM Wako Pure Chemical Corporation, Osaka, Japan) and 1% (w/v) NaCl were suspended in 75% Sea Water Solution (SWS), and the pH was adjusted to 7.2–7.4 with 1 M NaOH before autoclaving. Vitamin B12 (0.5 mg/1 mL water) was sterilized by filtration and added to the autoclaved solution (1 L).
2.2. Draft Genome Sequencing, Assembly, and Annotation
The whole genome was sequenced using the Illumina HiSeq platform, paired-end, 101 bp X 2 sequencing. The adapter sequence and low-quality bases were trimmed from raw reads files using Cutadapt (version 1.1) [27] and Trimmomatic (version 0.32) [28]. After trimming, sequence reads were assembled into contigs using the de novo genome assembler Velvet (version 1.2.08) [29]. The gapclose module of Platanus (version 1.2.1) [30] was then applied to reduce the N content introduced into the genome during scaffolding. The contigs shorter than 200 bp were removed. Automated annotation of the draft genome sequence was performed with the prokaryotic genome annotation pipeline (PGAP) of NCBI (version 6.3) [31]. The estimated genome size was calculated by KmerGenie (version 1.7051) based on Kmer analysis. The completeness of genome assembly and annotation were assessed using benchmarking universal single-copy orthologs (BUSCO) scores (version 5.3.2) [32].
2.3. Phylogenetic Analysis
The complete 16S rRNA gene sequence was identified by PGAP genome annotation. A dataset of 16S rRNA gene sequences of 52 Myxococcales strains and Desulfovibrio desulfuricans Essex 6 were retrieved from GenBank (Table S1). D. desulfuricans Essex 6 was used as an outgroup to root the tree. The 16S rRNA gene sequences were aligned by MAFFT (version 7.487) [33]. Maximum likelihood analyses were constructed in IQ-TREE (version 2.1.4-beta) [34] using the best-fit model TN + F + R4, selected by the software according to the Bayesian information criterion (BIC) scores. Bootstrap values were based on 1000 replicates, and the obtained tree was visualized using iTOL [35].
The genome sequences of 51 strains of the order Myxococcales were retrieved from the NCBI reference sequence (RefSeq) database (Table S2). The average nucleotide identity (ANI)-based distance tree was produced using the ANI-matrix genome distance calculator [36]. The ANI tree was clustered using the neighbor-joining method.
2.4. BGCs Prediction and Generation of Similarity Networks
The draft genome sequence of “P. miuraensis” SMH-27-4 was mined using the antibiotics and secondary metabolite analysis shell (antiSMASH) (version 6.1.1) [37] to identify the secondary metabolite protoclusters using the “strict” setting. A machine learning-based ribosomally synthesized and post-translationally modified peptide (RiPPs)-mining tool, RiPPMiner [38] was also used to retrieve the RiPP protoclusters. The protoclusters were regarded as BGCs under the following criteria: (1) in the case that the overlapping area of two close protoclusters contains core biosynthetic genes, those with different cluster types are united to one “hybrid” BGC, whereas those with same cluster types are united to one BGC; (2) the following protoclusters predicted by antiSMASH were not considered as BGCs: “RiPP-like”, non-specific RiPP-containing post-translational modification proteins such as DUF 692 family, a function-unknown protein family, and “other” protoclusters that cannot be classified into the known categories. All the predicted BGCs were then analyzed using the biosynthetic gene similarity clustering and prospecting engine (BiG-SCAPE) software package (version 1.1.2) [39], with the MiBIG database (version 2.1) [40] as a reference. BiG-SCAPE was conducted on auto mode with a distance cut-off score of 0.75 and the parameters of “--clans-off”, “--no_classify”, and “--mix”. The “P. miuraensis” SMH-27-4 BGCs-related records were extracted, and the generated networks were visualized with Cytoscape (version 3.8.2) [41].
2.5. Identification of Orthologous Proteins and Functional Categorization
The genome sequences of four strains of the family Nannocystaceae (Nannocystis exedens DSM 71, Pseudenhygromyxa sp. WMMC2535 (GCA_011083025.2), Plesiocystis pacifica SIR-1, and Enhygromyxa salina DSM 15201 (GCA_000737335.3)) were retrieved from the NCBI genome and RefSeq database. Their genomes, including that of “P. miuraensis” SMH-27-4, were re-annotated by the stand-alone PGAP (version 2021-07-01. build5508) with the same parameters. The orthologous proteins were identified by Proteinortho [42]. The protein functional annotation was conducted using the domain-based annotation tool reCOGnizer (version 1.7.2) [43]. The results derived from the clusters of orthologous groups of proteins (COGs) database were used for functional categorization, which consists of 26 categories. Some proteins were classified into more than one functional category. In this case, each protein was assigned as an equal portion of weight for each functional category.
2.6. Availability of Nucleotide Sequence Data
The whole genome shotgun project of “P. miuraensis” SMH-27-4 has been deposited at DDBJ/ENA/GenBank under the accession number JAOVZF000000000. The version described in this paper is version JAOVZF010000000. The raw sequencing data were submitted to the Sequence Read Archive database under the accession number SRR21887204.
3. Results
3.1. Draft Genome Sequencing, Assembly, and Annotation
A total of 2313 Mbp was obtained from Illumina HiSeq paired-end sequencing. The results are summarized in Table 1. The assembled “P. miuraensis” SMH-27-4 draft genome size is 11,849,290 bp, equal to 100.1% of the estimated genome size based on Kmer analysis. The overall GC content is 69.7%. The draft genome consists of 164 contigs, with the N50 and L50 values of 398,768 bp and 11, respectively. The completeness of the draft genome assembly was evaluated by calculating coverage for a set of single-copy orthologous genes in deltaproteobacteria using BUSCO. The results showed that the genome coverage rate was 93.0 %. PGAP annotation predicted 9280 genes in the genome, including 31 pseudogenes, 84 RNAs, and 9156 protein-coding genes that account for 90.7% coding density. The 9156 protein sequences were aligned to the BUSCO database to evaluate the annotation quality, and the coverage rate of 92.6% suggested a high degree of completeness of the gene prediction. A total of 38.3% (3508) of the protein-coding genes were annotated as hypothetical proteins.
3.2. Phylogenetic Analysis
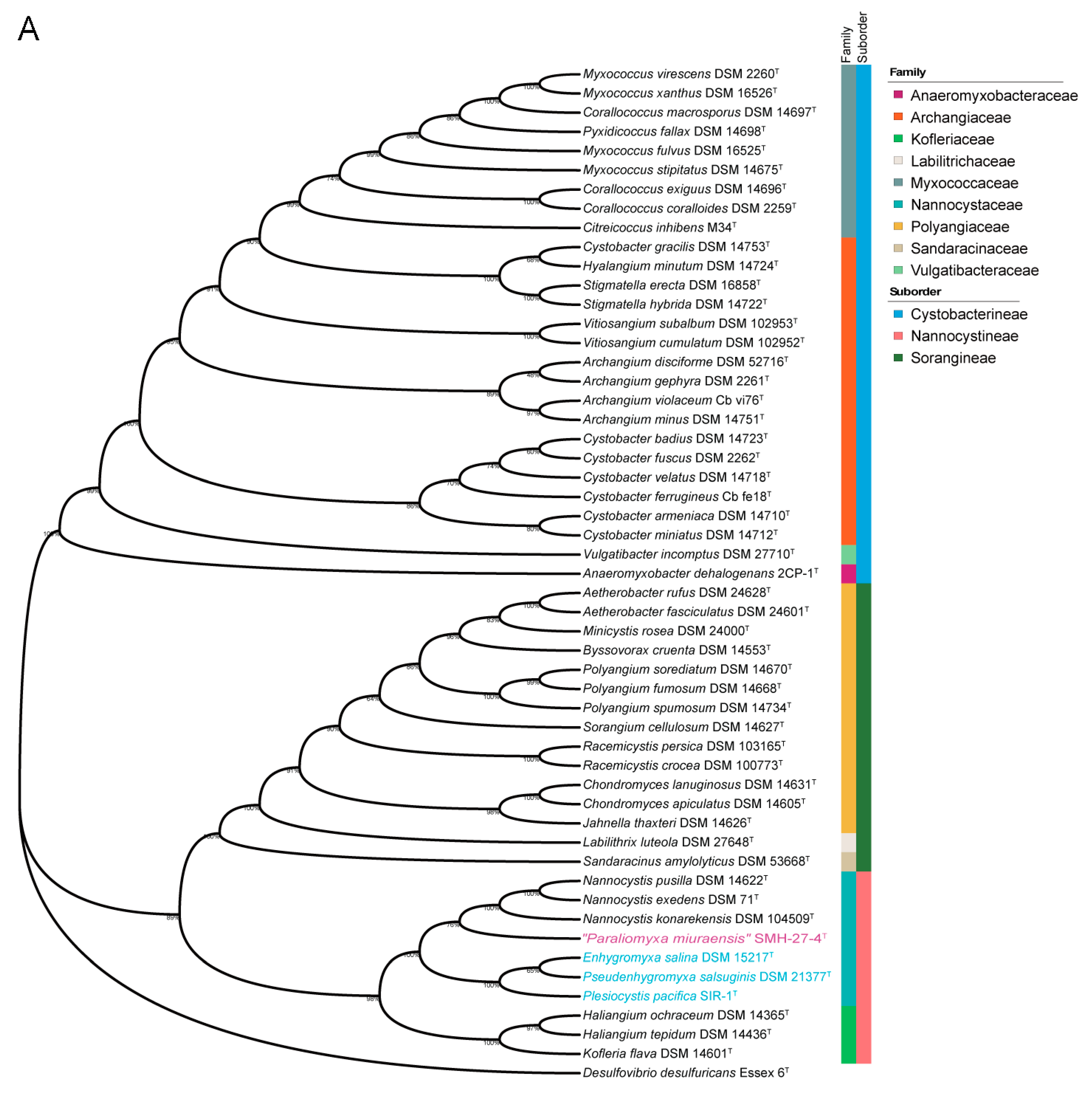
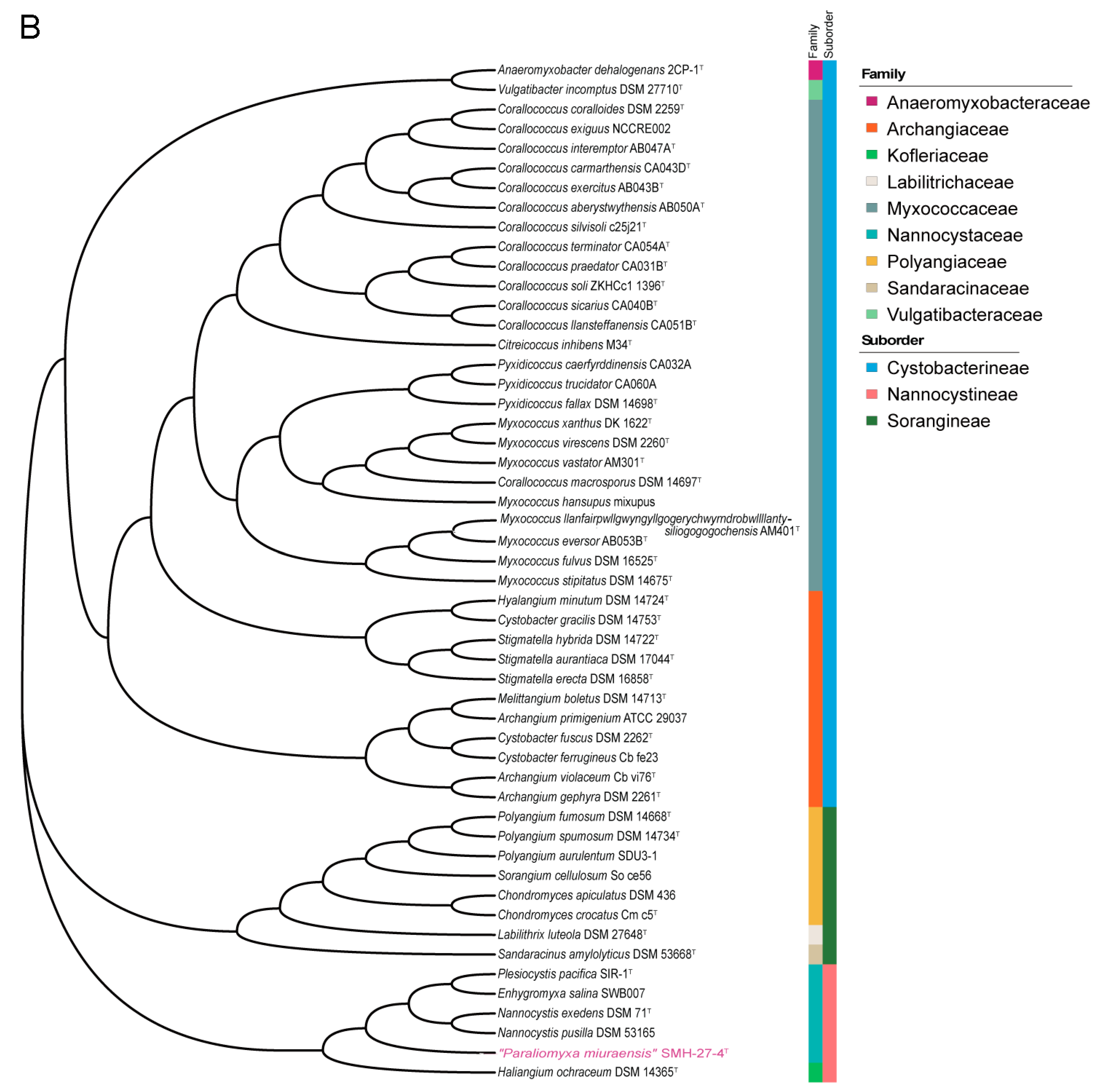
Both the 16S rRNA gene sequence-based and genome sequence-based phylogenetic analyses of the order Myxococcales were performed. The complete 16S rRNA gene sequence of “P. miuraensis” SMH-27-4 consisted of 1544 bp (locus_tag = OEB96_36580), which is identical to the reported partial 16S rRNA gene sequence (1504 bp) [13]. In the 16S rRNA gene sequence-based phylogenetic tree (Figure 2A), the strains in the family Nannocystaceae were divided into two subclades with a support value of 100%. Although “P. miuraensis” SMH-27-4 shared a subclade with the terrestrial genus Nannocystis, it branched out of the strains of the genus Nannocystis with a support value of 76%. The strains of (slightly) halophilic genera (E. salina DSM 15217, P. salsuginis DSM 21377, and P. pacifica DSM 14875) formed the other subclade.
To perform genome-based taxonomic classification, the average nucleotide identity (ANI) was compared between “P. miuraensis” SMH-27-4 and 51 other sequenced myxobacterial strains. The resulting genome-based phylogenetic tree (ANI tree, Figure 2B) indicated that “P. miuraensis” SMH-27-4 was grouped into the family Nannocystaceae but did not form any subclade with other strains of this family. This result is similar to the 16S rRNA gene sequence-based tree (Figure 2A), supporting the novelty of the genus “Paraliomyxa”.
3.3. Biosynthetic Gene Clusters (BGCs)
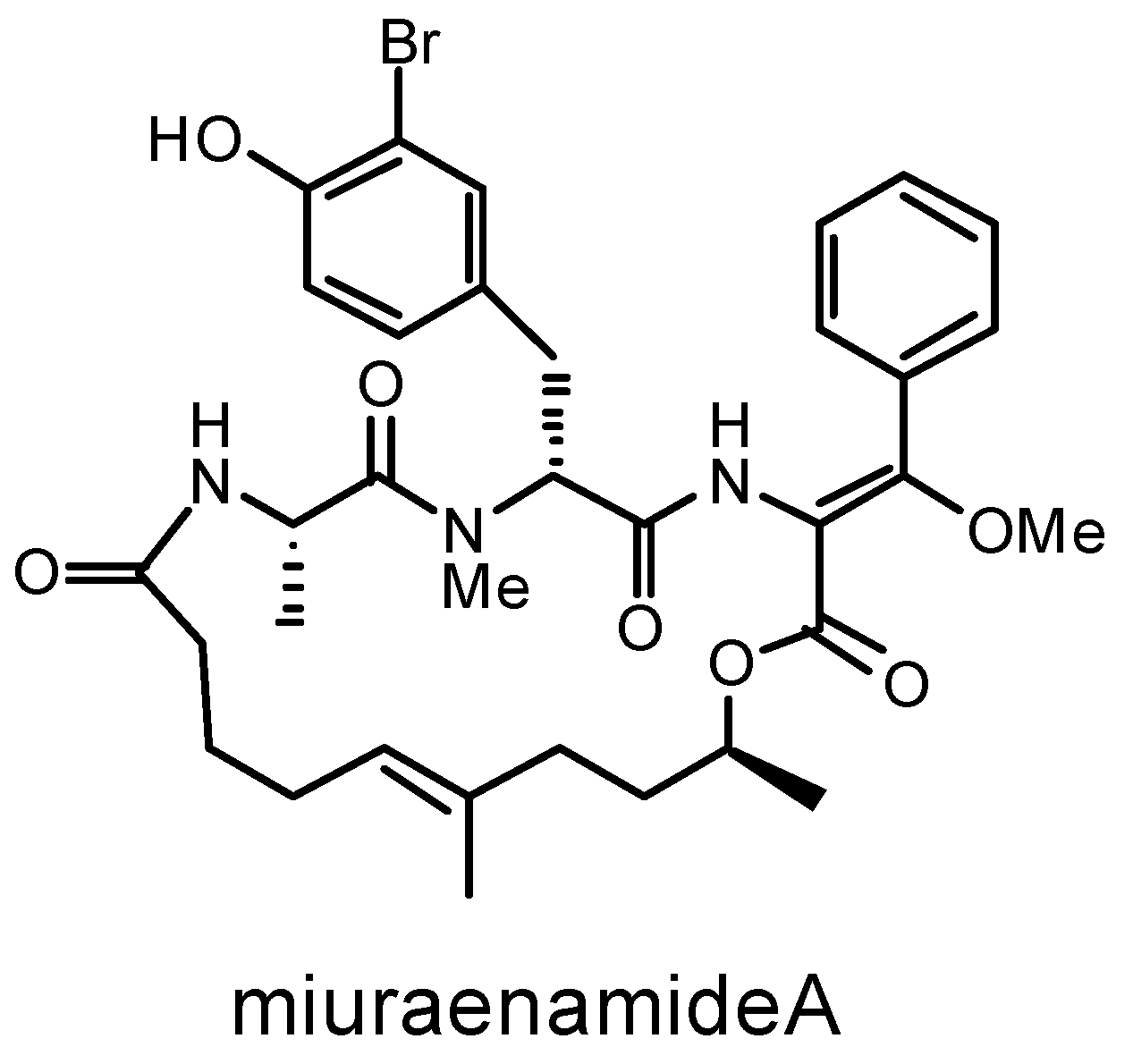
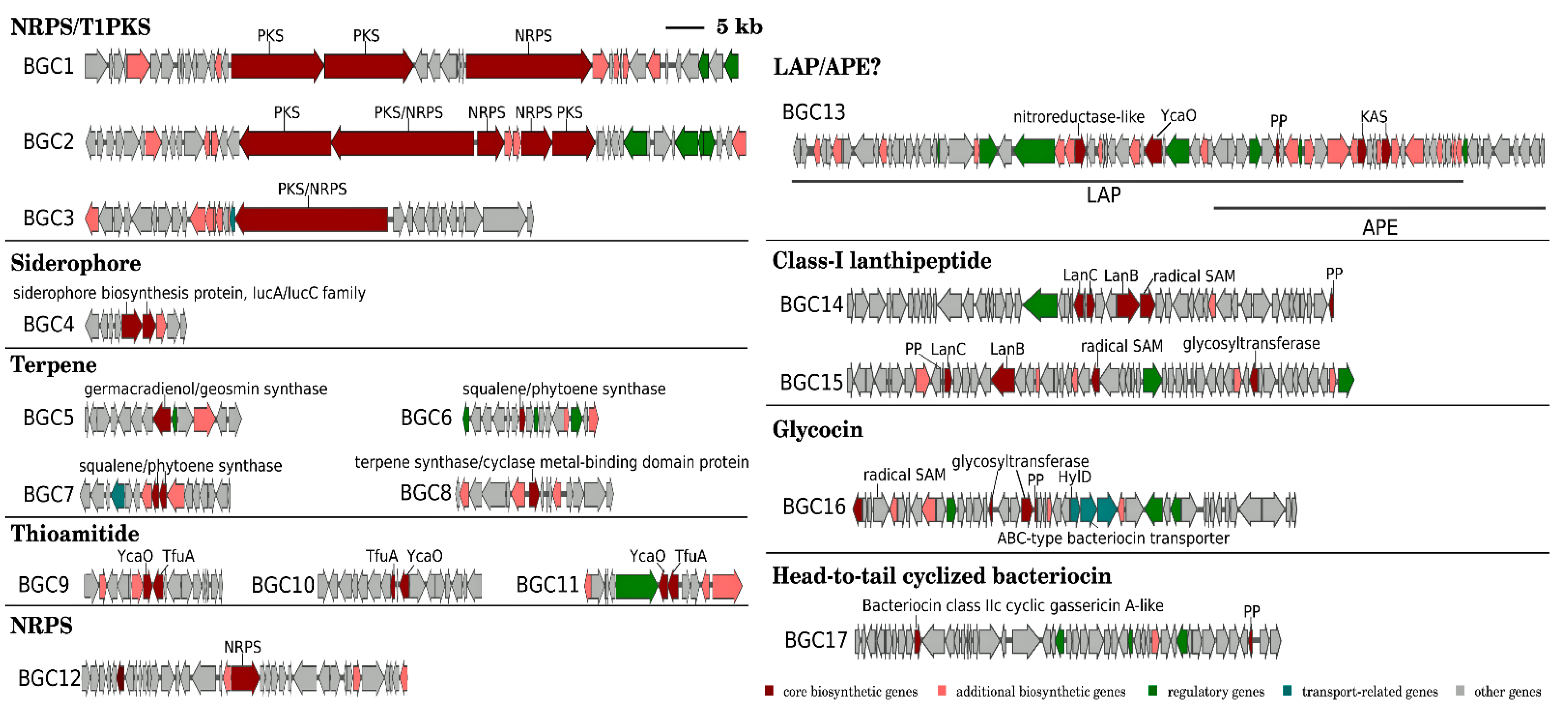
The antiSMASH detected 30 protoclusters, which, due to the presence of some hybrid types, were partially compiled to obtain 24 candidate BGC regions for secondary metabolite biosynthesis (Table S3). The RiPPMiner retrieved five ribosomally synthesized and post-translationally modified peptide (RiPP) protoclusters (Table S4). After the removal of protoclusters of unspecific BGC type and combination of close protoclusters based on the rules described in Section 2.4, 17 BGCs in total were annotated from the genome of “P. miuraensis” SMH-27-4 (Figure 3 and Figure S1). The BGCs include three hybrids of non-ribosomal peptide synthetases/type I polyketide synthase (NRPS/T1PKS), one siderophore, four terpenes, three thioamitides, one NRPS, one linear azol(in)e-containing peptide/aryl polyene hybrid (LAP/APE, probably hybrid), two class-I lanthipeptides, one glycocin and one head-to-tail cyclized bacteriocin. BGC1 (NRPS/T1PKS) was regarded as the BGC for miuraenamide A because the predicted substrate selectivity of its eight modules and their assembly order matched the backbone of miuraenamide A, consisting of five polyketide units and a tripeptide composed of alanine, tyrosine, and phenylalanine. The biosynthesis mechanism of miuraenamide A will be validated in future research.
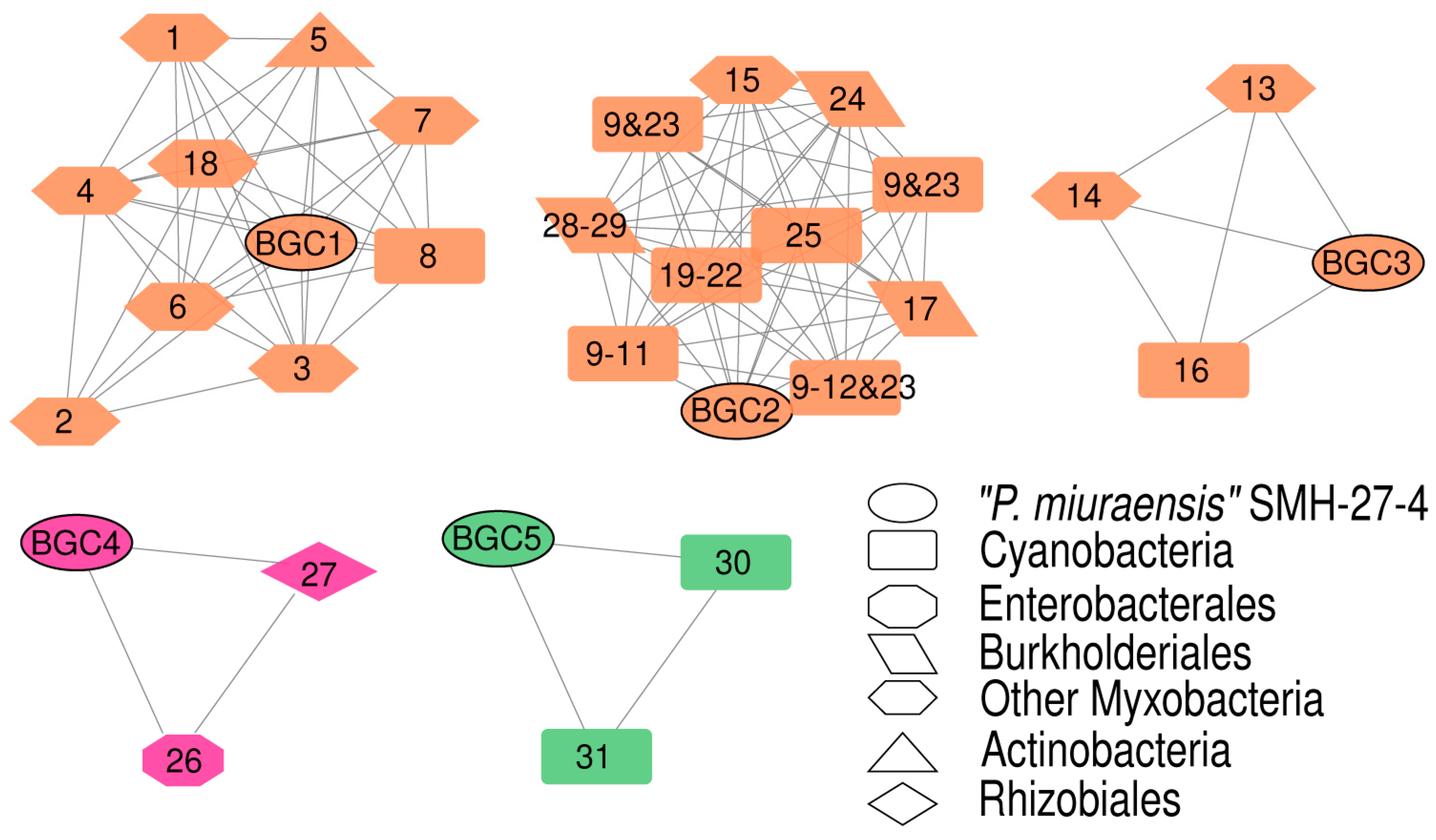
The BGC sequence similarity network obtained by Big-SCAPE suggested the great potential of this strain to produce novel secondary metabolites. Each of the five BGCs (BGC1–BGC5) formed a cluster with the known BGCs from the minimum information about a biosynthetic gene cluster (MIBiG) database (Figure 4 and Figure S2), while the other 12 BGCs showed no similarity with the BGCs for known products. The detailed gene organizations of the BGCs are shown in Figures S3–S7. BGC1 was clustered with the BGCs encoding the biosynthesis of nine myxobacterial depsipeptides: chondramide A (1), epothilone (2), nannocystin A (3), myxothiazol (4), microsclerodermin (6), thaxteramide C (7), antalid (18), and two cyclic depsipeptides from actinobacteria and cyanobacteria, microtermolide A (5) and nodularin (8). BGC2 was clustered with the BGCs encoding the following metabolites’ biosynthesis: two groups of cyanobacterial cyclic lipopeptides minutissamides (9–12) and puwainaphycins (19–23), a cyanobacterial non-ribosomal peptide nostopeptolide A2 (25) [44], the membrane morphology-disrupting fungicide occidiofungin A (17) [45], the fungal chlamydospore formation-inducer ralsolamycin (24) [46], the delftibactins that are able to detoxify toxic soluble gold (28, 29) [47], and the myxobacterial linear peptide myxoprincomide-c506 (15). BGC3 was clustered with the BGCs encoding the biosynthesis of the myxobacterial cyclic depsipeptides myxochromides (13, 14) and the antialgal cyanobacterial peptide kasumigamide (16) [48]. BGC4 was clustered with the BGCs encoding the biosynthesis of the bacterial siderophores aerobactin (26) and ochrobactin (27). BGC5 was clustered with the BGCs encoding the biosynthesis of geosmin (30) and 2-methylisoborneol (31), both of which are responsible for the earthy–musty odor in water.
3.4. Distribution of Gene Fuctions of the Strains of the Family Nannocystaceae
The family Nannocystaceae that contains “P. miuraensis” SMH-27-4 is known to be ecologically diverse. To explore the distribution of the gene functions of this family, a comparative genomic analysis was performed for the genomes of representative strains from five different genera in the family Nannocystaceae: “P. miuraensis” SMH-27-4, N. exedens DSM 71, Pseudenhygromyxa sp. WMMC2535, P. pacifica DSM 14875, and E. salina DSM 15201. The orthologous protein-coding genes were identified, and the genomic functional annotation was performed by the clusters of orthologous groups (COG) approach. Here, the protein-coding genes were divided into core, accessory, and strain-specific genes based on the distribution of orthologous genes through the examined strains (Table 2). The core genes, common genes in the five strains, accounted for 16–19% of each genome, while the strain-specific genes accounted for 44–59%. The others were classified into the accessory genes that occupied 25–37% of the genomes. The COG approach performs microbial genome-wide functional annotation against the COG database, which consists of COGs with manually curated annotation and classifies the COGs into 26 functional categories. The distribution of COG functional categories can reveal to some extent the metabolic or physiological features of the bacteria. Approximately 43% of the protein-coding genes of each strain were classified in COG superfamilies, while more than half were not, suggesting that the genomic resources of myxobacteria are underexplored. The numbers of genes of each COG functional category are listed in Table S5.
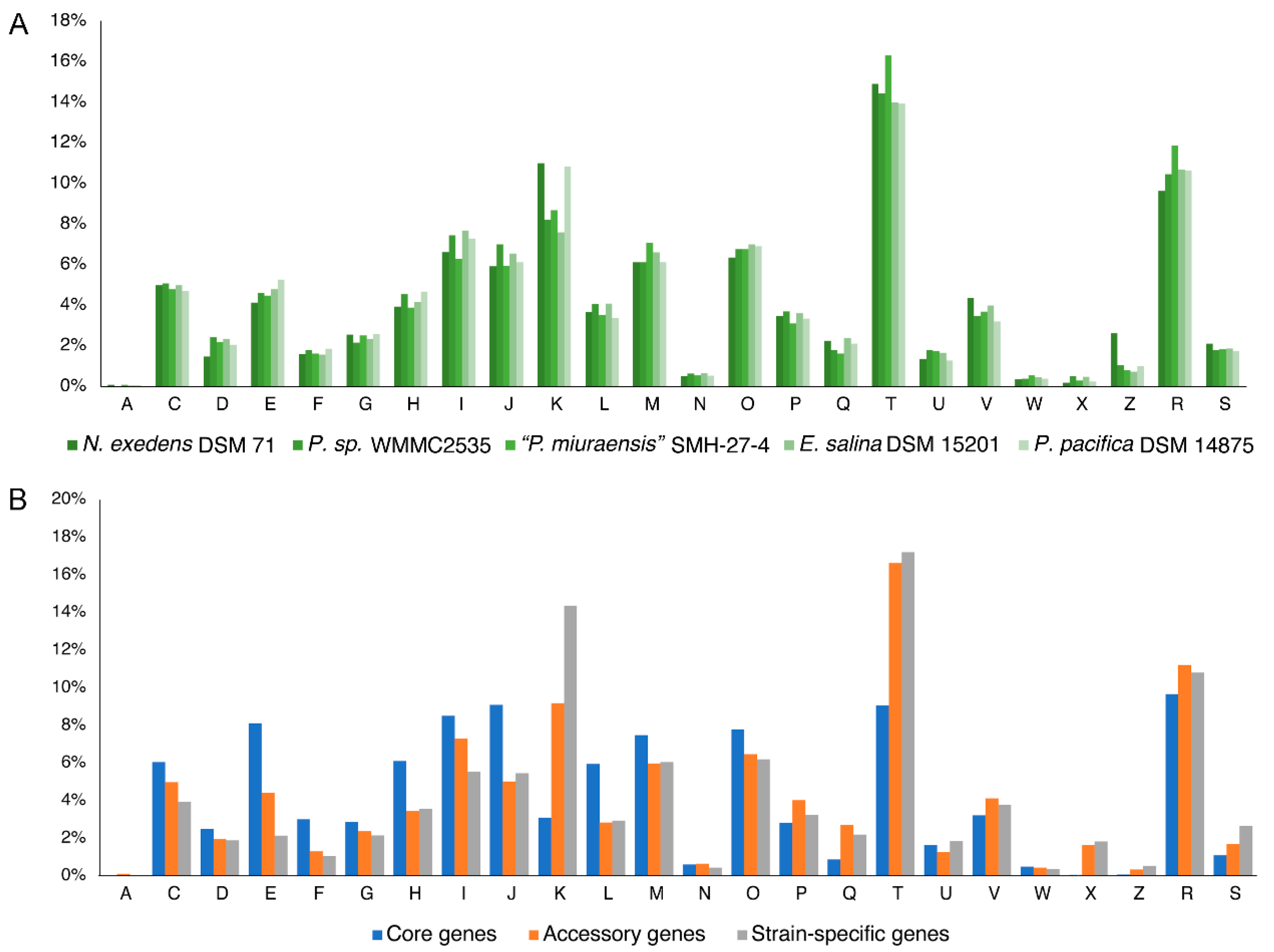
The distribution of functional categories of all COGs was similar between the five strains (Figure 5A), indicating a possibility of conservation in the genomic functions within this family. Except for the poorly characterized categories [R] and [S], the most abundant categories were related to signal transduction mechanisms [T], transcription [K], and lipid transport and metabolism [I]. The abundance of these categories suggests that these myxobacterial strains evolved particular environmental response mechanisms of extra- and intracellular signals that include diverse proteins and metabolites. The average population of functional categories in this family quite varied by the number of core, accessory, and strain-specific genes (Figure 5B). In the accessory genes, signal transduction mechanisms [T] showed the significantly high distribution (16.6%) compared to the other categories (lower than 11.2%). In the strain-specific genes, both signal transduction mechanisms [T] and transcription [K] categories accounted for high distributions (14.4–17.2%). On the other hand, the distribution of the core genes was more homogeneous. This trend was evidenced by the standard deviations of the distribution of 4.3%, 3.9%, and 3.4% for the strain-specific, accessory, and core genes, respectively. The variation of the gene functions and the percentage of the gene number (Table 2) in the strain-specific genes give an account of the diversity of these genera in the family Nannocystaceae.
4. Discussion
The draft genome of “P. miuraensis” SMH-27-4 was sequenced, and de novo assembled into 11.8 Mbp of 164 contigs. Both Kmer and BUSCO analyses suggested a high degree of completeness of the genome assembly. We did not use third-generation long-read sequencing technologies but acknowledge that they facilitate the de novo assembly of complete genomes, as longer reads can be aligned to repetitive sequences with high confidence and increase assembly contiguity. Although the Illumina-based secondary generation short-read sequencing can assemble over 99% of the complete genome, the few missing parts may include essential genes, as recently illustrated in Pseudomonas aeruginosa [49]. The results of the 16S rRNA gene-sequence-based phylogenetic analysis and the genome-based taxonomic classification by ANI values were consistent with each other and indicated that this difficult-to-culture myxobacterium represents a novel genus in the family Nannocystaceae. Aside from the BGC for miuraenamide A, the strain has 16 other BGCs that showed low or no similarity with the BGCs for known products, revealing a great potential of the strain to produce novel secondary metabolites. The similar distribution of the COG functional categories through the strains from five genera within the family Nannocystaceae indicated conserved genomic functions of this family. On the other hand, the average distribution of COG functional categories by the core, accessory, and strain-specific genes suggests that the five genera have diverse signal transduction and gene transcription mechanisms. Regardless of the taxonomic and physiological novelty of this rare slightly halophilic myxobacterium, the potential of great secondary metabolites production makes it worthy of studying.
5. Conclusions
Myxobacteria are common in terrestrial habitats and known for their potential to produce novel natural products, whereas marine-derived (or halophilic) ones are quite rare and only seven species (five genera) have been identified since the isolation of the first marine myxobacteria H. ochraceum and P. pacifica in 1998 [8]. Although these marine myxobacteria are regarded as a good factory of valuable secondary metabolites beyond the terrestrial ones, their cultivation is generally difficult and takes a long period for enough growth. Their genomic information is therefore important to elucidate their great potential to produce novel leads with unique molecular scaffolds and bioactivities. “P. miuraensis” SMH-27-4 produces a series of PKS/NRPS hybrid molecules named miuraenamides [13], but its metabolic profile indicated a scarcity of metabolite diversity; no other distinct metabolites were detected in the extracts. The genomic analysis of this strain was therefore performed in this study and revealed the presence of 17 BGCs for producing metabolites, one of which was estimated to encode the biosynthesis of miuraenamides. The complete genome sequence was not available in this study due to the extremely difficult cultivation and DNA extraction from aggregated mucous cells. Nevertheless, because of the high-quality sequence data, 93% coverage of the complete genome (the rest could be repetition), and no overlooking of other possible BGCs, the present draft genome information could contribute to improving the inadequate expertise in the marine myxobacterial genomic functions, especially for hidden biosynthetic machineries leading to brand-new natural products. Further studies will be needed to reveal the mechanism of the miuraenamide biosynthesis as well as more precise genomic analysis.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/microorganisms11020371/s1, Table S1: Information of 16S rRNA genes used in Figure 2A; Table S2: Information of genome sequences used in Figure 2B; Table S3: Candidate secondary metabolite BGC regions identified with antiSMASH; Table S4: RiPP protoclusters revealed by RiPPMiner; Table S5: COG classification of the protein-coding genes of five strains in the family Nannocystaceae; Figure S1: Locations of BGCs. Figure S2: Chemical structures of the secondary metabolites described in Figure 4; Figure S3: Organizations of BGC1 and its related BGCs of other species; Figure S4: Organizations of BGC2 and its related BGCs of other species; Figure S5: Organizations of BGC3 and its related BGCs of other species; Figure S6: Organizations of BGC4 and its related BGCs of other species; Figure S7: Organizations of BGC5 and its related BGCs of other species; Reference S1: Description of Paraliomyxa gen. nov./Paraliomyxa miuraensis sp. nov. (a part of Ref. [14]).
Author Contributions
Conceptualization, M.O.; methodology, Y.L.; software, Y.L.; validation, M.O.; formal analysis, Y.L.; investigation, Y.L.; data curation, Y.L. and M.O.; writing—original draft preparation, Y.L.; writing—review and editing, M.O.; visualization, Y.L.; supervision, M.O.; project administration, M.O.; funding acquisition, M.O. and Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Japan Society for the Promotion of Science (No. 12480172) and Japan Science and Technology Agency (No. JPMJSP2125).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available in Supplementary Material and via accession numbers described in the Section 2 of this article.
Acknowledgments
We thank Takashi Iizuka and Ryosuke Fudou for supporting bacterial cultivation and Ajinomoto Co., Inc. for gifting the myxobacterial strain. Y.L. thank the Interdisciplinary Frontier Next-Generation Researcher Program of the Tokai Higher Education and Research System for financial support.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Velicer, G.J.; Vos, M. Sociobiology of the myxobacteria. Annu. Rev. Microbiol. 2009, 63, 599–623. [Google Scholar] [CrossRef] [PubMed]
- Kaiser, D.; Robinson, M.; Kroos, L. Myxobacteria, polarity, and multicellular morphogenesis. Cold Spring Harb. Perspect. Biol. 2010, 2, a000380. [Google Scholar] [CrossRef] [PubMed]
- Muñoz-dorado, J.; Marcos-torres, F.J.; García-bravo, E.; Moraleda-muñoz, A.; Pérez, J. Myxobacteria: Moving, killing, feeding, and surviving together. Front. Microbiol. 2016, 7, 781. [Google Scholar] [CrossRef] [PubMed]
- Wenzel, S.C.; Müller, R. Myxobacteria—‘Microbial factories’ for the production of bioactive secondary metabolites. Mol. BioSyst. 2009, 5, 567–574. [Google Scholar] [CrossRef]
- Diez, J.; Martinez, J.P.; Mestres, J.; Sasse, F.; Frank, R.; Meyerhans, A. Myxobacteria: Natural pharmaceutical factories. Microb. Cell Fact. 2012, 11, 2–4. [Google Scholar] [CrossRef]
- Hug, J.J.; Müller, R. Host development for heterologous expression and biosynthetic studies of myxobacterial natural products. In Comprehensive Natural Products III, 3rd ed.; Liu, H., Begley, T.P., Eds.; Elsevier: San Diego, CA, USA, 2020; Volume 6, pp. 149–216. [Google Scholar]
- Thaxter, R. Contributions from the cryptogamic laboratory of Harvard University. XVIII. On the Myxobacteriaceae, a new order of Schizomycetes. Bot. Gaz. 1892, 12, 389–406. [Google Scholar] [CrossRef]
- Iizuka, T.; Jojima, Y.; Fudou, R.; Yamanaka, S. Isolation of myxobacteria from the marine environment. FEMS Microbiol. Lett. 1998, 169, 317–322. [Google Scholar] [CrossRef]
- Dávila-Céspedes, A.; Hufendiek, P.; Crüsemann, M.; Schäberle, T.F.; König, G.M. Marine-derived myxobacteria of the suborder Nannocystineae: An underexplored source of structurally intriguing and biologically active metabolites. Beilstein J. Org. Chem. 2016, 12, 969–984. [Google Scholar] [CrossRef]
- Albataineh, H.; Stevens, D.C. Marine myxobacteria: A few good halophiles. Mar. Drugs 2018, 16, 209. [Google Scholar] [CrossRef]
- Gemperlein, K.; Zaburannyi, N.; Garcia, R.; La Clair, J.J.; Müller, R. Metabolic and biosynthetic diversity in marine myxobacteria. Mar. Drugs 2018, 16, 314. [Google Scholar] [CrossRef] [Green Version]
- Moghaddam, J.A.; Crüsemann, M.; Alanjary, M.; Harms, H.; Dávila-Céspedes, A.; Blom, J.; Poehlein, A.; Ziemert, N.; König, G.M.; Schäberle, T.F. Analysis of the genome and metabolome of marine myxobacteria reveals high potential for biosynthesis of novel specialized metabolites. Sci. Rep. 2018, 8, 16600. [Google Scholar] [CrossRef]
- Iizuka, T.; Fudou, R.; Jojima, Y.; Ogawa, S.; Yamanaka, S.; Inukai, Y.; Ojika, M. Miuraenamides A and B, novel antimicrobial cyclic depsipeptides from a new slightly halophilic myxobacterium: Taxonomy, production, and biological properties. J. Antibiot. 2006, 59, 385–391. [Google Scholar] [CrossRef]
- Iizuka, T. Isolation and Characterization of Novel Myxobacteria and Their Significance as Biomedical Resources. Ph.D. Thesis, Toyohashi University of Technology, Toyohashi, Japan, January 2016. [Google Scholar]
- Garcia, R.; Müller, R. The family Nannocystaceae. In The Prokaryotes—Deltaproteobacteria and Epsilonproteobacteria, 4th ed.; Rosenberg, E., Delong, E.F., Loy, S., Stackebrandt, E., Thompson, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; Volume 10, pp. 213–229. [Google Scholar]
- Iizuka, T.; Jojima, Y.; Hayakawa, A.; Fujii, T.; Yamanaka, S.; Fudou, R. Pseudenhygromyxa salsuginis gen. nov., sp. nov., a myxobacterium isolated from an estuarine marsh. Int. J. Syst. Evol. Microbiol. 2013, 63, 1360–1369. [Google Scholar] [CrossRef]
- Reichenbach, H. Nannocystis exedens gen. nov., spec. nov., a new myxobacterium of the family Sorangiaceae. Arch. Mikrobiol. 1970, 70, 119–138. [Google Scholar] [CrossRef]
- Sumiya, E.; Shimogawa, H.; Sasaki, H.; Tsutsumi, M.; Yoshita, K.; Ojika, M.; Suenaga, K.; Uesugi, M. Cell-morphology profiling of a natural product library identifies bisebromoamide and miuraenamide A as actin filament stabilizers. ACS Chem. Biol. 2011, 6, 425–431. [Google Scholar] [CrossRef]
- Karmann, L.; Schultz, K.; Herrmann, J.; Müller, R.; Kazmaier, U. Total syntheses and biological evaluation of miuraenamides. Angew. Chem. Int. Ed. 2015, 54, 4502–4507. [Google Scholar] [CrossRef]
- Ojima, D.; Yasui, A.; Tohyama, K.; Tokuzumi, K.; Toriihara, E.; Ito, K.; Iwasaki, A.; Tomura, T.; Ojika, M.; Suenaga, K. Total synthesis of miuraenamides A and D. J. Org. Chem. 2016, 81, 9886–9894. [Google Scholar] [CrossRef]
- Moser, C.; Rüdiger, D.; Förster, F.; von Blume, J.; Yu, P.; Kazmaier, U.; Vollmar, A.M.; Zahler, S. Persistent inhibition of pore-based cell migration by sub-toxic doses of miuraenamide, an actin filament stabilizer. Sci. Rep. 2017, 7, 16407. [Google Scholar] [CrossRef]
- Kappler, S.; Karmann, L.; Prudel, C.; Herrmann, J.; Caddeu, G.; Müller, R.; Vollmar, A.M.; Zahler, S.; Kazmaier, U. Synthesis and biological evaluation of modified miuraenamides. Eur. J. Org. Chem. 2018, 48, 6952–6965. [Google Scholar] [CrossRef]
- Gegenfurtner, F.A.; Zisis, T.; Al Danaf, N.; Schrimpf, W.; Kliesmete, Z.; Ziegenhain, C.; Enard, W.; Kazmaier, U.; Lamb, D.C.; Vollmar, A.M.; et al. Transcriptional effects of actin-binding compounds: The cytoplasm sets the tone. Cell. Mol. Life Sci. 2018, 75, 4539–4555. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Crevenna, A.H.; Ugur, I.; Marion, A.; Antes, I.; Kazmaier, U.; Hoyer, M.; Lamb, D.C.; Gegenfurtner, F.; Kliesmete, Z.; et al. Actin stabilizing compounds show specific biological effects due to their binding mode. Sci. Rep. 2019, 9, 9731. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Meixner, M.; Yu, L.; Zhuo, L.; Karmann, L.; Kazmaier, U.; Vollmar, A.M.; Antes, I.; Zahler, S. Turning the actin nucleating compound miuraenamide into nucleation inhibitors. ACS Omega 2021, 6, 22165–22172. [Google Scholar] [CrossRef] [PubMed]
- Baltes, C.; Thalla, D.G.; Kazmaier, U.; Lautenschläger, F. Actin stabilization in cell migration. Front. Cell Dev. Biol. 2022, 10, 931880. [Google Scholar] [CrossRef]
- Martin, M. Cutadapt removes adapter sequences from high-throughput sequencing reads. EMBnet J. 2011, 17, 10–12. [Google Scholar] [CrossRef]
- Bolger, A.M.; Lohse, M.; Usadel, B. Trimmomatic: A flexible trimmer for illumina sequence data. Bioinformatics 2014, 30, 2114–2120. [Google Scholar] [CrossRef]
- Zerbino, D.R.; Birney, E. Velvet: Algorithms for de novo short read assembly using de bruijn graphs. Genome Res. 2008, 18, 821–829. [Google Scholar] [CrossRef]
- Kajitani, R.; Toshimoto, K.; Noguchi, H.; Toyoda, A.; Ogura, Y.; Okuno, M.; Yabana, M.; Harada, M.; Nagayasu, E.; Maruyama, H.; et al. Efficient de novo assembly of highly heterozygous genomes from whole-genome shotgun short reads. Genome Res. 2014, 24, 1384–1395. [Google Scholar] [CrossRef]
- Tatusova, T.; Dicuccio, M.; Badretdin, A.; Chetvernin, V.; Nawrocki, E.P.; Zaslavsky, L.; Lomsadze, A.; Pruitt, K.D.; Borodovsky, M.; Ostell, J. NCBI prokaryotic genome annotation pipeline. Nucleic Acids Res. 2016, 44, 6614–6624. [Google Scholar] [CrossRef]
- Manni, M.; Berkeley, M.R.; Seppey, M.; Simão, F.A.; Zdobnov, E.M. BUSCO update: Novel and streamlined workflows along with broader and deeper phylogenetic coverage for scoring of eukaryotic, prokaryotic, and viral genomes. Mol. Biol. Evol. 2021, 38, 4647–4654. [Google Scholar] [CrossRef]
- Yamada, K.D.; Tomii, K.; Katoh, K. Application of the MAFFT sequence alignment program to large data—Reexamination of the usefulness of chained guide trees. Bioinformatics 2016, 32, 3246–3251. [Google Scholar] [CrossRef] [Green Version]
- Minh, B.Q.; Schmidt, H.A.; Chernomor, O.; Schrempf, D.; Woodhams, M.D.; Von Haeseler, A.; Lanfear, R.; Teeling, E. IQ-TREE 2: New models and efficient methods for phylogenetic inference in the genomic era. Mol. Biol. Evol. 2020, 37, 1530–1534. [Google Scholar] [CrossRef] [PubMed]
- Letunic, I.; Bork, P. Interactive tree of life (ITOL) v5: An online tool for phylogenetic tree display and annotation. Nucleic Acids Res. 2021, 49, W293–W296. [Google Scholar] [CrossRef]
- Rodriguez-R, L.M.; Konstantinidis, K.T. The enveomics collection: A toolbox for specialized analyses of microbial genomes and metagenomes. PeerJ Prepr. 2016, 4, e1900v1. [Google Scholar]
- Blin, K.; Shaw, S.; Kloosterman, A.M.; Charlop-Powers, Z.; van Wezel, G.P.; Medema, M.H.; Weber, T. AntiSMASH 6.0: Improving cluster detection and comparison capabilities. Nucleic Acids Res. 2021, 49, W29–W35. [Google Scholar] [CrossRef]
- Agrawal, P.; Khater, S.; Gupta, M.; Sain, N.; Mohanty, D. RiPPMiner: A bioinformatics resource for deciphering chemical structures of RiPPs based on prediction of cleavage and cross-links. Nucleic Acids Res. 2017, 45, W80–W88. [Google Scholar] [CrossRef]
- Navarro-Muñoz, J.C.; Selem-Mojica, N.; Mullowney, M.W.; Kautsar, S.A.; Tryon, J.H.; Parkinson, E.I.; De Los Santos, E.L.C.; Yeong, M.; Cruz-Morales, P.; Abubucker, S.; et al. A computational framework to explore large-scale biosynthetic diversity. Nat. Chem. Biol. 2020, 16, 60–68. [Google Scholar] [CrossRef]
- Kautsar, S.A.; Blin, K.; Shaw, S.; Navarro-Muñoz, J.C.; Terlouw, B.R.; van der Hooft, J.J.J.; van Santen, J.A.; Tracanna, V.; Suarez Duran, H.G.; Pascal Andreu, V.; et al. MIBiG 2.0: A repository for biosynthetic gene clusters of known function. Nucleic Acids Res. 2020, 48, D454–D458. [Google Scholar] [CrossRef]
- Shannon, P.; Markiel, A.; Ozier, O.; Baliga, N.S.; Wang, J.T.; Ramage, D.; Amin, N.; Schwikowski, B.; Ideker, T. Cytoscape: A software environment for integrated models of biomolecular interaction networks. Genome Res. 2003, 13, 2498–2504. [Google Scholar] [CrossRef]
- Lechner, M.; Findeiß, S.; Steiner, L.; Marz, M.; Stadler, P.F.; Prohaska, S.J. Proteinortho: Detection of (co-) orthologs in large-scale analysis. BMC Bioinform. 2011, 12, 124. [Google Scholar] [CrossRef] [PubMed]
- Sequeira, J.C.; Rocha, M.; Alves, M.M.; Salvador, A.F. UPIMAPI, ReCOGnizer and KEGGCharter: Bioinformatics tools for functional annotation and visualization of (meta)-omics datasets. Comput. Struct. Biotechnol. J. 2022, 20, 1798–1810. [Google Scholar] [CrossRef]
- Liaimera, A.; Helfrichb, E.J.N.; Hinrichsc, K.; Guljamowc, A.; Ishidab, K.; Hertweck, C.; Dittmann, E. Nostopeptolide plays a governing role during cellular differentiation of the symbiotic cyanobacterium Nostoc punctiforme. Proc. Natl. Acad. Sci. USA 2015, 112, 1862–1867. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, S.E.; Novak, J.; Austin, F.W.; Gu, G.; Ellis, D.; Kirk, M.; Wilson-Stanford, S.; Tonelli, M.; Smith, L. Occidiofungin, a unique antifungal glycopeptide produced by a strain of Burkholderia contaminans. Biochemistry 2009, 48, 8312–8321. [Google Scholar] [CrossRef] [PubMed]
- Baldeweg, F.; Kage, H.; Schieferdecker, S.; Allen, C.; Hoffmeister, D.; Nett, M. Structure of ralsolamycin, the interkingdom morphogen from the crop plant pathogen Ralstonia solanacearum. Org. Lett. 2017, 19, 4868–4871. [Google Scholar] [CrossRef] [PubMed]
- Johnston, C.W.; Wyatt, M.A.; Li, X.; Ibrahim, A.; Shuster, J.; Southam, G.; Magarvey, N.A. Gold biomineralization by a metallophore from a gold-associated microbe. Nat. Chem. Biol. 2013, 9, 241–243. [Google Scholar] [CrossRef]
- Ishida, K.; Murakami, M. Kasumigamide, an antialgal peptide from the cyanobacterium Microcystis aeruginosa. J. Org. Chem. 2000, 65, 5898–5900. [Google Scholar] [CrossRef]
- Varadarajan, A.R.; Allan, R.N.; Valentin, J.D.P.; Castañeda Ocampo, O.E.; Somerville, V.; Pietsch, F.; Buhmann, M.T.; West, J.; Skipp, P.J.; van der Mei, H.C.; et al. An integrated model system to gain mechanistic insights into biofilm-associated antimicrobial resistance in Pseudomonas aeruginosa MPAO1. NPJ Biofilms Microbiomes 2020, 6, 46. [Google Scholar] [CrossRef]
Figure 1.
Chemical structure of miuraenamide A.

Figure 2.
Phylogenetic trees of myxobacteria in comparison with “P. miuraensis” SMH-27-4. (A) 16S rRNA gene sequence-based tree. The numbers at the nodes indicate branch support values. The (slightly) halophilic strains of the family Nannocystaceae are in light blue. (B) Genome sequence-based tree.
Figure 2.
Phylogenetic trees of myxobacteria in comparison with “P. miuraensis” SMH-27-4. (A) 16S rRNA gene sequence-based tree. The numbers at the nodes indicate branch support values. The (slightly) halophilic strains of the family Nannocystaceae are in light blue. (B) Genome sequence-based tree.


Figure 3.
Organizations of putative BGCs in the genome of “P. miuraensis” SMH-27-4.

Figure 4.
BGC sequence similarity networks of “P. miuraensis” SMH-27-4 and related sequences from the MIBiG database. Nodes are color-coded according to BGC types and shape-coded according to biosynthesis origins (legend). Numbered nodes represent the BGCs from the MIBiG database. The chemical structures of the products encoded by them were listed with the same numbers in Figure S2.
Figure 4.
BGC sequence similarity networks of “P. miuraensis” SMH-27-4 and related sequences from the MIBiG database. Nodes are color-coded according to BGC types and shape-coded according to biosynthesis origins (legend). Numbered nodes represent the BGCs from the MIBiG database. The chemical structures of the products encoded by them were listed with the same numbers in Figure S2.

Figure 5.
Distribution of COG functional categories in five strains of the family Nannocystaceae. (A) Distribution of functional categories in COGs by strains; (B) Average distribution of functional categories of all strains by the core, accessory, and strain-specific genes. Abbreviations: A: RNA processing and modification; C: Energy production and conversion; D: Cell cycle control, cell division, chromosome partitioning; E: Amino acid transport and metabolism; F: Nucleotide transport and metabolism; G: Carbohydrate transport and metabolism; H: Coenzyme transport and metabolism; I: Lipid transport and metabolism; J: Translation, ribosomal structure and bio-genesis; K: Transcription; L: Replication, recombination and repair; M: Cell wall/membrane/envelop biogenesis; N: Cell motility; O: Posttranslational modification, protein turnover, chaperones; P: Inorganic ion transport and metabolism; Q: Secondary metabolites biosynthesis, transport and catabolism; T: Signal transduction mechanisms; U: Intracellular trafficking, secretion, and vesicular transport; V: Defense mechanisms; W: Extracellular structures; X: Mobilome: prophages, transposons; Z: Cytoskeleton; R: General function prediction only; S: Function unknown.
Figure 5.
Distribution of COG functional categories in five strains of the family Nannocystaceae. (A) Distribution of functional categories in COGs by strains; (B) Average distribution of functional categories of all strains by the core, accessory, and strain-specific genes. Abbreviations: A: RNA processing and modification; C: Energy production and conversion; D: Cell cycle control, cell division, chromosome partitioning; E: Amino acid transport and metabolism; F: Nucleotide transport and metabolism; G: Carbohydrate transport and metabolism; H: Coenzyme transport and metabolism; I: Lipid transport and metabolism; J: Translation, ribosomal structure and bio-genesis; K: Transcription; L: Replication, recombination and repair; M: Cell wall/membrane/envelop biogenesis; N: Cell motility; O: Posttranslational modification, protein turnover, chaperones; P: Inorganic ion transport and metabolism; Q: Secondary metabolites biosynthesis, transport and catabolism; T: Signal transduction mechanisms; U: Intracellular trafficking, secretion, and vesicular transport; V: Defense mechanisms; W: Extracellular structures; X: Mobilome: prophages, transposons; Z: Cytoskeleton; R: General function prediction only; S: Function unknown.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Assembly and annotation statistics for the draft genome sequence of “P. miuraensis” SMH-27-4.
Table 1.
Assembly and annotation statistics for the draft genome sequence of “P. miuraensis” SMH-27-4.
| Number of contigs | 164 |
| GC Content (%) | 69.7 |
| Estimated genome size based on Kmer analysis | 11,832,550 bp |
| Assembled genome size | 11,849,290 bp (100.1%) |
| N50 (bp) | 398,768 |
| L50 | 11 |
| Genes (total) | 9280 |
| Pseudogenes (total) | 40 |
| Genes (RNA) | 84 |
| tRNAs | 77 |
| rRNAs | 1, 1, 1 (5S, 16S, 23S) |
| ncRNAs | 4 |
| Genes (coding) | 9156 |
| Coding density | 90.7% |
| Hypothetic proteins | 3508 (38.3%) |
| Percentage (%) of complete BUSCOs in the genome assembly | 93.0% |
| Percentage (%) of complete BUSCOs among the annotated genes | 92.6% |
Table 2.
Comparative genomic analysis of five strains of the family Nannocystaceae.
| Strains | Protein-Coding Genes | Orthologous Genes | COG Annotated Genes | ||
|---|---|---|---|---|---|
| Core Genes | Accessory Genes | Strain-Specific Genes | |||
| Pm | 9145 (100%) | 1460 (16%) | 2500 (27%) | 5185 (57%) | 3891 (43%) |
| Ne | 9295 (100%) | 1469 (16%) | 2347 (25%) | 5479 (59%) | 4020 (43%) |
| Ps | 7726 (100%) | 1475 (19%) | 2847 (37%) | 3404 (44%) | 3389 (44%) |
| Pp | 8182 (100%) | 1448 (18%) | 2859 (35%) | 3875 (47%) | 3516 (43%) |
| Es | 8079 (100%) | 1448 (18%) | 2788 (35%) | 3843 (48%) | 3390 (42%) |
The strains included in this analysis are the following: Pm “P. miuraensis” SMH-27-4, Ne N. exedens DSM 71, Ps Pseudenhygromyxa sp. WMMC2535, Pp P. pacifica SIR-1, Es E. salina DSM 1520.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liu, Y.; Ojika, M. Genomic Analysis of the Rare Slightly Halophilic Myxobacterium “Paraliomyxa miuraensis” SMH-27-4, the Producer of the Antibiotic Miuraenamide A. Microorganisms 2023, 11, 371. https://doi.org/10.3390/microorganisms11020371
AMA Style
Liu Y, Ojika M. Genomic Analysis of the Rare Slightly Halophilic Myxobacterium “Paraliomyxa miuraensis” SMH-27-4, the Producer of the Antibiotic Miuraenamide A. Microorganisms. 2023; 11(2):371. https://doi.org/10.3390/microorganisms11020371
Chicago/Turabian StyleLiu, Ying, and Makoto Ojika. 2023. "Genomic Analysis of the Rare Slightly Halophilic Myxobacterium “Paraliomyxa miuraensis” SMH-27-4, the Producer of the Antibiotic Miuraenamide A" Microorganisms 11, no. 2: 371. https://doi.org/10.3390/microorganisms11020371
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.