
Machine Learning in Manufacturing towards Industry 4.0: From ‘For Now’ to ‘Four-Know’
 , , , , , , , ,
, , , , , , , ,  and
and
Abstract
:1. Introduction
- RQ1: How does ML benefit manufacturing, and what are the typical ML application cases?
- RQ2: How are ML-based solutions developed for problems in manufacturing engineering?
- RQ3: What are the challenges and opportunities in applying ML in manufacturing contexts?
2. Overview of Machine Learning in Manufacturing
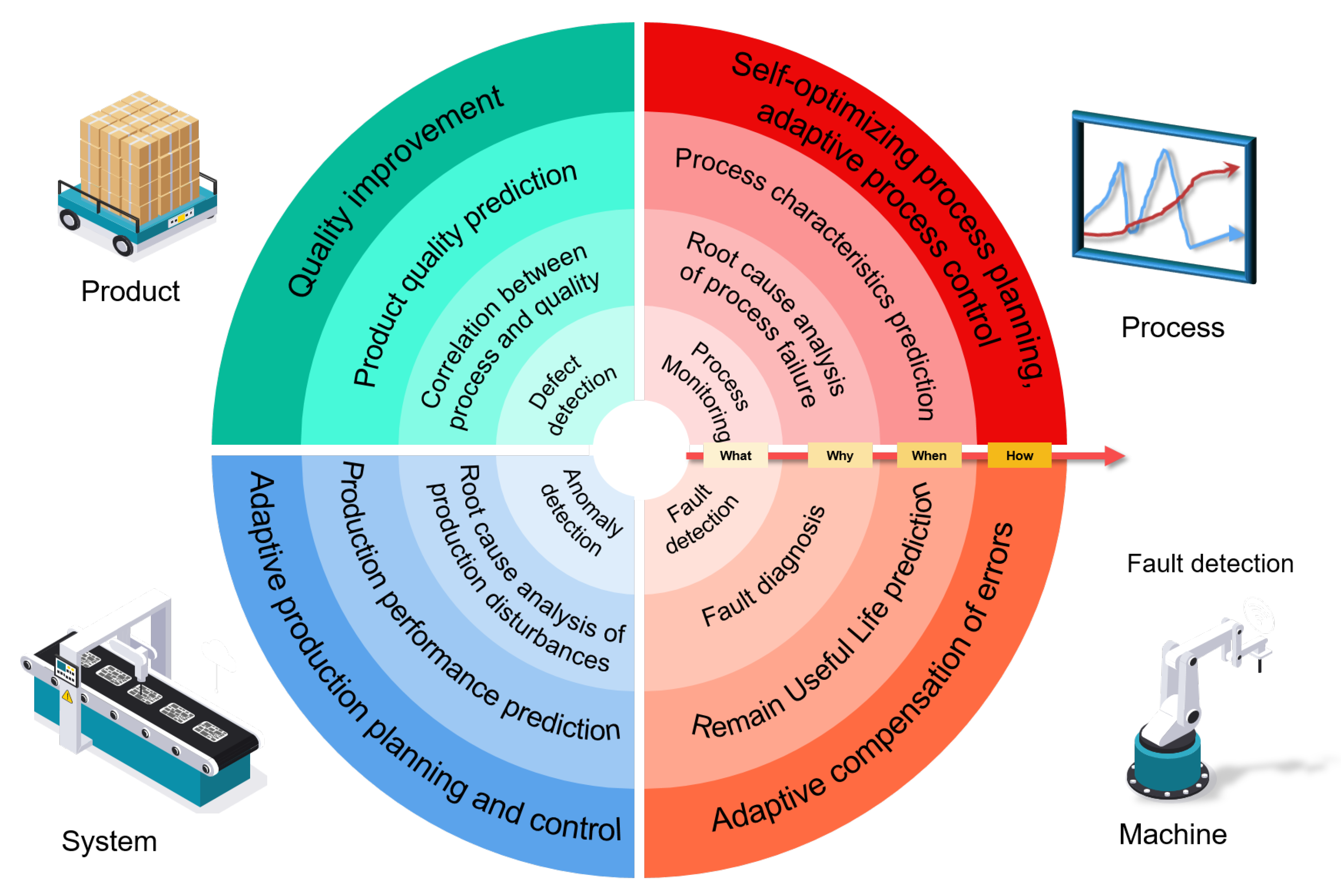
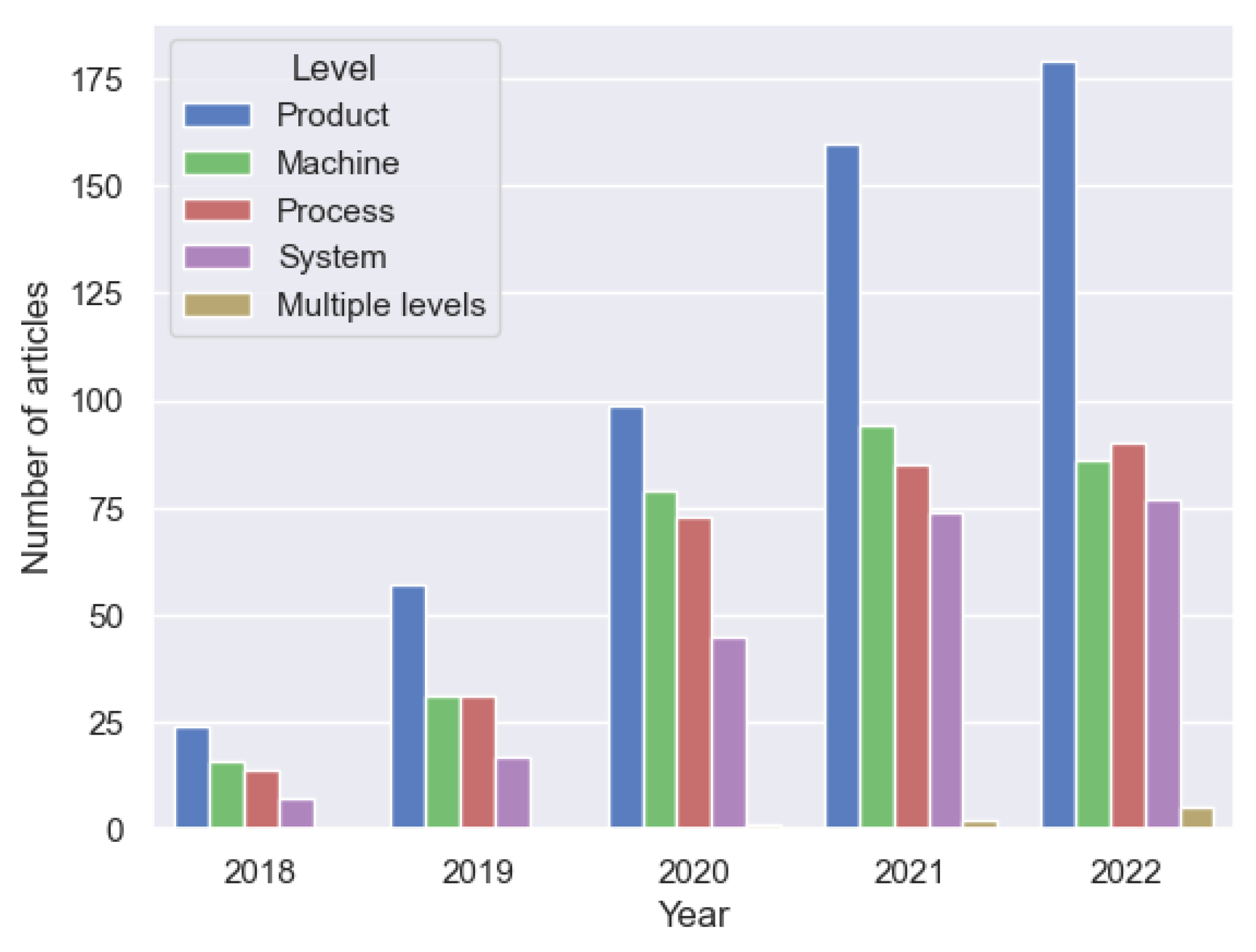
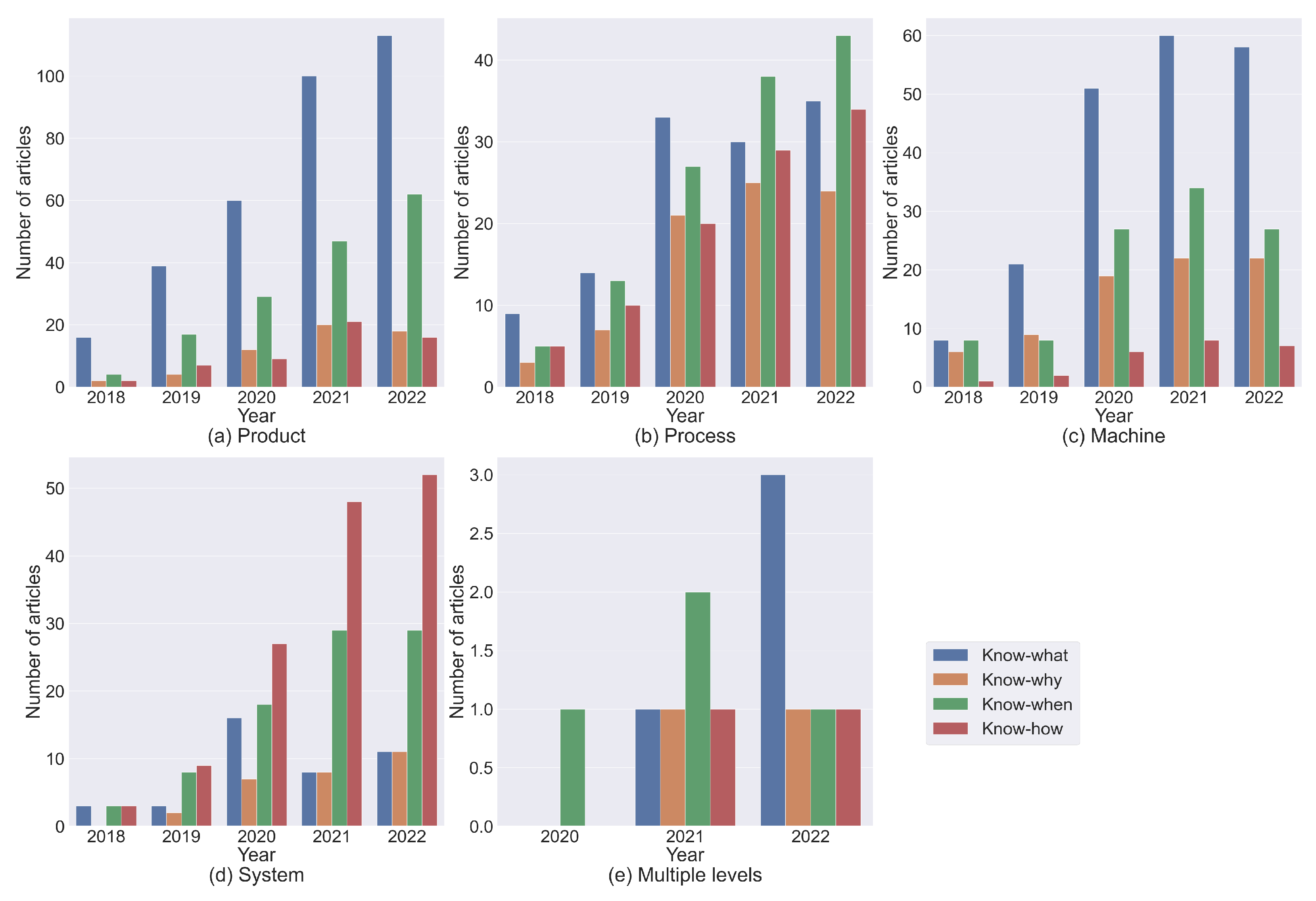
2.1. Introduction of Four-Know and Four-Level
- Know-what deals with understanding of the current states of machines, processes, or production systems, which can help in rapid decision-making. It should be noted that Know-what goes beyond visualization of real-time data. Instead, data should be processed, analyzed, and distilled into information which enables decision-making. For instance, typical examples of Know-what in manufacturing are defect detection in quality control [17,18], fault detection in process/machine monitoring [19,20], and soft sensor modelling [21,22].
- Know-why, based on the information from Know-what, aims to identify inner patterns from historical data, thereby discovering the reasons for a thing happening. Know-why includes the identification of interactions among different variables [23] and the discovery of cause-effect relationship between an event and other variables [24,25]. On one hand, Know-why can indicate most important factors for understanding Know-what. On the other hand, Know-why is the prerequisite for Know-when, as the reliability of predictions is heavily dependent upon the quality of casual inference.
- Know-when, built on Know-why, involves timely predictions of events or prediction of key variables based on historical data, allowing the decision-maker can take actions at early stages. For instance, Know-when in manufacturing includes quality prediction based on relevant variables [26,27], predictive maintenance via detection of incipient anomalies before break-down [28,29], and predicting Remaining Useful Life (RUL) [30,31].
- Know-how, on the foundation of Know-when, can recommend decisions that help adapt to expected disturbance and can aid in self-optimization. Examples in manufacturing include prediction-based process control [27,32], scheduling of predictive maintenance tasks [33,34], dynamic scheduling in the flexible production [35,36], and inventory control [34].
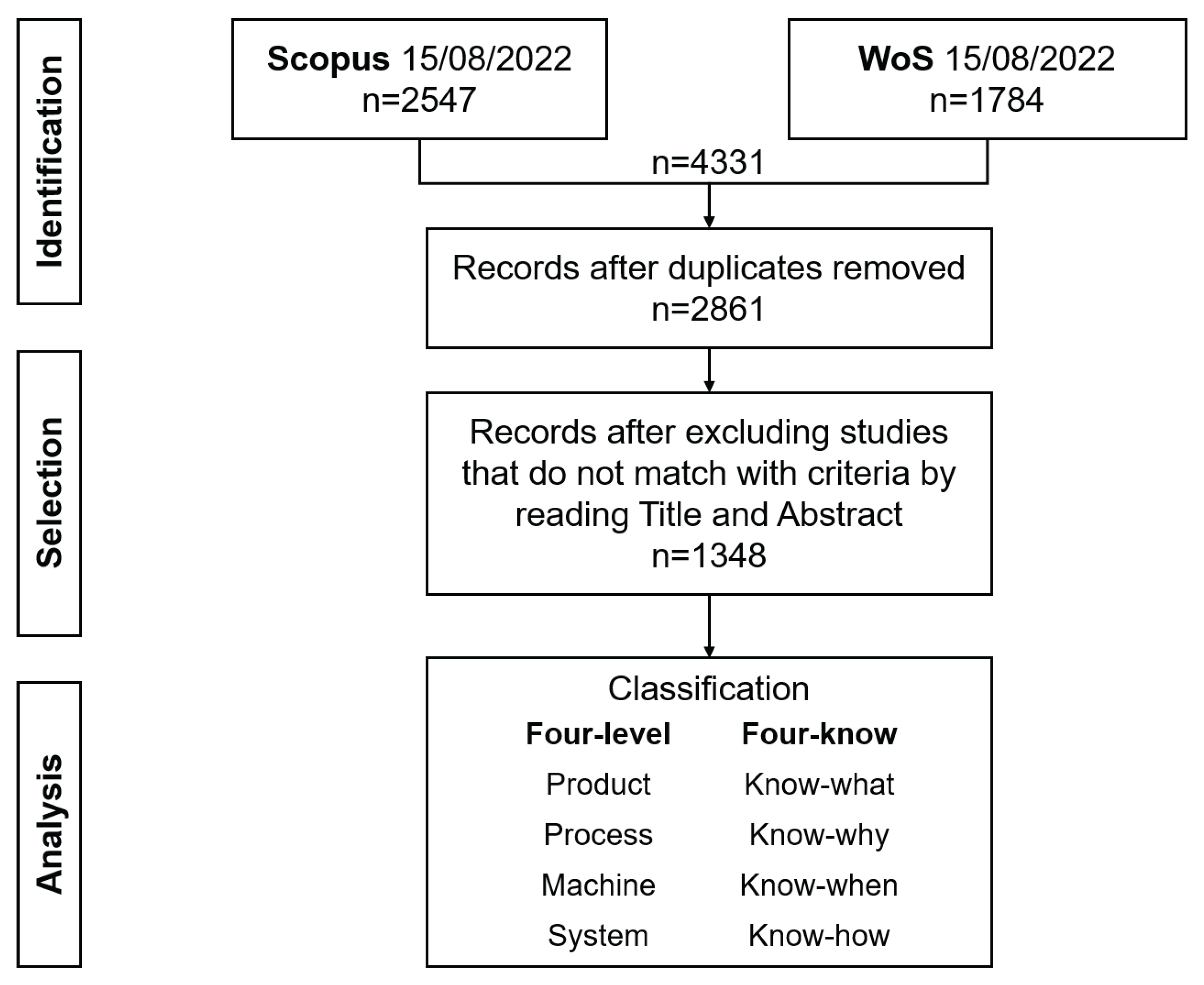
2.2. Literature Review Methodology
- The study dealt with the context of manufacturing;
- The study dealt with ML applications in specific fields.
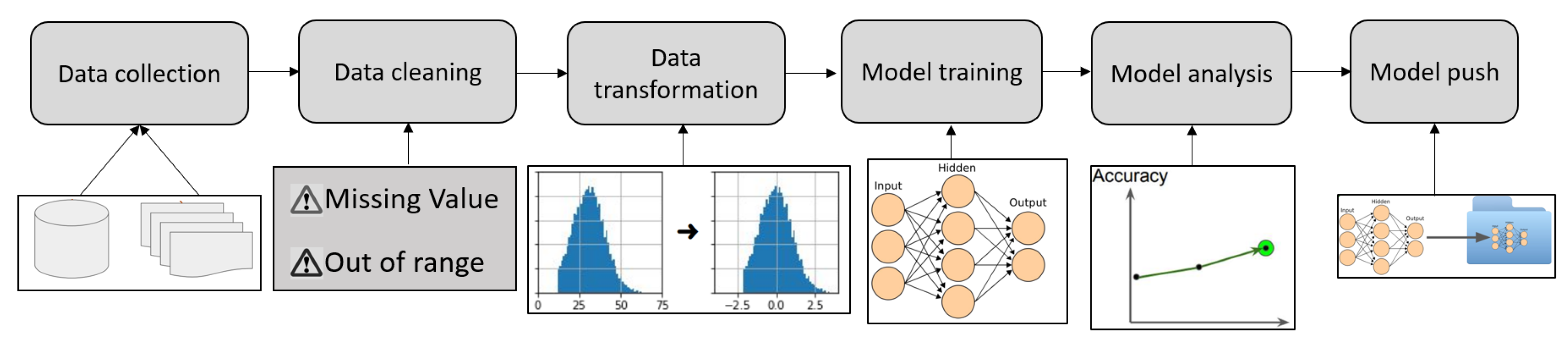
3. Pipeline of Applying Machine Learning in Manufacturing
3.1. Data Collection
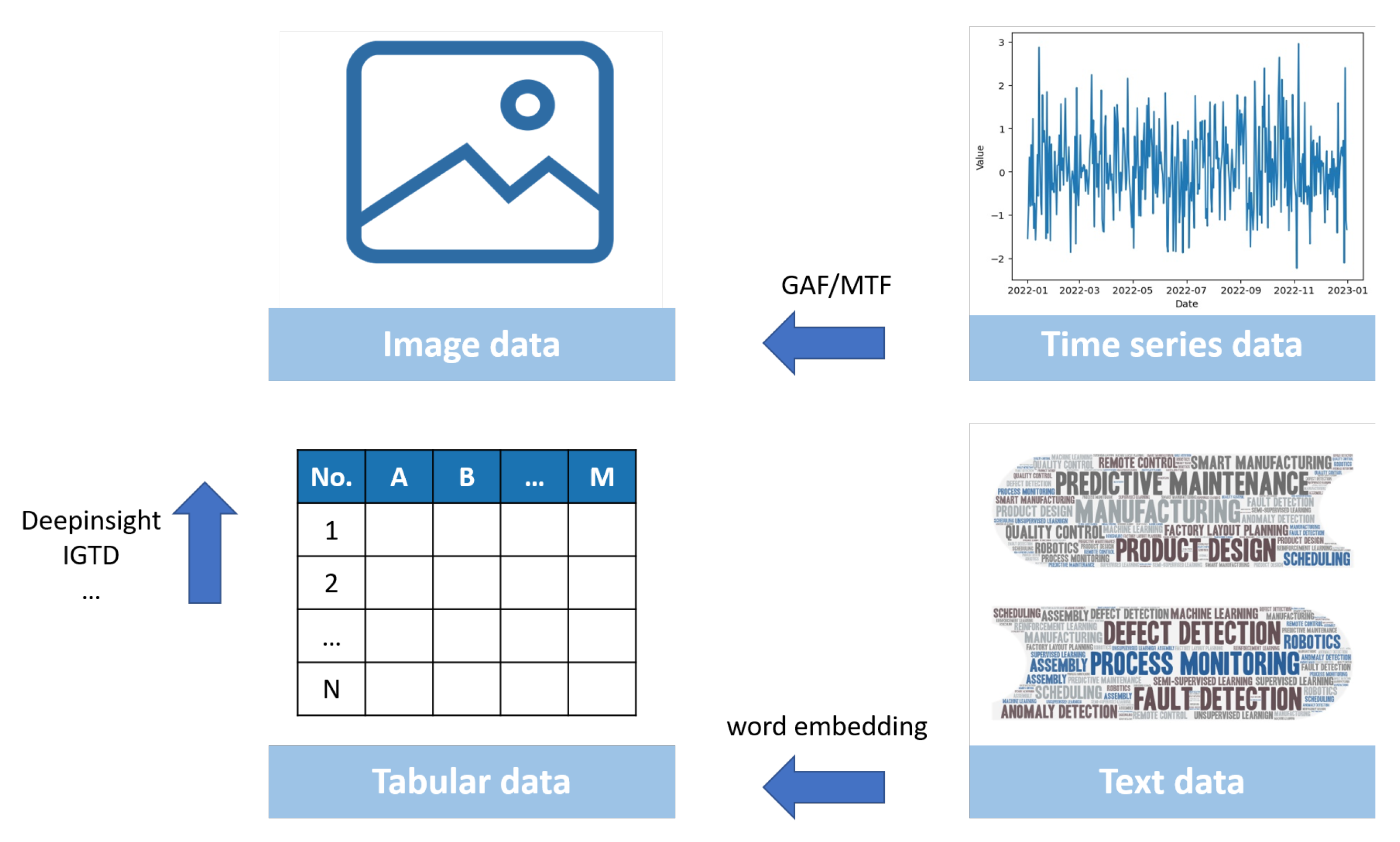
- Image data, matrices of pixels with two or more dimensions, such as gray-scale images or colored images. Image data can acquired by with vision systems, through data transformations such as simple concatenation of several one-dimensional vectors with same length, or by the transformation of images from the spatial domain to the frequency domain.
- Tabular data organized in a table, where normally one axis represents attributes and another axis represents observations. Tabular data are typically observed in production data, where the attributes of events of interest are collected. Though tabular data share a similar data structure with image data, the latter are more focused on one-dimensional interaction among attributes, while image data typically stress spatial interactions in both dimensions.
- Time series data, sequences of one or more attributes over time, with the former corresponding to univariate time series and the latter multivariate time series. In manufacturing, time series data are normally acquired with sensors whenever there is a need for monitoring time flow changes of data.
- Text data, including written documents with words, sentences or paragraphs. Examples of text data in manufacturing include maintenance reports on machines and descriptions of unexpected disturbances or events in production.
3.2. Data Cleaning
3.3. Data Transformation
3.4. Model Training
3.5. Model Analysis
3.6. Model Push
4. Machine Learning Methods and Applications
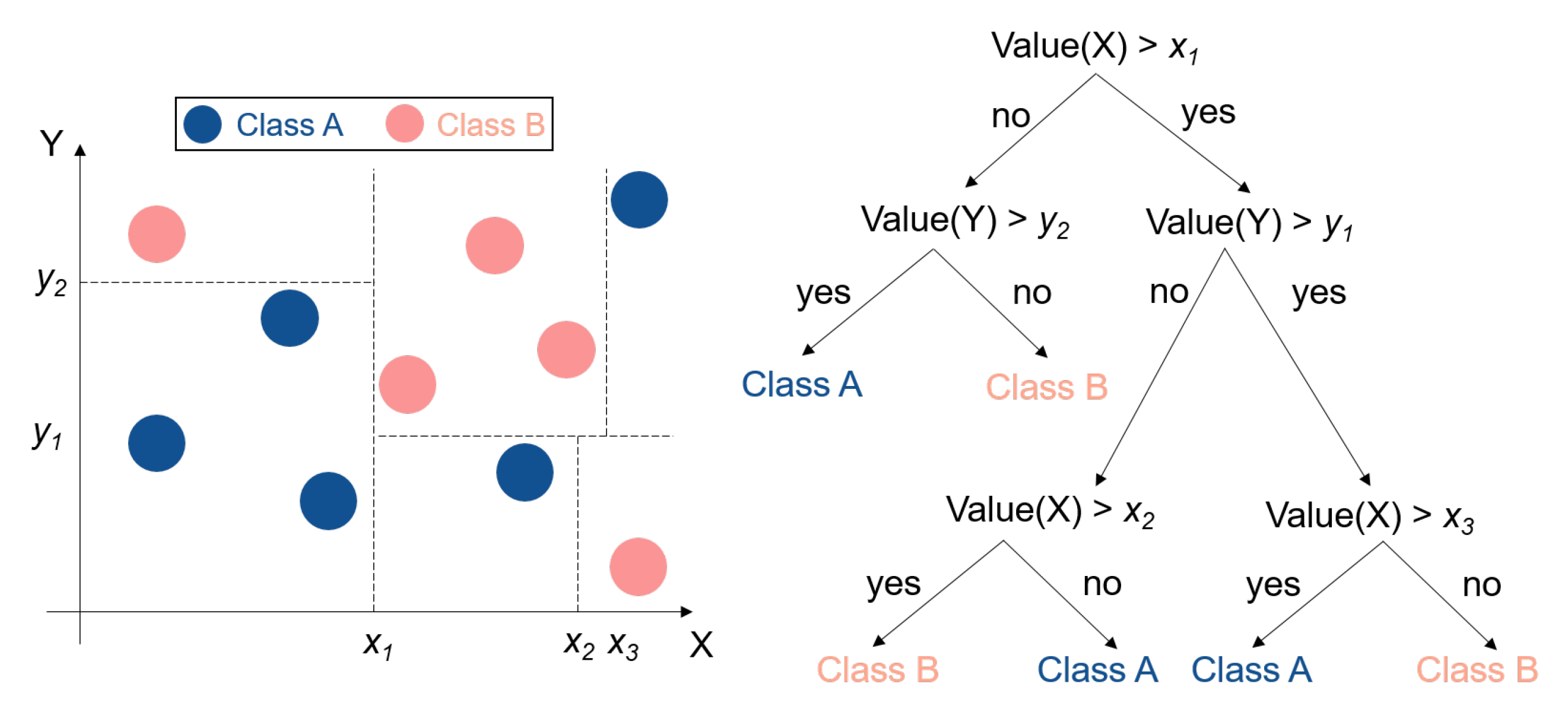
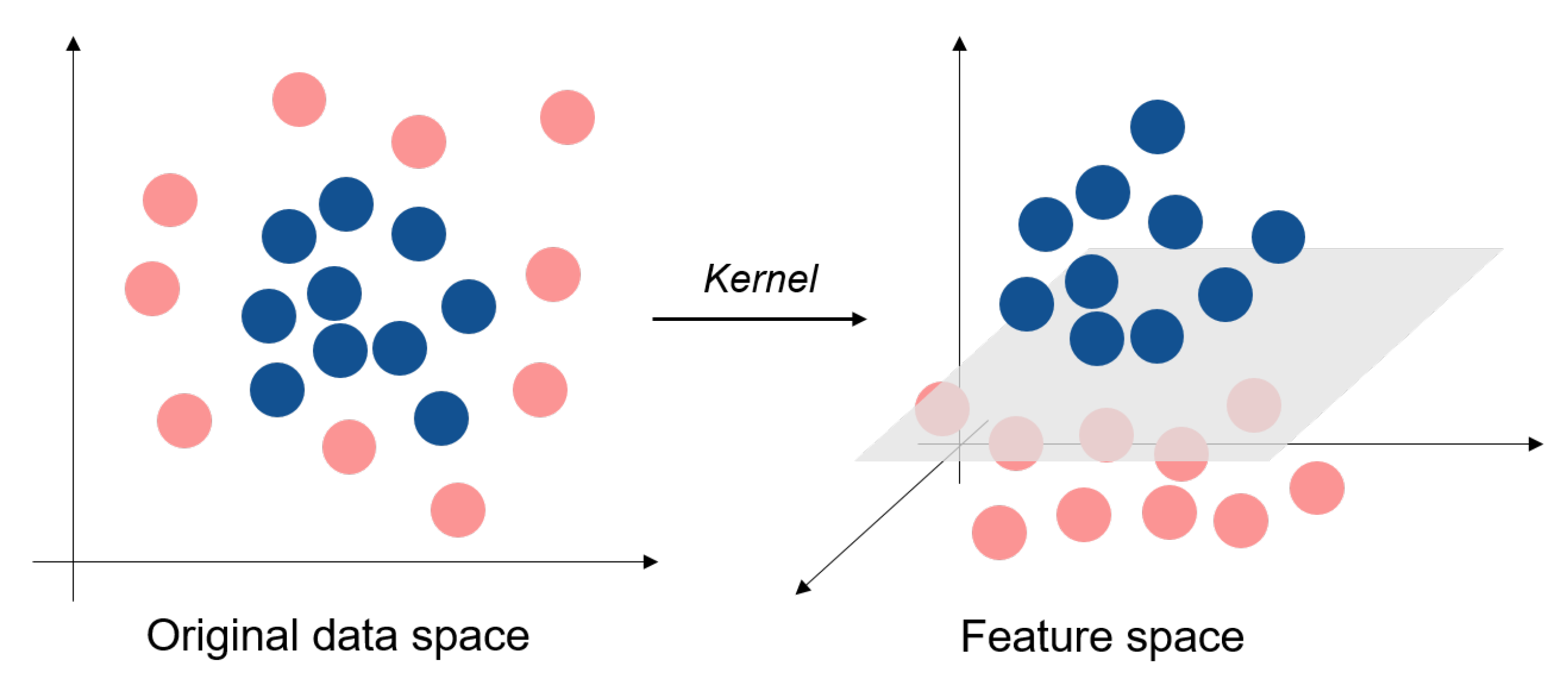
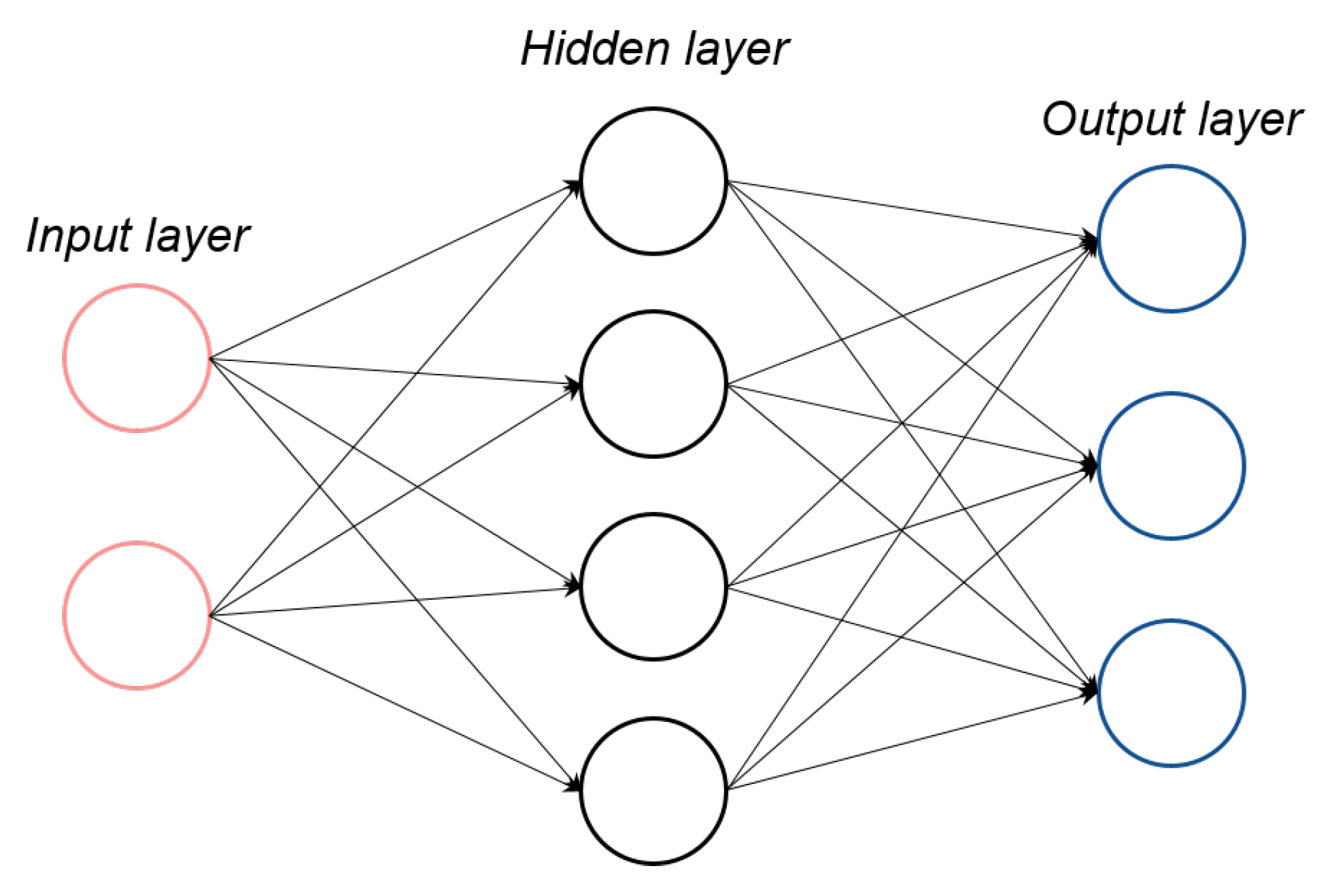
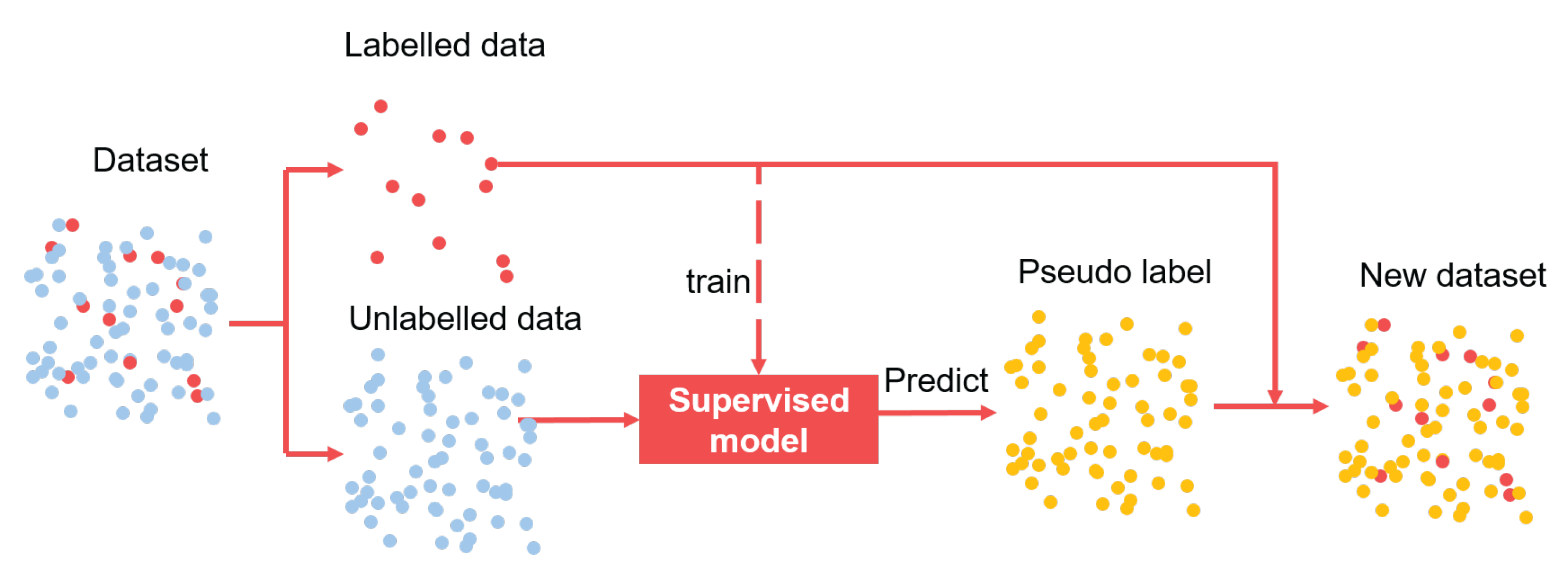
4.1. Supervised Learning Methods
4.2. Unsupervised Learning Methods
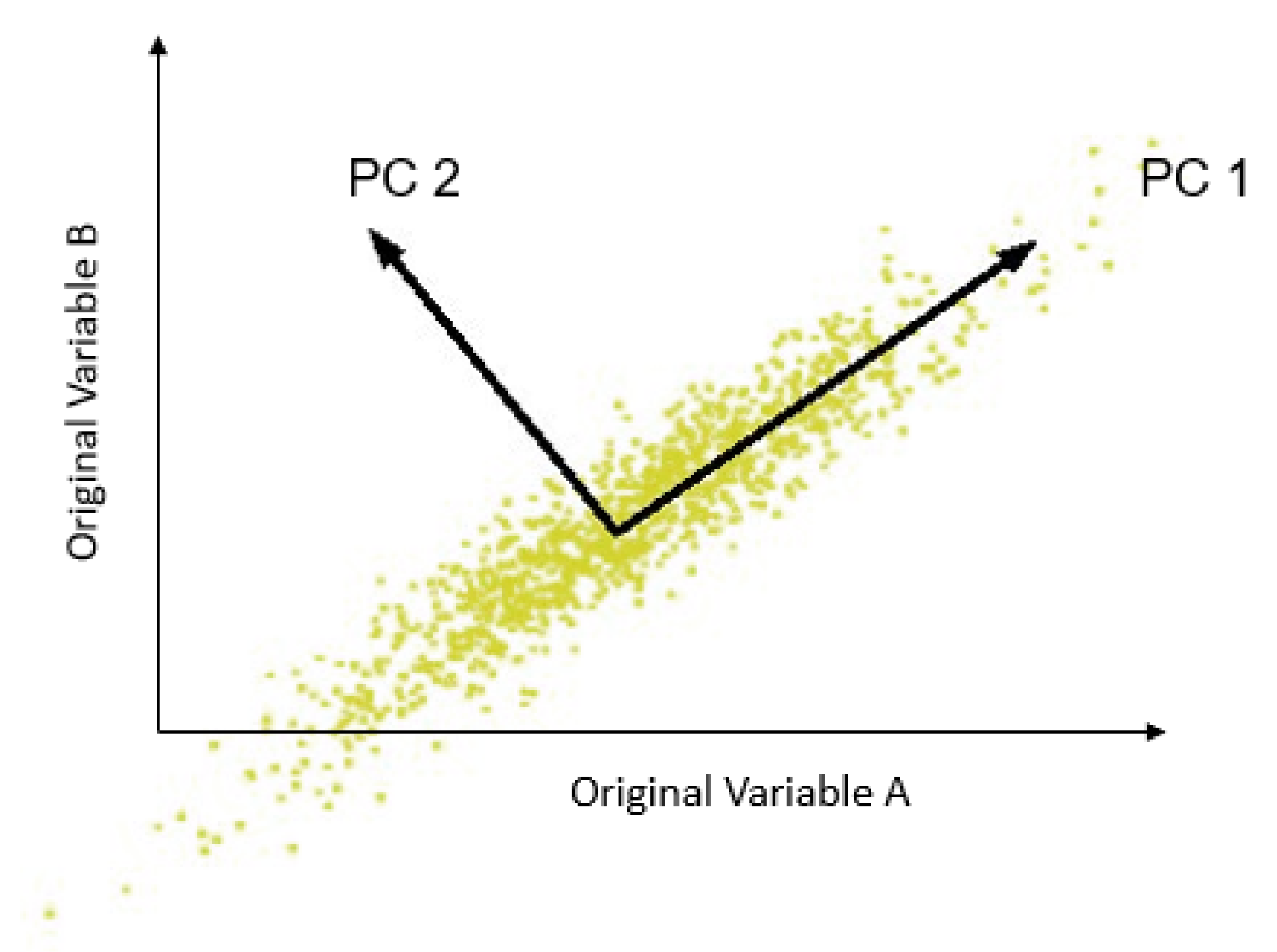
- Say we wish to condense d features in our data matrix X to k features. The first step is to standardize the input data:where is the mean and is the standard deviation.
- Next, it is necessary to find the covariance matrix of the standardized input data. The covariance of variables X and Y can be written as follows:
- The third steps is to find all of the eigenvalues and eigenvectors of the covariance matrix:
- Then, the eigenvector corresponding to the largest eigenvalue is the direction with the maximum variance, the eigenvector corresponding to second-largest eigenvalue is the direction with the second maximum variance, etc.
- To obtain k features, it is necessary to multiply the original data matrix by the matrix of eigenvectors corresponding to the k largest eigenvalues.
- Quality improvement (Know-why, product level): by analyzing the variations of a product’s features, PCA can be used to identify the causes of product defects [122].
- Machine monitoring (Know-why, machine level): by analyzing sensor data from a machine, PCA can be used to detect incipient patterns in the data that indicate potential issues with the machinery, such as wear and tear [123].
- Process optimization (Know-why, process level): by analyzing variations in the process data, PCA can be used to identify the most important factors that affect the process, allowing the manufacturer to optimize the process and thereby reduce costs [124].
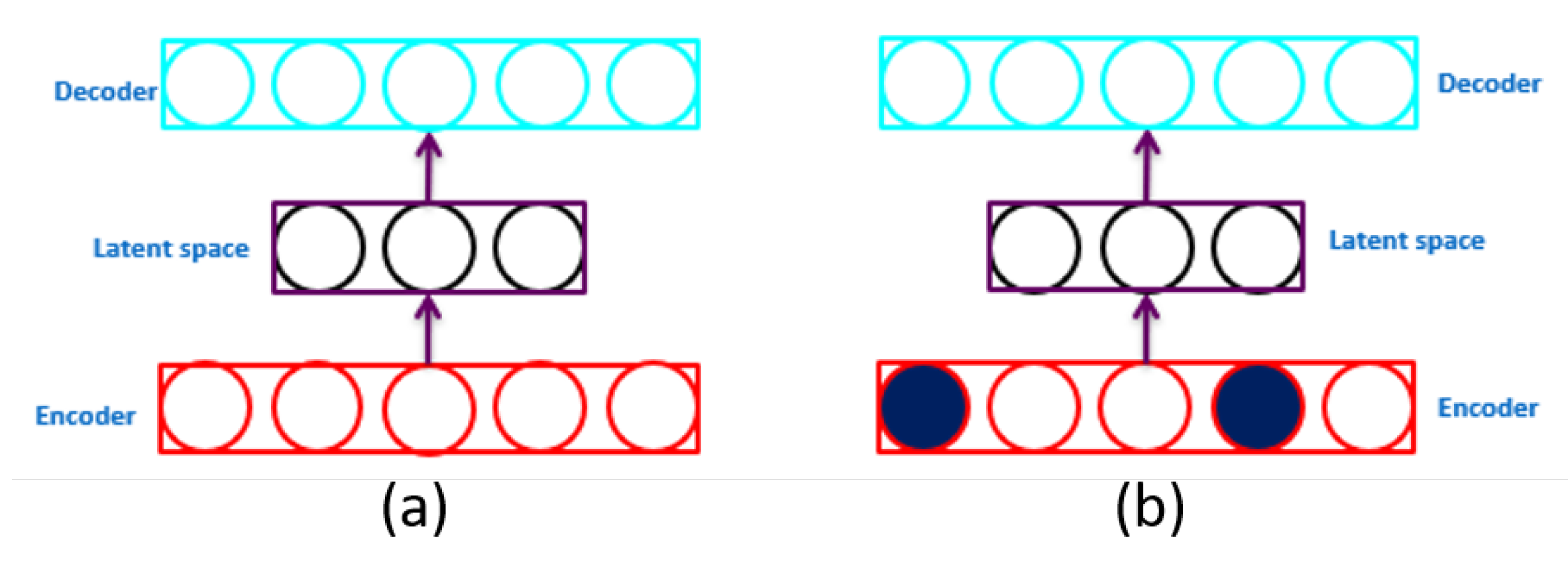
- Feature selection (Know-why): an AE can be used to identify the most important features in the data and remove the noise and irrelevant information, which can be used for diagnosis of product defects or to detect events of interests [128].
- Dimensionality reduction: an AE can be used to reduce the dimensionality of large and complex datasets, making it easier to identify patterns and trends [129].
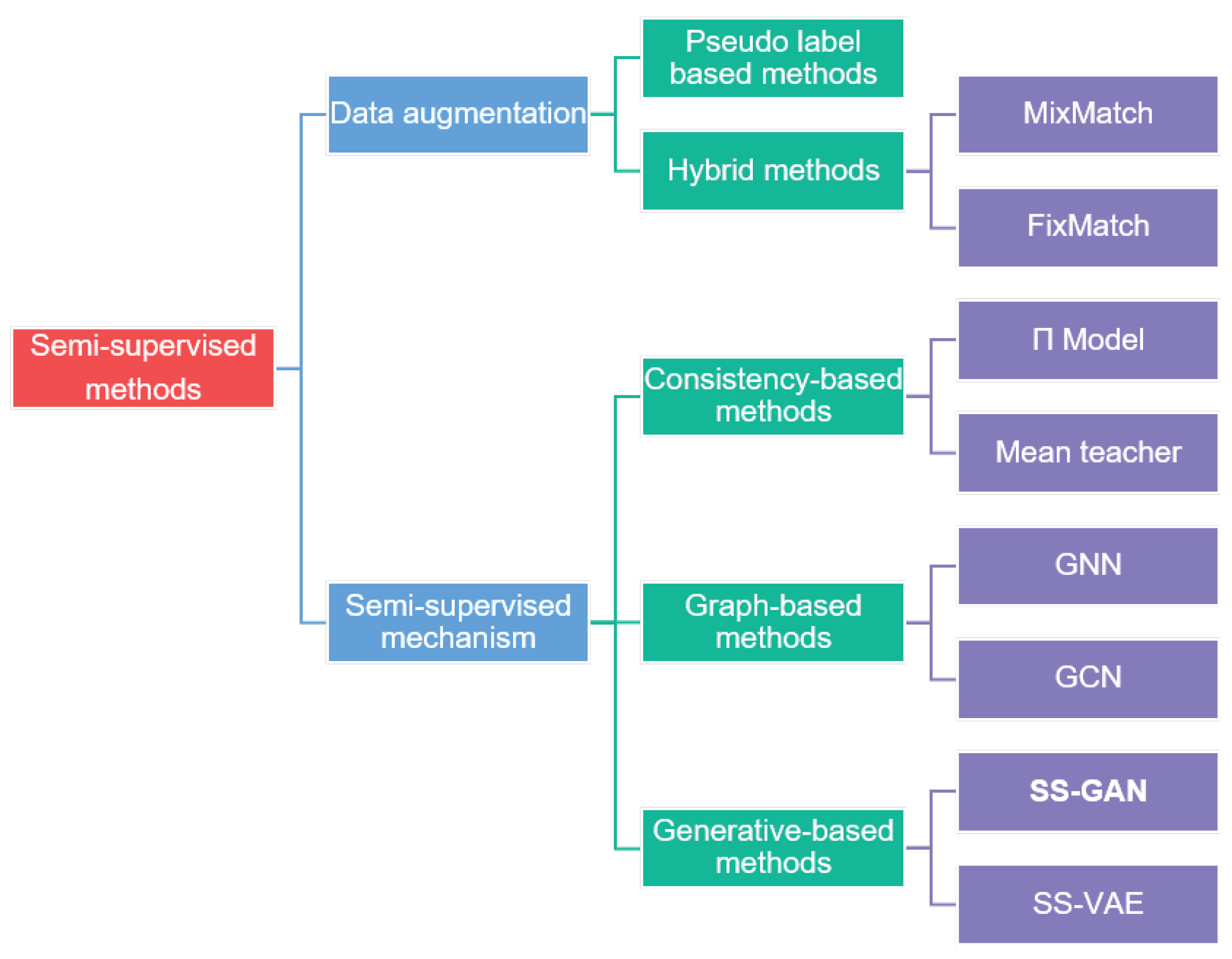
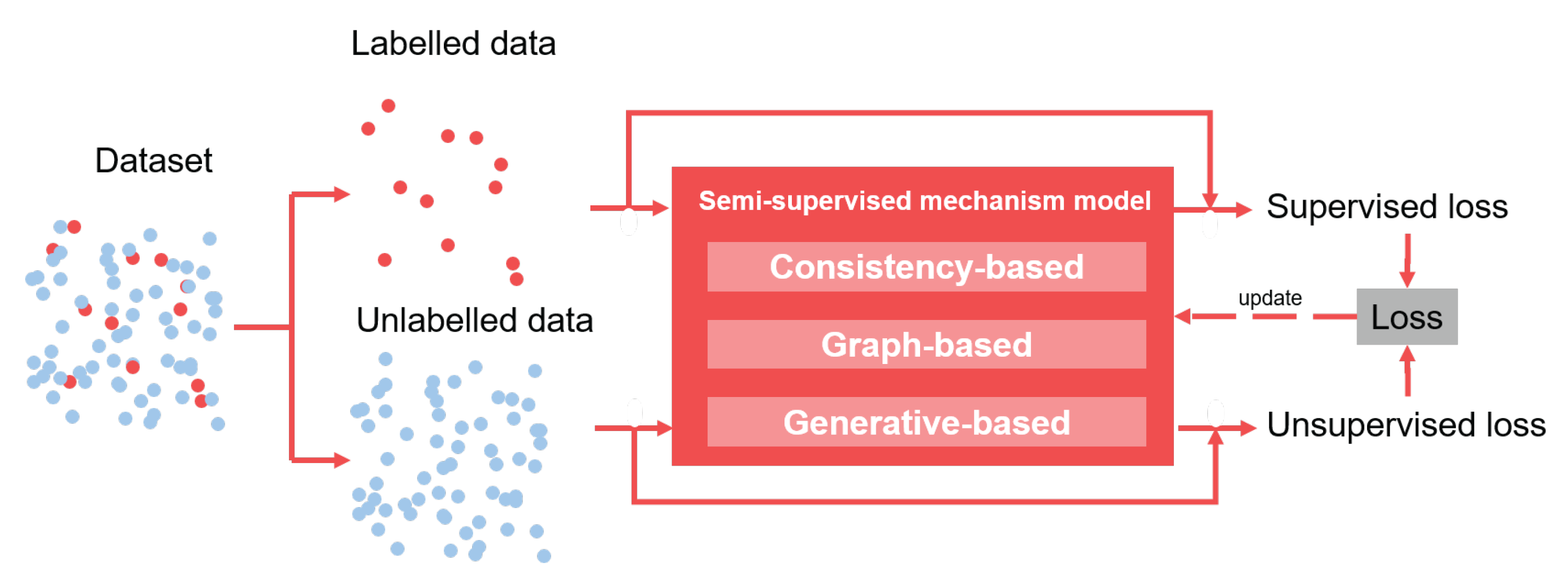
4.3. Semi-Supervised Learning Methods
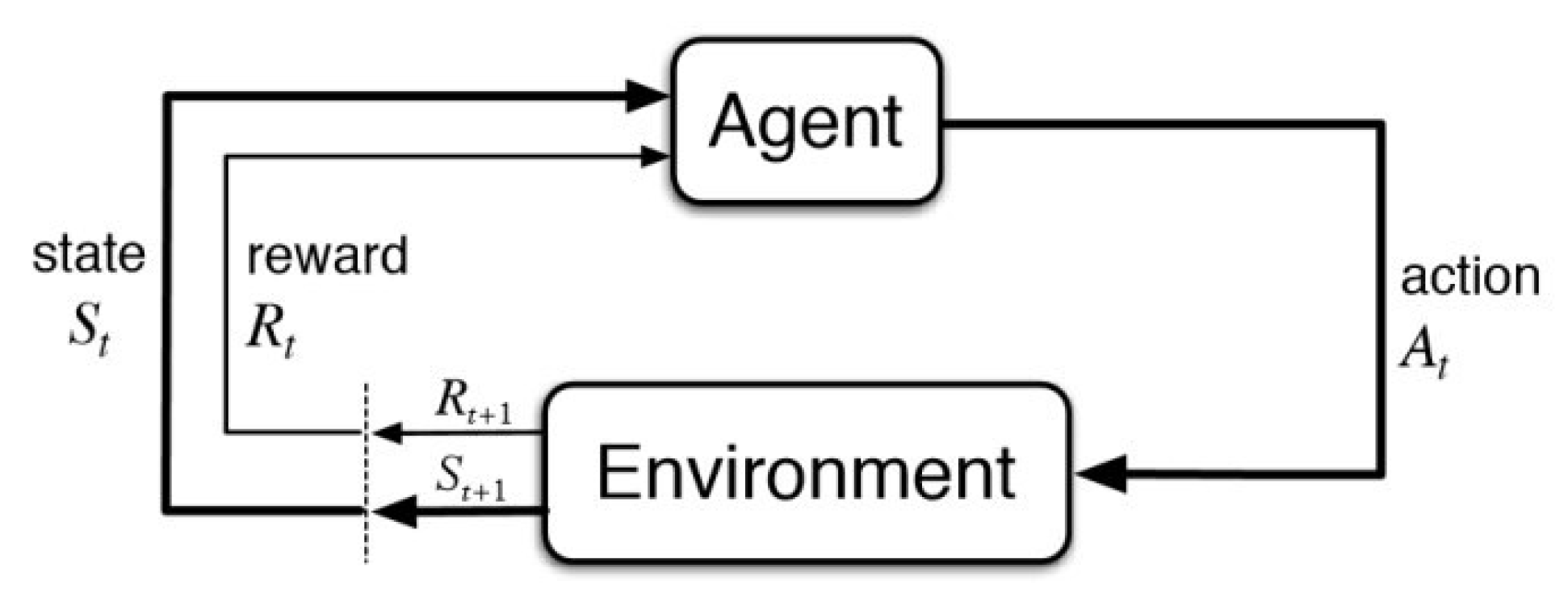
4.4. Reinforcement Learning Methods
5. Challenges and Future Directions
- Lack of data. Preparing the data used for ML is not a simple task, as the scale and the quality of data can greatly affect the performance of ML models. The most common challenge involves preparing a large amount of organized input data, and ensuring high-quality labels if labels are needed. Despite manufacturing data becoming increasingly more accessible due to the development of sensors and the Internet of Things, gathering meaningful data is time-consuming and costly in many cases, for example, fault detection and RUL prediction. This issue might be alleviated by the Synthetic Minority Over-sampling Technique (SMOTE) [162]. However, SMOTE cannot capture complex representative data, as it often relies on interpolation [163]. Data augmentation [139,164] or transfer learning [165] may address this problem. The aim of data augmentation is to enlarge dataset by means of transforming data [139], by transforming both data and labels, as with MixUp [166], or by generating synthetic data using generative models [167,168]. On the contrary, instead of focusing on expanding data, transfer learning aims to leverage knowledge from similar external datasets. A typically used method in transfer learning is parameter transfer, where a pretrained model from a similar dataset is employed for initialization [165]. Another situation involving lack of data is that certain data cannot be shared due to data privacy and security issues. In confronting this problem, Federated Learning (FL) [169] might be a potential opportunity to enable model training across multiple decentralized devices while holding local data privately.
- Limited computing resources. The high performance of ML models always comes with high computational complexity. In particular, obtaining high accuracy with a neural network requires on millions or even billions of parameters [170]. However, limited computing resources in industries makes it a challenge to deploy heavy ML models in real-time industrial environments. Possible approaches include model compression via pruning and sharing of model parameters [171] and knowledge distillation [172]. Parameter pruning aims to reduce the number of model parameters by removing redundant parameters without any effect on model performance. By contrast, seeking the same goal, knowledge distillation focuses on distilling knowledge from a cumbersome neural network to a lightweight network to allow it to be deployed more easily with limited computing resources.
- Changing circumstances. Most ML applications in manufacturing focus only on model development and verification in off-line environments. However, when deploying these models in running production, their performance may be degraded due to changing circumstances, leading to changes in data distribution, that is, drift [173,174]. Therefore, manual model adjustment over time, which is time-consuming, is usually unavoidable [175]. However, this could be addressed in the future by automatic model adaption [174], in which data drifts are automatically detected and handled with less resources.
- Interpretability of results. Many expectations have been placed on ML to overcome all types of problems without the need for prior knowledge. In particular, ML models are expected to directly learn higher level knowledge such as Know-when and Know-how, which is difficult for human beings to obtain in manufacturing. However, without the foundations of early-stage knowledge and an understanding of the data, the results inferred from big data by black-box ML models are meaningless and unreliable. For instance, predictions blindly obtained from all data, including both relevant and irrelevant data, might even degrade performance due to the GIGO (garbage in, garbage out) phenomenon [176]. To overcome this problem, future directions within ML development might include incorporating physical models into ML models [177] or obtaining Four-know knowledge successively.
- Uncertainty of results. Related to the challenge of interpretability is the challenge of uncertain results. The success of manufacturing depends heavily on the quality of the resulting products. As every manufacturing process has a degree of variability, almost all industrial manufacturers use statistical process control (SPC) to ensure a stable and defined quality of products [178]. A central element of statistical process control is the determination and handling of statistical uncertainty. The uncertainty of ML results often cannot be quantified reliably and efficiently, even with today’s state-of-the-art [179,180,181]. Furthermore, model complexity and severe non-linearity in ML can hinder the evaluation of uncertainty [182]. Although there are promising approaches, e.g., Gaussian mixture models for NN [183,184] and Probabilistic Neural Network (PNN) [184], or the use of Baysian Networks [180], there are several limitations limiting potential applications, such as high computational cost and simplified assumptions [184]. Therefore, future research needs to make progress on the general theory of integrating uncertainty into ML methods to allow manufacturing in order to ensure high quality and stability in production.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Level | Know- What | Know- Why | Know- When | Know- How | Data Type | Method Type | Case | Field |
|---|---|---|---|---|---|---|---|---|---|---|
| [104] | 2018 | Product | ✓ | Image | Kernel | Defect detection | Metallic powder bed fusion | |||
| [185] | 2018 | Product | ✓ | Tabular | Kernel | Product monitoring | Metal frame process in mobile device manufacturing | |||
| [186] | 2020 | Process | ✓ | ✓ | ✓ | Time series, Image | Kernel | Temperature prediction and potential anomaly detection | Additive manufacturing | |
| [19] | 2022 | Product, Process | ✓ | ✓ | Tabular | Kernel | Fault detection and classification | Semiconductor Etch Equipment | ||
| [105] | 2022 | Product | ✓ | Tabular | Kernel | Quality prediction | Additive manufacturing | |||
| [106] | 2022 | Machine | ✓ | Time series | Kernel | Wear prediction | Metal forming | |||
| [187] | 2022 | System | ✓ | ✓ | Time series | Kernel | Content prediction | Steel making | ||
| [114] | 2018 | Machine | ✓ | ✓ | Time series (Image) | NN | Fault diagnosis | Motor bearning and pump | ||
| [188] | 2020 | System | ✓ | ✓ | Image | NN | Cost estimation | |||
| [112] | 2020 | Product | ✓ | Image | NN | Defect detection | Battery manufacturing | |||
| [189] | 2022 | Product | ✓ | Time series | NN | Quality assurance | Fused deposition modeling | |||
| [190] | 2022 | Process | ✓ | Time series | NN | Process optimization | Wire arc additive manufacturing | |||
| [191] | 2022 | Process | ✓ | ✓ | Tabular | NN | Parameter optimization | Laser powder bed fusion | ||
| [192] | 2022 | Process | ✓ | Image | NN | Object detection | Robotic grasp | |||
| [193] | 2022 | Product | ✓ | Image | NN, kernel | Defect detection | Roller manufacturing | |||
| [194] | 2022 | Machine | ✓ | Time series (Image) | NN, kernel | Tool condition monitoring | Machining | |||
| [195] | 2019 | Product | ✓ | Time series | Tree | Material removal prediction | Robotic grinding | |||
| [196] | 2022 | Product | ✓ | Image (Tabular) | Tree | Porosity prediction | Powder-bed additive manufacturing | |||
| [197] | 2019 | Product | ✓ | Image | Probabilistic | Online quality inspection | Powder-bed additive manufacturing | |||
| [198] | 2018 | System | ✓ | Tabular | Hybrid | Scheduling | Flexible Manufacturing Systems (FMSs) |
| Ref. | Year | Level | Know- What | Know- Why | Know- When | Know- How | Data Type | Method Type | Case | Field |
|---|---|---|---|---|---|---|---|---|---|---|
| [120] | 2021 | Machine | ✓ | Time series | Clustering | Tool Condition clustering | Autonomous manufacturing | |||
| [131] | 2021 | Machine | ✓ | Time series | Clustering | Tool health monitoring | Machine tool health Monitoring | |||
| [132] | 2019 | Machine | ✓ | ✓ | Time series | Clustering | Defect Identification | Manufacturing systems | ||
| [199] | 2021 | Process | ✓ | Tabular, Time series | Clustering | Condition monitoring | Manufacturing Condition monitoring | |||
| [133] | 2020 | System | ✓ | Time series | Clustering | Condition monitoring | Manufacturing Condition monitoring | |||
| [125] | 2018 | Product | ✓ | Image, Text | Autoencoder | Defect Identification | Fabric industry | |||
| [119] | 2019 | Product | ✓ | Image | Autoencoder | Defect Identification | Automatic Optical Inspection | |||
| [200] | 2021 | Product | ✓ | Image | Autoencoder | Defect Identification | Printed circuit board manufacturing | |||
| [201] | 2022 | Machine | ✓ | ✓ | Tabular, Time series | Autoencoder | Anomaly detection | Steel rolling Process | ||
| [126] | 2022 | Process | ✓ | ✓ | Image | Autoencoder | Anomaly detection | Industrial Anomaly detection | ||
| [126] | 2022 | Process | ✓ | ✓ | Image, Text | Autoencoder | Anomaly detection | Semi conductor manufacturing | ||
| [202] | 2022 | Machine | ✓ | Time series | PCA | Predictive maintenance | Fan-motor system | |||
| [118] | 2022 | Machine | ✓ | ✓ | Time series | PCA | Anomaly detection | Programmable logic controllers | ||
| [121] | 2015 | Process | ✓ | Tabular | Association rule | Predictive maintenance | Wooden door manufacturing |
| Ref. | Year | Level | Know- What | Know- Why | Know- When | Know- How | Data Type | Method Type | Case | Field |
|---|---|---|---|---|---|---|---|---|---|---|
| [203] | 2020 | Product | ✓ | Image | Data augmentation | Quality control | Automated Surface Inspection | |||
| [204] | 2021 | Process | ✓ | Image | Data augmentation | Measurement in process | Positioning of welding seams | |||
| [205] | 2019 | System | ✓ | Tabular | Data augmentation | Energy consumption modelling | Steel industry | |||
| [206] | 2020 | Product, System | ✓ | Time series | Data augmentation | Quality prediction | Continuous-flow manufacturing. | |||
| [207] | 2021 | Machine | ✓ | Time series | Consistency-based | Predictive quality control | Semiconductor manufacturing | |||
| [149] | 2020 | Product | ✓ | Image | Consistency-based | Quality monitoring | Metal additive manufacturing | |||
| [18] | 2021 | Product | ✓ | Image | Graph-based | Quality control | Automated Surface Inspection | |||
| [150] | 2022 | Machine | ✓ | ✓ | Time series | Graph-based | Machine health state diagnosis | Manipulator | ||
| [208] | 2022 | Machine | ✓ | ✓ | Tabular | Graph-based | Predict tool tip dynamics | Machine tool | ||
| [209] | 2021 | Product | ✓ | Image | Generative-based | Assessing manufacturability of cellular structures | Direct metal laser sintering process | |||
| [210] | 2019 | Product | ✓ | Time series | Generative-based | Quality inferred from process | laser powder-bed fusion | |||
| [211] | 2020 | Product | ✓ | Image | Generative-based | Quality diagnosis | Wafer fabrication | |||
| [212] | 2021 | Product | ✓ | Image | Generative-based | Quality control | Automated Surface Inspection | |||
| [213] | 2020 | Machine | ✓ | Time series | Generative-based | Remaining useful life prognostics | Turbofan engine and rolling bearing | |||
| [214] | 2021 | Machine | ✓ | ✓ | Tabular | Generative-based | Machine condition monitoring | Vacuum system in styrene petrochemical plant | ||
| [153] | 2021 | Machine | ✓ | ✓ | Time series | Generative-based | Anomaly detection for predictive maintenance | Press machine | ||
| [154] | 2022 | Process | ✓ | Time series (image) | Generative-based | Process fault detection | Die casting process |
| Ref. | Year | Level | Know- What | Know- Why | Know- When | Know- How | Data Type | Method Type | Case | Field |
|---|---|---|---|---|---|---|---|---|---|---|
| [32] | 2021 | Process | ✓ | ✓ | Tabular | Value-based | Quality control | Statistical Process Control | ||
| [215] | 2022 | System | ✓ | ✓ | Tabular | Value-based | Scheduling | Semiconductor fab | ||
| [216] | 2021 | System | ✓ | Tabular | Value-based | Throughput control | Flow shop | |||
| [217] | 2021 | Machine | ✓ | Tabular | Value-based | Scheduling & Maintenance | Multi-state single machine | |||
| [34] | 2020 | System | ✓ | Tabular | Value-based | Quality Control & Maintenance | Production system | |||
| [218] | 2022 | System | ✓ | Tabular | Value-based | Lead time management | Flow shop | |||
| [219] | 2020 | Process | ✓ | Tabular | Value-based | Robotic arm control | Soft fabric manufacturing | |||
| [220] | 2021 | System | ✓ | ✓ | Tabular | Value-based | Layout planning | Greenfield factories | ||
| [221] | 2020 | Machine | ✓ | Tabular | Value-based | Maintenance scheduling | Preventive maintenance | |||
| [33] | 2022 | Machine | ✓ | ✓ | Tabular | Policy-based | Maintenance scheduling | Parallel machines | ||
| [222] | 2021 | Process | ✓ | Tabular | Policy-based | Improving efficiency | Automated product disassembly | |||
| [223] | 2021 | System | ✓ | Tabular | Policy-based | Dispatching | Job shop | |||
| [224] | 2022 | System | ✓ | Tabular | Policy-based | Scheduling & maintenance | Semiconductor fab | |||
| [225] | 2022 | System | ✓ | Tabular | Policy-based | Yield optimization | Multi-agent RL | |||
| [57] | 2022 | System | ✓ | Tabular | Policy-based | Human Worker Control | Flow shop | |||
| [59] | 2022 | System | ✓ | Tabular | Policy-based | Scheduling & dispatching | Disassembly job shop | |||
| [160] | 2021 | Product | ✓ | Tabular | Policy-based | Multi-agent production control | Job shop | |||
| [226] | 2022 | Process | ✓ | Tabular | Both | Parameter optimisation | Manufacturing processes | |||
| [227] | 2019 | Process | ✓ | Tabular | Both | Online parameter optimisation | Injection molding | |||
| [228] | 2022 | System | ✓ | Tabular | Both | scheduling | Matrix production system |
References
- Abele, E.; Reinhart, G. Zukunft der Produktion: Herausforderungen, Forschungsfelder, Chancen; Hanser: München, Germany, 2011. [Google Scholar]
- Zizic, M.C.; Mladineo, M.; Gjeldum, N.; Celent, L. From industry 4.0 towards industry 5.0: A review and analysis of paradigm shift for the people, organization and technology. Energies 2022, 15, 5221. [Google Scholar] [CrossRef]
- Huang, S.; Wang, B.; Li, X.; Zheng, P.; Mourtzis, D.; Wang, L. Industry 5.0 and Society 5.0—Comparison, complementation and co-evolution. J. Manuf. Syst. 2022, 64, 424–428. [Google Scholar] [CrossRef]
- Vukovic, M.; Mazzei, D.; Chessa, S.; Fantoni, G. Digital Twins in Industrial IoT: A survey of the state of the art and of relevant standards. In Proceedings of the 2021 IEEE International Conference on Communications Workshops (ICC Workshops), Montreal, QC, Canada, 14–23 June 2021. [Google Scholar] [CrossRef]
- Mourtzis, D.; Fotia, S.; Boli, N.; Vlachou, E. Modelling and quantification of industry 4.0 manufacturing complexity based on information theory: A robotics case study. Int. J. Prod. Res. 2019, 57, 6908–6921. [Google Scholar] [CrossRef]
- Galin, R.; Meshcheryakov, R.; Kamesheva, S.; Samoshina, A. Cobots and the benefits of their implementation in intelligent manufacturing. IOP Conf. Ser. Mater. Sci. Eng. 2020, 862, 032075. [Google Scholar] [CrossRef]
- May, M.C.; Schmidt, S.; Kuhnle, A.; Stricker, N.; Lanza, G. Product Generation Module: Automated Production Planning for optimized workload and increased efficiency in Matrix Production Systems. Procedia CIRP 2020, 96, 45–50. [Google Scholar] [CrossRef]
- Lu, Y. Industry 4.0: A survey on technologies, applications and open research issues. J. Ind. Inf. Integr. 2017, 6, 1–10. [Google Scholar] [CrossRef]
- Miqueo, A.; Torralba, M.; Yagüe-Fabra, J.A. Lean manual assembly 4.0: A systematic review. Appl. Sci. 2020, 10, 8555. [Google Scholar] [CrossRef]
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K.D. Machine learning in manufacturing: Advantages, challenges, and applications. Prod. Manuf. Res. 2016, 4, 23–45. [Google Scholar] [CrossRef]
- Rai, R.; Tiwari, M.K.; Ivanov, D.; Dolgui, A. Machine learning in manufacturing and industry 4.0 applications. Int. J. Prod. Res. 2021, 59, 4773–4778. [Google Scholar] [CrossRef]
- Bertolini, M.; Mezzogori, D.; Neroni, M.; Zammori, F. Machine Learning for industrial applications: A comprehensive literature review. Expert Syst. Appl. 2021, 175, 114820. [Google Scholar] [CrossRef]
- Wang, J.; Ma, Y.; Zhang, L.; Gao, R.X.; Wu, D. Deep learning for smart manufacturing: Methods and applications. J. Manuf. Syst. 2018, 48, 144–156. [Google Scholar] [CrossRef]
- Dogan, A.; Birant, D. Machine learning and data mining in manufacturing. Expert Syst. Appl. 2021, 166, 114060. [Google Scholar] [CrossRef]
- Alshangiti, M.; Sapkota, H.; Murukannaiah, P.K.; Liu, X.; Yu, Q. Why is developing machine learning applications challenging? a study on stack overflow posts. In Proceedings of the 2019 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), Porto de Galinhas, Brazil, 19–20 September 2019; pp. 1–11. [Google Scholar]
- Zeller, V.; Hocken, C.; Stich, V. Acatech Industrie 4.0 maturity index—A multidimensional maturity model. In Proceedings of the IFIP International Conference on Advances in Production Management Systems, Seoul, Republic of Korea, 26–30 August 2018; Springer: Cham, Switzerland, 2018; pp. 105–113. [Google Scholar]
- Yang, L.; Fan, J.; Huo, B.; Li, E.; Liu, Y. A nondestructive automatic defect detection method with pixelwise segmentation. Knowl.-Based Syst. 2022, 242, 108338. [Google Scholar] [CrossRef]
- Wang, Y.; Gao, L.; Gao, Y.; Li, X. A new graph-based semi-supervised method for surface defect classification. Robot. Comput. Integr. Manuf. 2021, 68, 102083. [Google Scholar] [CrossRef]
- Kim, S.H.; Kim, C.Y.; Seol, D.H.; Choi, J.E.; Hong, S.J. Machine Learning-Based Process-Level Fault Detection and Part-Level Fault Classification in Semiconductor Etch Equipment. IEEE Trans. Semicond. Manuf. 2022, 35, 174–185. [Google Scholar] [CrossRef]
- Peng, S.; Feng, Q.M. Reinforcement learning with Gaussian processes for condition-based maintenance. Comput. Ind. Eng. 2021, 158, 107321. [Google Scholar] [CrossRef]
- Zheng, W.; Liu, Y.; Gao, Z.; Yang, J. Just-in-time semi-supervised soft sensor for quality prediction in industrial rubber mixers. Chemom. Intell. Lab. Syst. 2018, 180, 36–41. [Google Scholar] [CrossRef]
- Kang, P.; Kim, D.; Cho, S. Semi-supervised support vector regression based on self-training with label uncertainty: An application to virtual metrology in semiconductor manufacturing. Expert Syst. Appl. 2016, 51, 85–106. [Google Scholar] [CrossRef]
- Srivastava, A.K.; Patra, P.K.; Jha, R. AHSS applications in Industry 4.0: Determination of optimum processing parameters during coiling process through unsupervised machine learning approach. Mater. Today Commun. 2022, 31, 103625. [Google Scholar] [CrossRef]
- Antomarioni, S.; Ciarapica, F.E.; Bevilacqua, M. Association rules and social network analysis for supporting failure mode effects and criticality analysis: Framework development and insights from an onshore platform. Saf. Sci. 2022, 150, 105711. [Google Scholar] [CrossRef]
- Pan, R.; Li, X.; Chakrabarty, K. Semi-Supervised Root-Cause Analysis with Co-Training for Integrated Systems. In Proceedings of the 2022 IEEE 40th VLSI Test Symposium (VTS), San Diego, CA, USA, 25–27 April 2022. [Google Scholar] [CrossRef]
- Chen, R.; Lu, Y.; Witherell, P.; Simpson, T.W.; Kumara, S.; Yang, H. Ontology-Driven Learning of Bayesian Network for Causal Inference and Quality Assurance in Additive Manufacturing. IEEE Robot. Autom. Lett. 2021, 6, 6032–6038. [Google Scholar] [CrossRef]
- Sikder, S.; Mukherjee, I.; Panja, S.C. A synergistic Mahalanobis–Taguchi system and support vector regression based predictive multivariate manufacturing process quality control approach. J. Manuf. Syst. 2020, 57, 323–337. [Google Scholar] [CrossRef]
- Cerquitelli, T.; Ventura, F.; Apiletti, D.; Baralis, E.; Macii, E.; Poncino, M. Enhancing manufacturing intelligence through an unsupervised data-driven methodology for cyclic industrial processes. Expert Syst. Appl. 2021, 182, 115269. [Google Scholar] [CrossRef]
- Kolokas, N.; Vafeiadis, T.; Ioannidis, D.; Tzovaras, D. A generic fault prognostics algorithm for manufacturing industries using unsupervised machine learning classifiers. Simul. Model. Pract. Theory 2020, 103, 102109. [Google Scholar] [CrossRef]
- Verstraete, D.; Droguett, E.; Modarres, M. A deep adversarial approach based on multisensor fusion for remaining useful life prognostics. In Proceedings of the 29th European Safety and Reliability Conference (ESREL 2019), Hannover, Germany, 22–26 September 2020; pp. 1072–1077. [Google Scholar] [CrossRef]
- Wu, D.; Jennings, C.; Terpenny, J.; Gao, R.X.; Kumara, S. A Comparative Study on Machine Learning Algorithms for Smart Manufacturing: Tool Wear Prediction Using Random Forests. J. Manuf. Sci. Eng. Trans. ASME 2017, 139, 071018. [Google Scholar] [CrossRef]
- Viharos, Z.J.; Jakab, R. Reinforcement Learning for Statistical Process Control in Manufacturing. Meas. J. Int. Meas. Confed. 2021, 182, 109616. [Google Scholar] [CrossRef]
- Luis, M.; Rodríguez, R.; Kubler, S.; Giorgio, A.D.; Cordy, M.; Robert, J.; Le, Y. Multi-agent deep reinforcement learning based Predictive Maintenance on parallel machines. Robot. Comput. Integr. Manuf. 2022, 78, 102406. [Google Scholar]
- Paraschos, P.D.; Koulinas, G.K.; Koulouriotis, D.E. Reinforcement learning for combined production-maintenance and quality control of a manufacturing system with deterioration failures. J. Manuf. Syst. 2020, 56, 470–483. [Google Scholar] [CrossRef]
- Liu, Y.H.; Huang, H.P.; Lin, Y.S. Dynamic scheduling of flexible manufacturing system using support vector machines. In Proceedings of the 2005 IEEE Conference on Automation Science and Engineering, IEEE-CASE 2005, Edmonton, AB, Canada, 1–2 August 2005; Volume 2005, pp. 387–392. [Google Scholar] [CrossRef]
- Zhou, G.; Chen, Z.; Zhang, C.; Chang, F. An adaptive ensemble deep forest based dynamic scheduling strategy for low carbon flexible job shop under recessive disturbance. J. Clean. Prod. 2022, 337, 130541. [Google Scholar] [CrossRef]
- de la Rosa, F.L.; Gómez-Sirvent, J.L.; Sánchez-Reolid, R.; Morales, R.; Fernández-Caballero, A. Geometric transformation-based data augmentation on defect classification of segmented images of semiconductor materials using a ResNet50 convolutional neural network. Expert Syst. Appl. 2022, 206, 117731. [Google Scholar] [CrossRef]
- Krahe, C.; Marinov, M.; Schmutz, T.; Hermann, Y.; Bonny, M.; May, M.; Lanza, G. AI based geometric similarity search supporting component reuse in engineering design. Procedia CIRP 2022, 109, 275–280. [Google Scholar] [CrossRef]
- Onler, R.; Koca, A.S.; Kirim, B.; Soylemez, E. Multi-objective optimization of binder jet additive manufacturing of Co-Cr-Mo using machine learning. Int. J. Adv. Manuf. Technol. 2022, 119, 1091–1108. [Google Scholar] [CrossRef]
- Jadidi, A.; Mi, Y.; Sikström, F.; Nilsen, M.; Ancona, A. Beam Offset Detection in Laser Stake Welding of Tee Joints Using Machine Learning and Spectrometer Measurements. Sensors 2022, 22, 3881. [Google Scholar] [CrossRef]
- Sanchez, S.; Rengasamy, D.; Hyde, C.J.; Figueredo, G.P.; Rothwell, B. Machine learning to determine the main factors affecting creep rates in laser powder bed fusion. J. Intell. Manuf. 2021, 32, 2353–2373. [Google Scholar] [CrossRef]
- Verma, S.; Misra, J.P.; Popli, D. Modeling of friction stir welding of aviation grade aluminium alloy using machine learning approaches. Int. J. Model. Simul. 2022, 42, 1–8. [Google Scholar] [CrossRef]
- Gerling, A.; Ziekow, H.; Hess, A.; Schreier, U.; Seiffer, C.; Abdeslam, D.O. Comparison of algorithms for error prediction in manufacturing with automl and a cost-based metric. J. Intell. Manuf. 2022, 33, 555–573. [Google Scholar] [CrossRef]
- Akbari, P.; Ogoke, F.; Kao, N.Y.; Meidani, K.; Yeh, C.Y.; Lee, W.; Farimani, A.B. MeltpoolNet: Melt pool characteristic prediction in Metal Additive Manufacturing using machine learning. Addit. Manuf. 2022, 55, 102817. [Google Scholar] [CrossRef]
- Dittrich, M.A.; Uhlich, F.; Denkena, B. Self-optimizing tool path generation for 5-axis machining processes. CIRP J. Manuf. Sci. Technol. 2019, 24, 49–54. [Google Scholar] [CrossRef]
- Xi, Z. Model predictive control of melt pool size for the laser powder bed fusion process under process uncertainty. ASCE-ASME J. Risk Uncertain. Eng. Syst. Part B Mech. Eng. 2022, 8, 011103. [Google Scholar] [CrossRef]
- Li, X.; Liu, X.; Yue, C.; Liu, S.; Zhang, B.; Li, R.; Liang, S.Y.; Wang, L. A data-driven approach for tool wear recognition and quantitative prediction based on radar map feature fusion. Measurement 2021, 185, 110072. [Google Scholar] [CrossRef]
- Xia, B.; Wang, K.; Xu, A.; Zeng, P.; Yang, N.; Li, B. Intelligent Fault Diagnosis for Bearings of Industrial Robot Joints Under Varying Working Conditions Based on Deep Adversarial Domain Adaptation. IEEE Trans. Instrum. Meas. 2022, 71, 1–13. [Google Scholar] [CrossRef]
- May, M.C.; Neidhöfer, J.; Körner, T.; Schäfer, L.; Lanza, G. Applying Natural Language Processing in Manufacturing. Procedia CIRP 2022, 115, 184–189. [Google Scholar] [CrossRef]
- Xu, X.; Li, X.; Ming, W.; Chen, M. A novel multi-scale CNN and attention mechanism method with multi-sensor signal for remaining useful life prediction. Comput. Ind. Eng. 2022, 169, 108204. [Google Scholar] [CrossRef]
- Shah, M.; Vakharia, V.; Chaudhari, R.; Vora, J.; Pimenov, D.Y.; Giasin, K. Tool wear prediction in face milling of stainless steel using singular generative adversarial network and LSTM deep learning models. Int. J. Adv. Manuf. Technol. 2022, 121, 723–736. [Google Scholar] [CrossRef]
- Verl, A.; Steinle, L. Adaptive compensation of the transmission errors in rack-and-pinion drives. CIRP Ann. 2022, 71, 345–348. [Google Scholar] [CrossRef]
- Frigerio, N.; Cornaggia, C.F.; Matta, A. An adaptive policy for on-line Energy-Efficient Control of machine tools under throughput constraint. J. Clean. Prod. 2021, 287, 125367. [Google Scholar] [CrossRef]
- Bozcan, I.; Korndorfer, C.; Madsen, M.W.; Kayacan, E. Score-Based Anomaly Detection for Smart Manufacturing Systems. IEEE/ASME Trans. Mechatron. 2022, 27, 5233–5242. [Google Scholar] [CrossRef]
- Bokrantz, J.; Skoogh, A.; Nawcki, M.; Ito, A.; Hagstr, M.; Gandhi, K.; Bergsj, D. Improved root cause analysis supporting resilient production systems. J. Manuf. Syst. 2022, 64, 468–478. [Google Scholar] [CrossRef]
- Long, T.; Li, Y.; Chen, J. Productivity prediction in aircraft final assembly lines: Comparisons and insights in different productivity ranges. J. Manuf. Syst. 2022, 62, 377–389. [Google Scholar] [CrossRef]
- Overbeck, L.; Hugues, A.; May, M.C.; Kuhnle, A.; Lanza, G. Reinforcement Learning Based Production Control of Semi-automated Manufacturing Systems. Procedia CIRP 2021, 103, 170–175. [Google Scholar] [CrossRef]
- May, M.C.; Behnen, L.; Holzer, A.; Kuhnle, A.; Lanza, G. Multi-variate time-series for time constraint adherence prediction in complex job shops. Procedia CIRP 2021, 103, 55–60. [Google Scholar] [CrossRef]
- Wurster, M.; Michel, M.; May, M.C.; Kuhnle, A.; Stricker, N.; Lanza, G. Modelling and condition-based control of a flexible and hybrid disassembly system with manual and autonomous workstations using reinforcement learning. J. Intell. Manuf. 2022, 33, 575–591. [Google Scholar] [CrossRef]
- Liberati, A.; Altman, D.G.; Tetzlaff, J.; Mulrow, C.; Gøtzsche, P.C.; Ioannidis, J.P.; Clarke, M.; Devereaux, P.J.; Kleijnen, J.; Moher, D. The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: Explanation and elaboration. J. Clin. Epidemiol. 2009, 62, e1–e34. [Google Scholar] [CrossRef]
- Sampath, V.; Maurtua, I.; Aguilar Martín, J.J.; Gutierrez, A. A survey on generative adversarial networks for imbalance problems in computer vision tasks. J. Big Data 2021, 8, 27. [Google Scholar] [CrossRef]
- Polyzotis, N.; Roy, S.; Whang, S.E.; Zinkevich, M. Data lifecycle challenges in production machine learning: A survey. ACM Sigmod Rec. 2018, 47, 17–28. [Google Scholar] [CrossRef]
- Wang, Z.; Oates, T. Imaging time-series to improve classification and imputation. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Lee, G.; Flowers, M.; Dyer, M. Learning distributed representations of conceptual knowledge. In Proceedings of the International 1989 Joint Conference on Neural Networks, Washington, DC, USA, 18–22 June 1989. [Google Scholar] [CrossRef]
- Zhu, Y.; Brettin, T.; Xia, F.; Partin, A.; Shukla, M.; Yoo, H.; Evrard, Y.A.; Doroshow, J.H.; Stevens, R.L. Converting tabular data into images for deep learning with convolutional neural networks. Sci. Rep. 2021, 11, 11325. [Google Scholar] [CrossRef]
- Sharma, A.; Vans, E.; Shigemizu, D.; Boroevich, K.A.; Tsunoda, T. DeepInsight: A methodology to transform a non-image data to an image for convolution neural network architecture. Sci. Rep. 2019, 9, 11399. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Nanni, L.; Ghidoni, S.; Brahnam, S. Handcrafted vs. non-handcrafted features for computer vision classification. Pattern Recognit. 2017, 71, 158–172. [Google Scholar] [CrossRef]
- Alkinani, M.H.; Khan, W.Z.; Arshad, Q.; Raza, M. HSDDD: A Hybrid Scheme for the Detection of Distracted Driving through Fusion of Deep Learning and Handcrafted Features. Sensors 2022, 22, 1864. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, L.; Cao, Z.; Guo, J. Distilling the Knowledge from Handcrafted Features for Human Activity Recognition. IEEE Trans. Ind. Inform. 2018, 14, 4334–4342. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Pearson, K. LIII. On lines and planes of closest fit to systems of points in space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Comon, P. Independent component analysis, a new concept? Signal Process. 1994, 36, 287–314. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Interspeech; Makuhari: Chiba-city, Japan, 2010; Volume 2, pp. 1045–1048. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Shensa, M.J. The discrete wavelet transform: Wedding the a trous and Mallat algorithms. IEEE Trans. Signal Process. 1992, 40, 2464–2482. [Google Scholar] [CrossRef]
- Gröchenig, K. The short-time Fourier transform. In Foundations of Time-Frequency Analysis; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2001; pp. 37–58. [Google Scholar]
- Harris, Z.S. Distributional structure. Word 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Liu, D.; Kong, H.; Luo, X.; Liu, W.; Subramaniam, R. Bringing AI to edge: From deep learning’s perspective. Neurocomputing 2021, 485, 297–320. [Google Scholar] [CrossRef]
- Gray, R.M.; Neuhoff, D.L. Quantization. IEEE Trans. Inf. Theory 1998, 44, 2325–2383. [Google Scholar] [CrossRef]
- Sampath, V.; Maurtua, I.; Aguilar Martín, J.J.; Iriondo, A.; Lluvia, I.; Rivera, A. Vision Transformer based knowledge distillation for fasteners defect detection. In Proceedings of the 2022 International Conference on Electrical, Computer and Energy Technologies (ICECET), Prague, Czech Republic, 20–22 July 2022; pp. 1–6. [Google Scholar]
- Shelden, R. Decision Tree. Chem. Eng. Prog. 1970, 66, 8. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the Thirteenth International Conference on International Conference on Machine Learning (ICML’96), Bari, Italy, 3–6 July 1996; Volume 96, pp. 148–156. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef]
- Choi, S.; Battulga, L.; Nasridinov, A.; Yoo, K.H. A decision tree approach for identifying defective products in the manufacturing process. Int. J. Contents 2017, 13, 57–65. [Google Scholar]
- Sugumaran, V.; Muralidharan, V.; Ramachandran, K. Feature selection using decision tree and classification through proximal support vector machine for fault diagnostics of roller bearing. Mech. Syst. Signal Process. 2007, 21, 930–942. [Google Scholar] [CrossRef]
- Hung, Y.H. Improved ensemble-learning algorithm for predictive maintenance in the manufacturing process. Appl. Sci. 2021, 11, 6832. [Google Scholar] [CrossRef]
- Močkus, J. On bayesian methods for seeking the extremum. In Optimization Techniques IFIP Technical Conference Novosibirsk, Novosibirsk, Russia, 1–7 July 1974; Marchuk, G.I., Ed.; Springer: Berlin/Heidelberg, Germany, 1975; pp. 400–404. [Google Scholar]
- Baum, L.E.; Petrie, T. Statistical inference for probabilistic functions of finite state Markov chains. Ann. Math. Stat. 1966, 37, 1554–1563. [Google Scholar] [CrossRef]
- Papananias, M.; McLeay, T.E.; Mahfouf, M.; Kadirkamanathan, V. A Bayesian framework to estimate part quality and associated uncertainties in multistage manufacturing. Comput. Ind. 2019, 105, 35–47. [Google Scholar] [CrossRef]
- Patange, A.D.; Jegadeeshwaran, R. Application of bayesian family classifiers for cutting tool inserts health monitoring on CNC milling. Int. J. Progn. Health Manag. 2020, 11. [Google Scholar] [CrossRef]
- Pandita, P.; Ghosh, S.; Gupta, V.K.; Meshkov, A.; Wang, L. Application of Deep Transfer Learning and Uncertainty Quantification for Process Identification in Powder Bed Fusion. ASME J. Risk Uncertain. Part B Mech. Eng. 2022, 8, 011106. [Google Scholar] [CrossRef]
- Farahani, A.; Tohidi, H.; Shoja, A. An integrated optimization of quality control chart parameters and preventive maintenance using Markov chain. Adv. Prod. Eng. Manag. 2019, 14, 5–14. [Google Scholar] [CrossRef]
- El Haoud, N.; Bachiri, Z. Stochastic artificial intelligence benefits and supply chain management inventory prediction. In Proceedings of the 2019 International Colloquium on Logistics and Supply Chain Management (LOGISTIQUA), Paris, France, 12–14 June 2019; pp. 1–5. [Google Scholar]
- Feng, M.; Li, Y. Predictive Maintenance Decision Making Based on Reinforcement Learning in Multistage Production Systems. IEEE Access 2022, 10, 18910–18921. [Google Scholar] [CrossRef]
- Sobaszek, Ł.; Gola, A.; Kozłowski, E. Predictive scheduling with Markov chains and ARIMA models. Appl. Sci. 2020, 10, 6121. [Google Scholar] [CrossRef]
- Hofmann, T.; Schölkopf, B.; Smola, A.J. Kernel methods in machine learning. Ann. Stat. 2008, 36, 1171–1220. [Google Scholar] [CrossRef]
- Gobert, C.; Reutzel, E.W.; Petrich, J.; Nassar, A.R.; Phoha, S. Application of supervised machine learning for defect detection during metallic powder bed fusion additive manufacturing using high resolution imaging. Addit. Manuf. 2018, 21, 517–528. [Google Scholar] [CrossRef]
- McGregor, D.J.; Bimrose, M.V.; Shao, C.; Tawfick, S.; King, W.P. Using machine learning to predict dimensions and qualify diverse part designs across multiple additive machines and materials. Addit. Manuf. 2022, 55, 102848. [Google Scholar] [CrossRef]
- Kubik, C.; Knauer, S.M.; Groche, P. Smart sheet metal forming: Importance of data acquisition, preprocessing and transformation on the performance of a multiclass support vector machine for predicting wear states during blanking. J. Intell. Manuf. 2022, 33, 259–282. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Mika, S.; Ratsch, G.; Weston, J.; Scholkopf, B.; Mullers, K. Fisher discriminant analysis with kernels. In Proceedings of the Neural Networks for Signal Processing IX: Proceedings of the 1999 IEEE Signal Processing Society Workshop (Cat. No.98TH8468), Madison, WI, USA, 25 August 1999; pp. 41–48. [Google Scholar] [CrossRef]
- Fukushima, K.; Miyake, S. Neocognitron: A self-organizing neural network model for a mechanism of visual pattern recognition. In Competition and Cooperation in Neural Nets; Springer: Berlin/Heidelberg, Germany, 1982; pp. 267–285. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hinton, G.E. Deep belief networks. Scholarpedia 2009, 4, 5947. [Google Scholar] [CrossRef]
- Badmos, O.; Kopp, A.; Bernthaler, T.; Schneider, G. Image-based defect detection in lithium-ion battery electrode using convolutional neural networks. J. Intell. Manuf. 2020, 31, 885–897. [Google Scholar] [CrossRef]
- Ho, S.; Zhang, W.; Young, W.; Buchholz, M.; Al Jufout, S.; Dajani, K.; Bian, L.; Mozumdar, M. DLAM: Deep Learning Based Real-Time Porosity Prediction for Additive Manufacturing Using Thermal Images of the Melt Pool. IEEE Access 2021, 9, 115100–115114. [Google Scholar] [CrossRef]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A new convolutional neural network-based data-driven fault diagnosis method. IEEE Trans. Ind. Electron. 2017, 65, 5990–5998. [Google Scholar] [CrossRef]
- Al-Dulaimi, A.; Zabihi, S.; Asif, A.; Mohammadi, A. A multimodal and hybrid deep neural network model for remaining useful life estimation. Comput. Ind. 2019, 108, 186–196. [Google Scholar] [CrossRef]
- Huang, J.; Segura, L.J.; Wang, T.; Zhao, G.; Sun, H.; Zhou, C. Unsupervised learning for the droplet evolution prediction and process dynamics understanding in inkjet printing. Addit. Manuf. 2020, 35, 101197. [Google Scholar] [CrossRef]
- Huang, J.; Chang, Q.; Arinez, J. Product completion time prediction using a hybrid approach combining deep learning and system model. J. Manuf. Syst. 2020, 57, 311–322. [Google Scholar] [CrossRef]
- Cohen, J.; Jiang, B.; Ni, J. Machine Learning for Diagnosis of Event Synchronization Faults in Discrete Manufacturing Systems. J. Manuf. Sci. Eng. 2022, 144, 071006. [Google Scholar] [CrossRef]
- Mujeeb, A.; Dai, W.; Erdt, M.; Sourin, A. One class based feature learning approach for defect detection using deep autoencoders. Adv. Eng. Inform. 2019, 42, 100933. [Google Scholar] [CrossRef]
- Kasim, N.; Nuawi, M.; Ghani, J.; Rizal, M.; Ngatiman, N.; Haron, C. Enhancing Clustering Algorithm with Initial Centroids in Tool Wear Region Recognition. Int. J. Precis. Eng. Manuf. 2021, 22, 843–863. [Google Scholar] [CrossRef]
- Djatna, T.; Alitu, I.M. An application of association rule mining in total productive maintenance strategy: An analysis and modelling in wooden door manufacturing industry. Procedia Manuf. 2015, 4, 336–343. [Google Scholar] [CrossRef]
- Chiang, L.H.; Colegrove, L.F. Industrial implementation of on-line multivariate quality control. Chemom. Intell. Lab. Syst. 2007, 88, 143–153. [Google Scholar] [CrossRef]
- You, D.; Gao, X.; Katayama, S. WPD-PCA-based laser welding process monitoring and defects diagnosis by using FNN and SVM. IEEE Trans. Ind. Electron. 2014, 62, 628–636. [Google Scholar] [CrossRef]
- Moshat, S.; Datta, S.; Bandyopadhyay, A.; Pal, P. Optimization of CNC end milling process parameters using PCA-based Taguchi method. Int. J. Eng. Sci. Technol. 2010, 2, 95–102. [Google Scholar] [CrossRef]
- Mei, S.; Wang, Y.; Wen, G. Automatic fabric defect detection with a multi-scale convolutional denoising autoencoder network model. Sensors 2018, 18, 1064. [Google Scholar] [CrossRef] [PubMed]
- Maggipinto, M.; Beghi, A.; Susto, G.A. A Deep Convolutional Autoencoder-Based Approach for Anomaly Detection With Industrial, Non-Images, 2-Dimensional Data: A Semiconductor Manufacturing Case Study. IEEE Trans. Autom. Sci. Eng. 2022. [Google Scholar] [CrossRef]
- Yang, Z.; Gjorgjevikj, D.; Long, J.; Zi, Y.; Zhang, S.; Li, C. Sparse autoencoder-based multi-head deep neural networks for machinery fault diagnostics with detection of novelties. Chin. J. Mech. Eng. 2021, 34, 54. [Google Scholar] [CrossRef]
- Cheng, R.C.; Chen, K.S. Ball bearing multiple failure diagnosis using feature-selected autoencoder model. Int. J. Adv. Manuf. Technol. 2022, 120, 4803–4819. [Google Scholar] [CrossRef]
- Ramamurthy, M.; Robinson, Y.H.; Vimal, S.; Suresh, A. Auto encoder based dimensionality reduction and classification using convolutional neural networks for hyperspectral images. Microprocess. Microsyst. 2020, 79, 103280. [Google Scholar] [CrossRef]
- Angelopoulos, A.; Michailidis, E.T.; Nomikos, N.; Trakadas, P.; Hatziefremidis, A.; Voliotis, S.; Zahariadis, T. Tackling faults in the industry 4.0 era—A survey of machine-learning solutions and key aspects. Sensors 2019, 20, 109. [Google Scholar] [CrossRef]
- de Lima, M.J.; Crovato, C.D.P.; Mejia, R.I.G.; da Rosa Righi, R.; de Oliveira Ramos, G.; da Costa, C.A.; Pesenti, G. HealthMon: An approach for monitoring machines degradation using time-series decomposition, clustering, and metaheuristics. Comput. Ind. Eng. 2021, 162, 107709. [Google Scholar] [CrossRef]
- Song, W.; Wen, L.; Gao, L.; Li, X. Unsupervised fault diagnosis method based on iterative multi-manifold spectral clustering. IET Collab. Intell. Manuf. 2019, 1, 48–55. [Google Scholar] [CrossRef]
- Subramaniyan, M.; Skoogh, A.; Muhammad, A.S.; Bokrantz, J.; Johansson, B.; Roser, C. A generic hierarchical clustering approach for detecting bottlenecks in manufacturing. J. Manuf. Syst. 2020, 55, 143–158. [Google Scholar] [CrossRef]
- Srinivasan, M.; Moon, Y.B. A comprehensive clustering algorithm for strategic analysis of supply chain networks. Comput. Ind. Eng. 1999, 36, 615–633. [Google Scholar] [CrossRef]
- Das, J.N.; Tiwari, M.K.; Sinha, A.K.; Khanzode, V. Integrated warehouse assignment and carton configuration optimization using deep clustering-based evolutionary algorithms. Expert Syst. Appl. 2023, 212, 118680. [Google Scholar] [CrossRef]
- Stojanovic, L.; Dinic, M.; Stojanovic, N.; Stojadinovic, A. Big-data-driven anomaly detection in industry (4.0): An approach and a case study. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 1647–1652. [Google Scholar]
- Saldivar, A.A.F.; Goh, C.; Li, Y.; Chen, Y.; Yu, H. Identifying smart design attributes for Industry 4.0 customization using a clustering Genetic Algorithm. In Proceedings of the 2016 22nd International Conference on Automation and Computing (ICAC), Colchester, UK, 7–8 September 2016; pp. 408–414. [Google Scholar]
- Chen, W.C.; Tseng, S.S.; Wang, C.Y. A novel manufacturing defect detection method using association rule mining techniques. Expert Syst. Appl. 2005, 29, 807–815. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Iwana, B.K.; Uchida, S. An empirical survey of data augmentation for time series classification with neural networks. PLoS ONE 2021, 16, e0254841. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding data augmentation for classification: When to warp? In Proceedings of the 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 30 November–2 December 2016; pp. 1–6. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C.A. Mixmatch: A holistic approach to semi-supervised learning. Adv. Neural Inf. Process. Syst. 2019, 32, 5049–5059. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.L. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Yang, X.; Song, Z.; King, I.; Xu, Z. A Survey on Deep Semi-supervised Learning. arXiv 2021, arXiv:2103.00550. [Google Scholar] [CrossRef]
- Sajjadi, M.; Javanmardi, M.; Tasdizen, T. Regularization with stochastic transformations and perturbations for deep semi-supervised learning. Adv. Neural Inf. Process. Syst. 2016, 29, 1171–1179. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Adv. Neural Inf. Process. Syst. 2017, 30, 1195–1204. [Google Scholar]
- Li, X.; Jia, X.; Yang, Q.; Lee, J. Quality analysis in metal additive manufacturing with deep learning. J. Intell. Manuf. 2020, 31, 2003–2017. [Google Scholar] [CrossRef]
- Zhao, B.; Zhang, X.; Zhan, Z.; Wu, Q.; Zhang, H. A Novel Semi-Supervised Graph-Guided Approach for Intelligent Health State Diagnosis of a 3-PRR Planar Parallel Manipulator. IEEE/ASME Trans. Mechatron. 2022, 27, 4786–4797. [Google Scholar] [CrossRef]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1263–1272. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Serradilla, O.; Zugasti, E.; Ramirez de Okariz, J.; Rodriguez, J.; Zurutuza, U. Adaptable and explainable predictive maintenance: Semi-supervised deep learning for anomaly detection and diagnosis in press machine data. Appl. Sci. 2021, 11, 7376. [Google Scholar] [CrossRef]
- Song, J.; Lee, Y.C.; Lee, J. Deep generative model with time series-image encoding for manufacturing fault detection in die casting process. J. Intell. Manuf. 2022, 1–14. [Google Scholar] [CrossRef]
- Springenberg, J.T. Unsupervised and semi-supervised learning with categorical generative adversarial networks. arXiv 2015, arXiv:1511.06390. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. Adv. Neural Inf. Process. Syst. 2016, 29, 2234–2242. [Google Scholar]
- Kingma, D.P.; Mohamed, S.; Jimenez Rezende, D.; Welling, M. Semi-supervised learning with deep generative models. Adv. Neural Inf. Process. Syst. 2014, 27, 3581–3589. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- May, M.C.; Overbeck, L.; Wurster, M.; Kuhnle, A.; Lanza, G. Foresighted digital twin for situational agent selection in production control. Procedia CIRP 2021, 99, 27–32. [Google Scholar] [CrossRef]
- May, M.C.; Kiefer, L.; Kuhnle, A.; Stricker, N.; Lanza, G. Decentralized multi-agent production control through economic model bidding for matrix production systems. Procedia Cirp 2021, 96, 3–8. [Google Scholar] [CrossRef]
- Yao, M. Breakthrough Research In Reinforcement Learning From 2019. 2019. Available online: https://www.topbots.com/top-ai-reinforcement-learning-research-papers-2019 (accessed on 1 September 2022).
- Gao, R.X.; Wang, L.; Helu, M.; Teti, R. Big data analytics for smart factories of the future. CIRP Ann. 2020, 69, 668–692. [Google Scholar] [CrossRef]
- Kozjek, D.; Vrabič, R.; Kralj, D.; Butala, P. Interpretative identification of the faulty conditions in a cyclic manufacturing process. J. Manuf. Syst. 2017, 43, 214–224. [Google Scholar] [CrossRef] [Green Version]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time series data augmentation for deep learning: A survey. arXiv 2020, arXiv:2002.12478. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Bao, J.; Chen, D.; Wen, F.; Li, H.; Hua, G. CVAE-GAN: Fine-grained image generation through asymmetric training. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2745–2754. [Google Scholar]
- Yoon, J.; Jarrett, D.; Van der Schaar, M. Time-series generative adversarial networks. Adv. Neural Inf. Process. Syst. 2019, 32, 5508–5518. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Cheng, Y.; Wang, D.; Zhou, P.; Zhang, T. Model compression and acceleration for deep neural networks: The principles, progress, and challenges. IEEE Signal Process. Mag. 2018, 35, 126–136. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Schlimmer, J.C.; Granger, R.H. Incremental learning from noisy data. Mach. Learn. 1986, 1, 317–354. [Google Scholar] [CrossRef]
- Gama, J.; Žliobaitė, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A survey on concept drift adaptation. ACM Comput. Surv. 2014, 46, 44. [Google Scholar] [CrossRef]
- Baier, L.; Jöhren, F.; Seebacher, S. Challenges in the Deployment and Operation of Machine Learning in Practice. In Proceedings of the ECIS 2019 27th European Conference on Information Systems, Stockholm, Sweden, 8–14 June 2019. [Google Scholar]
- Canbek, G. Gaining insights in datasets in the shade of “garbage in, garbage out” rationale: Feature space distribution fitting. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2022, 12, e1456. [Google Scholar] [CrossRef]
- Moges, T.; Yang, Z.; Jones, K.; Feng, S.; Witherell, P.; Lu, Y. Hybrid modeling approach for melt-pool prediction in laser powder bed fusion additive manufacturing. J. Comput. Inf. Sci. Eng. 2021, 21, 050902. [Google Scholar] [CrossRef]
- Colledani, M. Statistical Process Control. In CIRP Encyclopedia of Production Engineering; Laperrière, L., Reinhart, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1150–1157. [Google Scholar] [CrossRef]
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Cao, X.; Khosravi, A.; Acharya, U.R.; et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Inf. Fusion 2021, 76, 243–297. [Google Scholar] [CrossRef]
- Yong, B.X.; Brintrup, A. Multi Agent System for Machine Learning Under Uncertainty in Cyber Physical Manufacturing System. In Service Oriented, Holonic and Multi-Agent Manufacturing Systems for Industry of the Future; Borangiu, T., Trentesaux, D., Leitão, P., Giret Boggino, A., Botti, V., Eds.; Studies in Computational Intelligence; Springer International Publishing: Cham, Switzerland, 2020; Volume 853, pp. 244–257. [Google Scholar] [CrossRef]
- Tavazza, F.; DeCost, B.; Choudhary, K. Uncertainty Prediction for Machine Learning Models of Material Properties. ACS Omega 2021, 6, 32431–32440. [Google Scholar] [CrossRef]
- Arkov, V. Uncertainty Estimation in Machine Learning. arXiv 2022. [Google Scholar] [CrossRef]
- Zhang, B. Data-Driven Uncertainty Analysis in Neural Networks with Applications to Manufacturing Process Monitoring. Ph.D. Thesis, Purdue University Graduate School, West Lafayette, IN, USA, 2021. [Google Scholar] [CrossRef]
- Zhang, B.; Shin, Y.C. A probabilistic neural network for uncertainty prediction with applications to manufacturing process monitoring. Appl. Soft Comput. 2022, 124, 108995. [Google Scholar] [CrossRef]
- Lee, S.; Kim, S.B. Time-adaptive support vector data description for nonstationary process monitoring. Eng. Appl. Artif. Intell. 2018, 68, 18–31. [Google Scholar] [CrossRef]
- Gaikwad, A.; Yavari, R.; Montazeri, M.; Cole, K.; Bian, L.; Rao, P. Toward the digital twin of additive manufacturing: Integrating thermal simulations, sensing, and analytics to detect process faults. IISE Trans. 2020, 52, 1204–1217. [Google Scholar] [CrossRef]
- Zhang, C.J.; Zhang, Y.C.; Han, Y. Industrial cyber-physical system driven intelligent prediction model for converter end carbon content in steelmaking plants. J. Ind. Inf. Integr. 2022, 28, 100356. [Google Scholar] [CrossRef]
- Ning, F.; Shi, Y.; Cai, M.; Xu, W.; Zhang, X. Manufacturing cost estimation based on the machining process and deep-learning method. J. Manuf. Syst. 2020, 56, 11–22. [Google Scholar] [CrossRef]
- Westphal, E.; Seitz, H. Machine learning for the intelligent analysis of 3D printing conditions using environmental sensor data to support quality assurance. Addit. Manuf. 2022, 50, 102535. [Google Scholar] [CrossRef]
- Qin, J.; Wang, Y.; Ding, J.; Williams, S. Optimal droplet transfer mode maintenance for wire+ arc additive manufacturing (WAAM) based on deep learning. J. Intell. Manuf. 2022, 33, 2179–2191. [Google Scholar] [CrossRef]
- Lapointe, S.; Guss, G.; Reese, Z.; Strantza, M.; Matthews, M.; Druzgalski, C. Photodiode-based machine learning for optimization of laser powder bed fusion parameters in complex geometries. Addit. Manuf. 2022, 53, 102687. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, C.; Hu, T. A robotic grasp detection method based on auto-annotated dataset in disordered manufacturing scenarios. Robot. Comput. Integr. Manuf. 2022, 76, 102329. [Google Scholar] [CrossRef]
- Singh, S.A.; Desai, K. Automated surface defect detection framework using machine vision and convolutional neural networks. J. Intell. Manuf. 2022, 1–17. [Google Scholar] [CrossRef]
- Duan, J.; Hu, C.; Zhan, X.; Zhou, H.; Liao, G.; Shi, T. MS-SSPCANet: A powerful deep learning framework for tool wear prediction. Robot. Comput. Integr. Manuf. 2022, 78, 102391. [Google Scholar] [CrossRef]
- Gao, K.; Chen, H.; Zhang, X.; Ren, X.; Chen, J.; Chen, X. A novel material removal prediction method based on acoustic sensing and ensemble XGBoost learning algorithm for robotic belt grinding of Inconel 718. Int. J. Adv. Manuf. Technol. 2019, 105, 217–232. [Google Scholar] [CrossRef]
- Gawade, V.; Singh, V.; Guo, W. Leveraging simulated and empirical data-driven insight to supervised-learning for porosity prediction in laser metal deposition. J. Manuf. Syst. 2022, 62, 875–885. [Google Scholar] [CrossRef]
- Aminzadeh, M.; Kurfess, T.R. Online quality inspection using Bayesian classification in powder-bed additive manufacturing from high-resolution visual camera images. J. Intell. Manuf. 2019, 30, 2505–2523. [Google Scholar] [CrossRef]
- Priore, P.; Ponte, B.; Puente, J.; Gómez, A. Learning-based scheduling of flexible manufacturing systems using ensemble methods. Comput. Ind. Eng. 2018, 126, 282–291. [Google Scholar] [CrossRef]
- Guo, S.; Chen, M.; Abolhassani, A.; Kalamdani, R.; Guo, W.G. Identifying manufacturing operational conditions by physics-based feature extraction and ensemble clustering. J. Manuf. Syst. 2021, 60, 162–175. [Google Scholar] [CrossRef]
- Kim, J.; Ko, J.; Choi, H.; Kim, H. Printed circuit board defect detection using deep learning via a skip-connected convolutional autoencoder. Sensors 2021, 21, 4968. [Google Scholar] [CrossRef]
- Jakubowski, J.; Stanisz, P.; Bobek, S.; Nalepa, G.J. Anomaly Detection in Asset Degradation Process Using Variational Autoencoder and Explanations. Sensors 2021, 22, 291. [Google Scholar] [CrossRef]
- Sarita, K.; Devarapalli, R.; Kumar, S.; Malik, H.; Garcia Marquez, F.P.; Rai, P. Principal component analysis technique for early fault detection. J. Intell. Fuzzy Syst. 2022, 42, 861–872. [Google Scholar] [CrossRef]
- Zheng, X.; Wang, H.; Chen, J.; Kong, Y.; Zheng, S. A generic semi-supervised deep learning-based approach for automated surface inspection. IEEE Access 2020, 8, 114088–114099. [Google Scholar] [CrossRef]
- Zhang, W.; Lang, J. Semi-supervised training for positioning of welding seams. Sensors 2021, 21, 7309. [Google Scholar] [CrossRef]
- Chen, C.; Liu, Y.; Kumar, M.; Qin, J.; Ren, Y. Energy consumption modelling using deep learning embedded semi-supervised learning. Comput. Ind. Eng. 2019, 135, 757–765. [Google Scholar] [CrossRef]
- Jun, J.h.; Chang, T.W.; Jun, S. Quality prediction and yield improvement in process manufacturing based on data analytics. Processes 2020, 8, 1068. [Google Scholar] [CrossRef]
- Shim, J.; Cho, S.; Kum, E.; Jeong, S. Adaptive fault detection framework for recipe transition in semiconductor manufacturing. Comput. Ind. Eng. 2021, 161, 107632. [Google Scholar] [CrossRef]
- Qiu, C.; Li, K.; Li, B.; Mao, X.; He, S.; Hao, C.; Yin, L. Semi-supervised graph convolutional network to predict position-and speed-dependent tool tip dynamics with limited labeled data. Mech. Syst. Signal Process. 2022, 164, 108225. [Google Scholar] [CrossRef]
- Guo, Y.; Lu, W.F.; Fuh, J.Y.H. Semi-supervised deep learning based framework for assessing manufacturability of cellular structures in direct metal laser sintering process. J. Intell. Manuf. 2021, 32, 347–359. [Google Scholar] [CrossRef]
- Okaro, I.A.; Jayasinghe, S.; Sutcliffe, C.; Black, K.; Paoletti, P.; Green, P.L. Automatic fault detection for laser powder-bed fusion using semi-supervised machine learning. Addit. Manuf. 2019, 27, 42–53. [Google Scholar] [CrossRef]
- Lee, H.; Kim, H. Semi-supervised multi-label learning for classification of wafer bin maps with mixed-type defect patterns. IEEE Trans. Semicond. Manuf. 2020, 33, 653–662. [Google Scholar] [CrossRef]
- Liu, J.; Song, K.; Feng, M.; Yan, Y.; Tu, Z.; Zhu, L. Semi-supervised anomaly detection with dual prototypes autoencoder for industrial surface inspection. Opt. Lasers Eng. 2021, 136, 106324. [Google Scholar] [CrossRef]
- Verstraete, D.; Droguett, E.; Modarres, M. A deep adversarial approach based on multi-sensor fusion for semi-supervised remaining useful life prognostics. Sensors 2019, 20, 176. [Google Scholar] [CrossRef]
- Souza, M.L.H.; da Costa, C.A.; de Oliveira Ramos, G.; da Rosa Righi, R. A feature identification method to explain anomalies in condition monitoring. Comput. Ind. 2021, 133, 103528. [Google Scholar] [CrossRef]
- Lee, Y.H.; Lee, S. Deep reinforcement learning based scheduling within production plan in semiconductor fabrication. Expert Syst. Appl. 2022, 191, 116222. [Google Scholar] [CrossRef]
- Marchesano, M.G.; Guizzi, G.; Santillo, L.C.; Vespoli, S. A deep reinforcement learning approach for the throughput control of a flow-shop production system. IFAC-PapersOnLine 2021, 54, 61–66. [Google Scholar] [CrossRef]
- Yang, H.; Li, W.; Wang, B. Joint optimization of preventive maintenance and production scheduling for multi-state production systems based on reinforcement learning. Reliab. Eng. Syst. Saf. 2021, 214, 107713. [Google Scholar] [CrossRef]
- Schneckenreither, M.; Haeussler, S.; Peiró, J. Average reward adjusted deep reinforcement learning for order release planning in manufacturing. Knowl.-Based Syst. 2022, 247, 108765. [Google Scholar] [CrossRef]
- Tsai, Y.T.; Lee, C.H.; Liu, T.Y.; Chang, T.J.; Wang, C.S.; Pawar, S.J.; Huang, P.H.; Huang, J.H. Utilization of a reinforcement learning algorithm for the accurate alignment of a robotic arm in a complete soft fabric shoe tongues automation process. J. Manuf. Syst. 2020, 56, 501–513. [Google Scholar] [CrossRef]
- Klar, M.; Glatt, M.; Aurich, J.C. An implementation of a reinforcement learning based algorithm for factory layout planning. Manuf. Lett. 2021, 30, 1–4. [Google Scholar] [CrossRef]
- Huang, J.; Chang, Q.; Arinez, J. Deep reinforcement learning based preventive maintenance policy for serial production lines. Expert Syst. Appl. 2020, 160, 113701. [Google Scholar] [CrossRef]
- Zhang, H.; Peng, Q.; Zhang, J.; Gu, P. Planning for automatic product assembly using reinforcement learning. Comput. Ind. 2021, 130, 103471. [Google Scholar] [CrossRef]
- Kuhnle, A.; May, M.C.; Schaefer, L.; Lanza, G. Explainable reinforcement learning in production control of job shop manufacturing system. Int. J. Prod. Res. 2021, 60, 5812–5834. [Google Scholar] [CrossRef]
- Valet, A.; Altenmüller, T.; Waschneck, B.; May, M.C.; Kuhnle, A.; Lanza, G. Opportunistic maintenance scheduling with deep reinforcement learning. J. Manuf. Syst. 2022, 64, 518–534. [Google Scholar] [CrossRef]
- Huang, J.; Su, J.; Chang, Q. Graph neural network and multi-agent reinforcement learning for machine-process-system integrated control to optimize production yield. J. Manuf. Syst. 2022, 64, 81–93. [Google Scholar] [CrossRef]
- Zimmerling, C.; Poppe, C.; Stein, O.; Kärger, L. Optimisation of manufacturing process parameters for variable component geometries using reinforcement learning. Mater. Des. 2022, 214, 110423. [Google Scholar] [CrossRef]
- Guo, F.; Zhou, X.; Liu, J.; Zhang, Y.; Li, D.; Zhou, H. A reinforcement learning decision model for online process parameters optimization from offline data in injection molding. Appl. Soft Comput. J. 2019, 85, 105828. [Google Scholar] [CrossRef]
- Hofmann, C.; Liu, X.; May, M.; Lanza, G. Hybrid Monte Carlo tree search based multi-objective scheduling. Prod. Eng. 2022, 17, 133–144. [Google Scholar] [CrossRef]















| Level | Know-What | Know-Why | Know-When | Know-How |
|---|---|---|---|---|
| Product | Defect detection [37], Product design [38] | Correlation between process and quality [23] | Quality prediction [26] | Quality improvement [39] |
| Process | Process monitoring [40] | Root cause analysis of process failure [41], Process modelling [42] | Process fault prediction [43], Process characteristics prediction [44] | Self-optimizing process planning [45], Adaptive process control [46] |
| Machine | Machine tool monitoring [47] | Fault diagnosis [48], Downtime prediction [49] | RUL prediction [50], Tool wear prediction [51] | Adaptive compensation of errors [52,53], |
| System | Anomaly detection [54] | Root cause analysis of production disturbances or casual-relationship discovery [55] | Production performance prediction [56], Human behavior control [57] | Predictive scheduling [58], Adaptive production control [59] |
| Item | Description |
|---|---|
| Query string | ( “manufacturing” OR “industry 4.0” OR “industrie 4.0” ) AND ( “machine learning” OR “deep learning” OR “supervised learning” OR “semi-supervised learning” OR “unsupervised learning” OR “reinforcement learning” ) |
| Year | Published from 2018 to 2022 |
| Language | English |
| Subject/Research area | Engineering |
| Document type | Article |
| Data Type | Handcrafted Features | Automatic Features |
|---|---|---|
| Image data | LBP [76], SIFT [77], HOG [78] | ICA, CNNs |
| Tabular data | feature selection | PCA, ICA, ANNs |
| Time series data | Time domain: mean, min, max, etc. Frequency domain: power spectrum [78] Time-frequency domain: DWT [79], STFT [80] | ICA, RNNs |
| Text data | Bag of Words (BoW) [81] | Word2vec [82] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, T.; Sampath, V.; May, M.C.; Shan, S.; Jorg, O.J.; Aguilar Martín, J.J.; Stamer, F.; Fantoni, G.; Tosello, G.; Calaon, M. Machine Learning in Manufacturing towards Industry 4.0: From ‘For Now’ to ‘Four-Know’. Appl. Sci. 2023, 13, 1903. https://doi.org/10.3390/app13031903
Chen T, Sampath V, May MC, Shan S, Jorg OJ, Aguilar Martín JJ, Stamer F, Fantoni G, Tosello G, Calaon M. Machine Learning in Manufacturing towards Industry 4.0: From ‘For Now’ to ‘Four-Know’. Applied Sciences. 2023; 13(3):1903. https://doi.org/10.3390/app13031903
Chicago/Turabian StyleChen, Tingting, Vignesh Sampath, Marvin Carl May, Shuo Shan, Oliver Jonas Jorg, Juan José Aguilar Martín, Florian Stamer, Gualtiero Fantoni, Guido Tosello, and Matteo Calaon. 2023. "Machine Learning in Manufacturing towards Industry 4.0: From ‘For Now’ to ‘Four-Know’" Applied Sciences 13, no. 3: 1903. https://doi.org/10.3390/app13031903