

An Updated Overview of Existing Cancer Databases and Identified Needs

1
Department of Biomedical Sciences, School of Medicine Greenville, University of South Carolina, Greenville, SC 29605, USA
2
Department of Computer Science and Engineering, College of Engineering and Computing, University of South Carolina, Columbia, SC 29208, USA
3
Prisma Health Cancer Institute, Prisma Health, Greenville, SC 29605, USA
*
Authors to whom correspondence should be addressed.
Biology 2023, 12(8), 1152; https://doi.org/10.3390/biology12081152
Submission received: 30 June 2023
/
Revised: 26 July 2023
/
Accepted: 14 August 2023
/
Published: 21 August 2023
(This article belongs to the Topic Advances in Bioinformatics and Computational Biology of Human Disease)
Abstract
:Simple Summary
This review examines the current state of cancer databases and identifies key needs in the field. The analysis of 71 databases reveals a lack of dedicated lipidomic and glycomic databases for cancer research, as well as limited proteomic databases. By comparing non-cancer databases, advancements in genomics, proteomics, lipidomics, and glycomics over the past eight years are highlighted. The evaluation of user-friendliness using the FAIRness principle emphasizes the importance of accessibility and usability. Overall, this review emphasizes the growth of cancer databases while identifying areas for improvement, offering valuable insights for researchers, clinicians, and database developers. Addressing these needs will advance cancer research and benefit the wider cancer community.
Abstract
Our search of existing cancer databases aimed to assess the current landscape and identify key needs. We analyzed 71 databases, focusing on genomics, proteomics, lipidomics, and glycomics. We found a lack of cancer-related lipidomic and glycomic databases, indicating a need for further development in these areas. Proteomic databases dedicated to cancer research were also limited. To assess overall progress, we included human non-cancer databases in proteomics, lipidomics, and glycomics for comparison. This provided insights into advancements in these fields over the past eight years. We also analyzed other types of cancer databases, such as clinical trial databases and web servers. Evaluating user-friendliness, we used the FAIRness principle to assess findability, accessibility, interoperability, and reusability. This ensured databases were easily accessible and usable. Our search summary highlights significant growth in cancer databases while identifying gaps and needs. These insights are valuable for researchers, clinicians, and database developers, guiding efforts to enhance accessibility, integration, and usability. Addressing these needs will support advancements in cancer research and benefit the wider cancer community.
1. Introduction
Cancer has been known for a long time, with credible evidence observed in fossilized dinosaurs and human bones from prehistoric times. The earliest record of cancer, written between 1500 and 1600 BC, was discovered in the 19th century [1]. Great physicians and scholars such as Hippocrates, Celsus, and Galen have contributed to a better understanding of cancer, its origin, and nature [1]. The “modern era” of cancer research began in the 19th century and led to the development of the current understanding by several investigators, notably Rudolf Virchow, who stated that cancer is “a disease of cells” [2]. This marked the onset of the war on cancer [3], with physicians and researchers collecting massive amounts of information about the mechanisms of cancer and its influence on genes, proteins, and other biomolecules.
To aggregate this massive amount of information into a central location, databases shared across the international community of researchers are a must. The availability of these databases plays a crucial role in aiding the discovery of the molecular basis of such a complex disease as cancer. The first modern cancer databases emerged in the early 1900s as individual physician’s or institutional projects in the United States or Europe [4]. It was not until 1959 that the American College of Surgeons (ACoS) formally adopted a policy allowing hospital-based cancer registries (i.e., databases) [4], with the primary importance of those databases for “monitoring cancer incidence, mortality, and survival” [5]. Nowadays, the functionality of cancer databases has significantly expanded through the analysis of complex datasets, including genomic, proteomic, glycomic, and clinical trials, to name a few. This review gives an update on the progress of cancer databases development in the last eight years (2015–2023). Periodic review of the existing cancer databases is needed to identify gaps and needs in our existing data collections and analysis tools. This report is one such example, with a focus on surveying the existing databases that aggregate nucleic acids (various forms of RNA and DNA), proteins, carbohydrates, and lipids in the context of cancer.
2. Materials and Methods
In this literature review focused on cancer databases in genomics, proteomics, lipidomics, and glycomics, our goal is to analyze their development over the past eight years and identify the existing needs within the cancer research community.
To select the databases for inclusion in the manuscript, we applied two criteria. Firstly, we considered databases published after 2015, as a comprehensive review of the human cancer databases was already available prior to that year [6]. However, we did include a number of papers written before 2015, to illustrate the growth and evolution of certain databases over time. Secondly, we ensured that the selected databases were cancer related. Following these criteria, we compiled a list of 95 databases covering multiple areas of cancer research. From this list, we decided to focus on genomics, proteomics, lipidomics, and glycomics as the fields of interest.
During our analysis, we observed the absence of cancer-related lipidomic and glycomic databases, and only a few cancer-related proteomic databases. Consequently, we decided to incorporate several human non-cancer databases that contain proteomic, lipidomic, and glycomic data. This allowed us to compare the overall progress of knowledge in these fields over the last eight years (2015–2023).
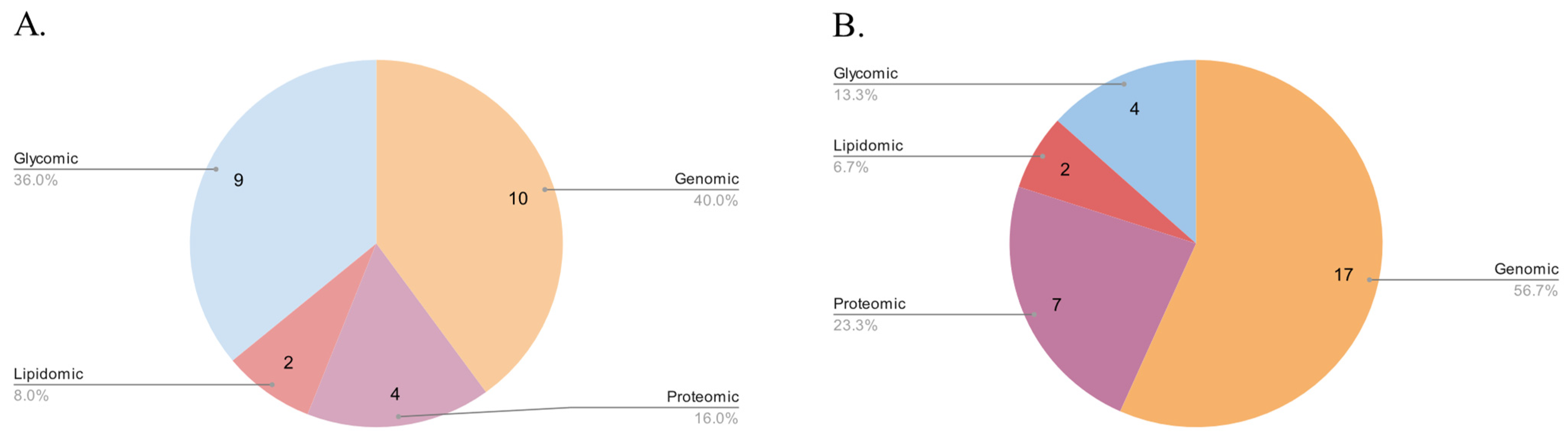
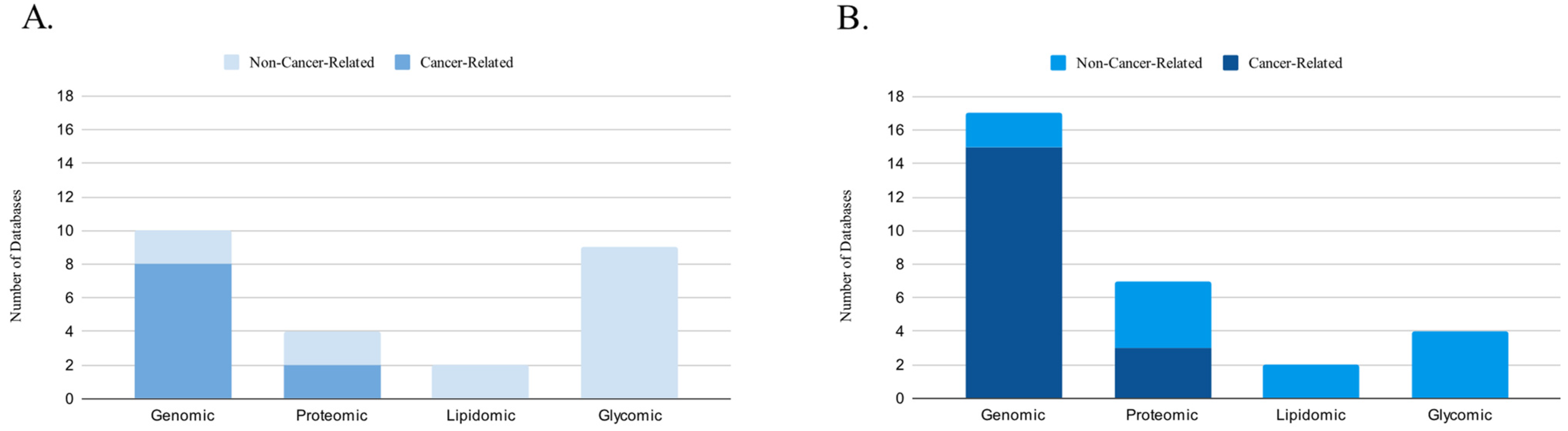
Furthermore, we examined other types of cancer databases, including databases of cancer clinical trials, web servers, and various other cancer-related databases that did not fit into the aforementioned categories. In total, our final selection comprised 71 databases, consisting of 26 genomic, 10 proteomic, 2 lipidomic, 13 glycomic, 7 dedicated to clinical trials, 6 web servers, and 9 other databases. Out of these, 46 databases were cancer related, while 25 were human non-cancer related. For our analysis, we utilized 108 sources, primarily published after 2015, including 101 original articles and 7 website sources. Additionally, 40 sources were published before 2015, while 61 sources were published after that year (Figure 1 and Figure 2).
Finally, we applied the FAIRness principle to evaluate the user-friendliness of the databases. The FAIR principle emphasizes that databases should be findable, accessible, interoperable, and reusable. To assess these criteria, we conducted our own research on each database. If a database was easily discoverable through web browsers such as Google or Safari, it was considered findable. If the database allowed for login or free access, it was considered accessible. Interoperability was determined by the presence of the database’s own statistical analysis function. Lastly, a database was considered reusable if it provided users with the ability to download data. All the searches and data collection were performed by the human research team, and none of the data collection process relied on ChatGPT or similar tools. The manuscript including all of its tables and figures was generated by the researchers. ChatGPT technology was only used at the last stage of the revision process of the manuscript to check for style, grammar, and spelling.
A database is considered cancer related if its content is predominantly centered around the topic of cancer. These databases often contain specific data related to cancer research, such as genomic data, molecular profiles, clinical information, other cancer-related datasets. For example, “The Cancer Genome Atlas” is a well-known cancer-related database that extensively convers genomic and molecular information specific to various types of cancer. Conversely, a database is classified as non-cancer related if its information is not primarily focused on cancer research. These databases may cover broader scientific topics, such as general protein data or information on various biological processes unrelated to cancer. As an illustration “UniProt” is a non-cancer-related database known for providing comprehensive information on proteins from various organisms, including those not directly related to cancer.
3. Results
3.1. Genomic Databases
Genetic mutations are pivotal in cancer development, and the National Institute of Health (NIH) established the Cancer Genome Atlas (TCGA) to identify significant cancer-causing genomic changes. TCGA has amassed over 11,000 cases spanning 33 tumor types, providing a vast dataset of molecular alterations [7]. Other databases have leveraged TCGA data, such as the OncomiR Cancer Database (OMCD), which utilizes TCGA’s 9500 cancer tissue samples for comparative genomic analyses of miRNA sequencing data [8]. Similarly, Cistrome Cancer serves as a web-based server utilizing TCGA to facilitate data retrieval for integrative gene regulation modeling [9]. Notably, there is a trend of creating smaller user-friendly databases derived from larger ones, exemplified by the cBio Cancer Genomic Portal. Developed to integrate extensive genomic projects, cBio enhances accessibility of raw data to the cancer research community [10].
The International Cancer Genome Consortium (ICGC) is another database aiming to construct a comprehensive catalog of mutational abnormalities observed in major tumor types [11]. ICGC incorporates data from 84 global cancer projects, encompassing approximately 77 million somatic mutations and molecular data from over 20,000 participants [11]. The Human Genome Browser at UCSC acts as a portal for displaying various genomic features, including gene predictions, alignments, polymorphisms, and more [12,13]. The Gene Expression Omnibus Database (GEO), established in 2000, focuses on gene expression and functional genomic datasets, extending beyond genome analysis to genome methylation, chromatin structure, and more [14]. Ensembl, created by Flicek et al. in 2014, provides tools for genomic analysis and has expanded each year. In Ensemble 2018, fields such as gene annotation, comparative genomics, genetics, and epigenomics were added by Zerbino et al. [15,16]. Recently, Martin et al. expanded Ensemble’s genome analysis beyond humans to investigate pangenomes across diverse species in Ensemble 2023 [17].
The National Cancer Institute Genomic Data Commons (GDC) is another prominent cancer database that focuses on storing, analyzing, and sharing genomic and clinical data from cancer patients. The GDC aims to democratize access to cancer genomic data and promote data sharing among researchers. By facilitating the application of precision medicine approaches, the GDC contributes to advancing the diagnosis and treatment of cancer [18,19]. OpenGDC, derived from the GDC, expands upon the existing platform by incorporating the Genomic Data Model. It introduces additional genomic data in Browser Extensible Data (BED) format and provides related metadata in a table-limited key-value format. OpenGDC enhances the efficiency of accessing genomic and clinical data while expanding the amount of information available for analysis [20].
A notable trend observed in cancer databases is the integration of diverse areas of cancer research into a single platform, allowing for the incorporation of multiple functionalities within a unified database. The Gene Expression Omnibus Database (GEO) serves as an example of such integration, offering not only gene expression data but also functional genomic datasets related to genome methylation, chromatin structure, and genome analysis. By encompassing various aspects of cancer research, GEO facilitates comprehensive investigations and analysis within a single database [14].
Futreal et al. emphasize the importance of mutations occurring in more than 1% of genes in the context of human cancers [21]. To facilitate easy access to information about these genes for researchers and physicians, several databases and web servers focus on cataloging them. Examples of such databases include the Network of Cancer Genes [22] and Cancer Hallmark Genes (CHG) [23]. These databases specifically examine genes that are significantly impacted or mutated in cancer.
The Catalogue of Somatic Mutations in Cancer (COSMIC) database is another valuable resource that stores somatic mutation data and related information about human cancer [24]. Since 2004, COSMIC has integrated coding mutations into its database, covering various genetic mechanisms through which somatic mutations contribute to cancer development. These mechanisms include non-coding mutations, gene fusions, copy-number variants, and drug resistance mutations [25]. Additionally, the COSMIC website provides users with the ability to visualize the 3D structure of proteins [25].
Mutagene is a database that delves into the mutational profiles of 37 distinct cancer types. It investigates the underlying components and signatures across over 9000 genomes and exomes, enabling comparisons of mutagenic processes between different types of cancers [26]. The Progenetix project, initiated in 2001, focuses on individual cancer copy number abnormalities (CNAs) profiles and associated metadata. Over the years, the project has expanded its collection of copy number variations (CNVs) and increased the number of samples, resulting in an improved database with enhanced data quality [27,28]. The MutEx database is dedicated to gathering information on the connections between somatic mutations, gene expression, and patient survival rates [29].
Oncomine is a cancer microarray database that conducts genome-wide expression analyses to identify tumor-related genes, novel biomarkers, and therapeutic targets [30]. Oncomine 3.0, developed in 2007, serves the biomedical research community by collecting, standardizing, analyzing, and delivering cancer transcriptome data [31]. Rhodes et al. utilized the Oncomine 3.0 database to identify genes, pathways, cancer types, and subtypes [31]. Currently, Oncomine has focused its efforts on assay analysis to assist oncologists in making clinical decisions. Their latest functional version is Oncomine Comprehensive Assay v3 (OCAv3), which covers 151 cancer-associated genes, allowing the detection of single nucleotide variants (SNVs), multiple-nucleotide variants (MSVs), and small insertions/deletions (indels) [32]. Since 2017, OCAv3 has been used in clinical settings to support oncologists in determining therapeutic courses. Additionally, Oncomine has developed Oncomine Comprehensive Assay Plus (OCA-Plus), which covers 501 genes, with 144 genes overlapping with OCAv3. OCA-Plus includes assays for microsatellite instability (MSI) and tumor mutational burden (TMB), all in one workflow. Currently, the update of OCA-Plus is under development before its release into clinical settings [32].
Cancer Specific Databases
Lung Cancer Explorer (LCE) is a database specifically dedicated to lung cancer. It enables researchers and clinicians to explore lung cancer data and perform various analyses [33]. PROMISE (Prostate Cancer Precision Medicine Multi-Institutional Collaborative Effort) is a consortium that aims to establish a collection of de-identified clinical and genomic patient data linked to patient outcomes. PROMISE involves different committees focusing on genomic data, statistical analyses, patient advocacy, and other aspects to advance precision medicine in prostate cancer research [34].
HCCDB is a notable database that focuses on hepatocellular carcinoma (HCC), a type of liver cancer. It serves as an online resource providing a consolidated platform for researching gene expression in relation to HCC. HCCDB allows for different types of analyses, including tissue-specific and tumor-specific expression analysis, as well as co-expression analysis [35].
OncoReveal database specifically focuses on non-small cell lung cancer (NSCLC) and colorectal cancer (CRC). It provides a platform for researchers and clinicians to access relevant data and insights related to these specific cancer types. For a summary of all the GENOMIC databases and web servers reviewed, as well as a visual representation of the information, please refer to Figure 1 and Table 1.
3.2. Proteomic Databases
The Clinical Proteomic Tumor Analysis Consortium (CPTAC) is a database created by the National Cancer Institute (NCI) that analyzes cancer biospecimens using mass spectrometry. It identifies and characterizes protein alterations within tumor samples, providing this proteomic data to the public in an accessible manner. CPTAC collaborates with the Cancer Genome Atlas (TCGA) to provide proteomic input for breast, colorectal, and ovarian tissue samples within the TCGA framework [36,37]. Lindgren’s paper in 2021 discusses the data application programming interface (API) created by CPTAC, which distributes processed datasets in a consistent format, facilitating advanced analysis [38].
The String database integrates known and predicted associations between proteins, including physical interactions and functional associations. It utilizes text mining, pathway analysis, and interaction databases to consolidate knowledge on protein interactions [39].
The UALCAN web portal, established in 2017, allows the cancer community to analyze and access cancer transcriptome, proteomics, and patient survival data. It has been expanded to include microRNAs, long non-coding RNAs (lncRNAs), DNA methylation data, and proteomics from CPTAC [40].
CanProVar focuses on human cancer proteome variations, providing a platform for the storage and retrieval of single amino acid alterations observed in cancer. Researchers can efficiently query and explore these alterations using CanProVar, which offers easy accessibility and search capabilities based on gene or protein IDs, cancer types, chromosome locations, and pathways. CanProVar 2.0 is the latest version, featuring a tenfold increase in the number of variations and improved search functionality [41].
The following resources mentioned below are not specifically cancer related, but they contribute to the understanding of proteomics and its role in cancer research. The RCSB Protein Data Bank provides access to 3D structures of biological macromolecules, aiding in the comprehension of protein and macromolecule structures [42]. The Universal Protein Resource (UniProt) is an open-source repository of protein sequences and functional annotations, offering visualizations of protein subcellular localization, structure, and interactions [43,44]. Proteome Discoverer is a data software used to convert mass spectrometry files to protein identifications [45]. SWISS-PROT and TrEMBL are protein sequence databases that provide information on protein functions, domains, structures, and post-translational modifications [46]. jPOST is a proteomic database that allows users to observe the frequency of post-translational modification detection, examine the co-occurrence of phosphorylation sites, and explore peptide sharing among proteoforms [47]. MatrisomeDB is a selected proteomic database containing data from various extracellular matrix (ECM) studies, offering a searchable repository of useful information related to normal tissues, cancers, and disorders [48]. Table 2 provides a summary of the mentioned proteomic databases.
3.3. Lipidomic Databases
Lipidomics plays an increasingly important role in cancer research due to the involvement of lipids in cancer growth, including their role in membrane structure, energy storage, and signal transduction. Some cancer cells, such as breast and ovarian cancer cells, rely on fatty acid oxidation for energy, while lipid accumulation has been observed in certain cancer cells [49]. Understanding the specific lipids affected in different types of cancer can aid in the development of improved treatments and diagnostic approaches.
Although lipidomics in cancer research is still under development, studies have explored the role of lipids in various cancers. For example, a study on lipidomics in colorectal cancer suggested that lipids may play a role in cancer development. However, further research involving larger populations and different cancer stages is needed. Additionally, investigating other factors contributing to increased lipid production in cancer cells is recommended [50].
While there is currently no cancer-specific lipidomic database, there are non-cancer lipidomic databases that provide valuable resources (Table 3). One such database is DBLiPro, which aims to establish a comprehensive knowledge base of human lipid metabolism and offers lipidome-centric analysis tools [51]. Lipid Maps is another notable database, consisting of two components: the Lipid Maps Proteome database (LMPD), which focuses on proteins [52], and the Lipid Maps Structure database (LMSD), which provides information on lipid structures and annotations of biologically relevant lipids [53]. In 2020, Lipid Maps updated its classification system and shorthand notation for lipid structures, including categories such as fatty acyls and glycerolipids [54].
3.4. Glycomic Databases
Galectin studies and glycomic research have gained importance in cancer studies due to involvement in crucial processes such as angiogenesis, metastasis, cell division, and immune evasion. Specific galectins and glycans play significant roles in these processes, modifying immune cells through interactions with glycosylated proteins and lipids. Understanding the effects of galectins and glycans and their alterations in cancer can lead to improved diagnostics and treatment. Changes in galectin expression may be influenced by protein trafficking and alterations in the glycocalyx composition of cancer cells [55,56,57,58].
While most glycomic databases are not cancer-specific, they provide valuable insights into glycan structure, function, and the field of glycoproteomics. Glycoproteomics focuses on identifying, locating, characterizing, and studying the abundance and role of glycosylated proteins in biological processes, including cancer. Mass spectrometry is commonly used for studying glycan alterations in cancer [59,60,61,62,63].
Given the limited number of cancer-related glycomic databases, incorporating glycomic information into cancer-related databases is crucial. Key glycomic databases include UniCarb-DB, UniPep, GlycoGene database (GGDB), and Glycome-DB. These databases offer a wealth of glycan and glycoproteomics data, enabling the examination of glycan structures, fragment data, biological context, and more [64,65,66,67,68,69,70]. Recent advancements in the field include GlycoRDF, GRITs database, GlyTouCan, Lectin Frontier Database (LfDB), and Carbohydrate Structure Database (CSDB), aiming to improve data quality, coverage, and standardization of carbohydrate notations [71,72,73,74,75,76], (Table 4).
3.5. Clinical Trial Databases
Clinical trials play a crucial role in cancer research, as they help evaluate the safety and effectiveness of diagnostics, treatments, and medication development. Integrating clinical trial databases is essential for understanding the impact of trials and patient demographics on the development of improved and personalized treatments. Here are several clinical trial databases relevant to cancer research: (1) Clinical Genomic Database (CGD): CGD provides a comprehensive collection of genetic conditions where genetic information can influence appropriate supportive care, medical decision-making, prognostic assessments, reproductive choices, and help avoid unnecessary diagnostic testing [77]. (2) Foundation Medicine Adult Cancer-Clinical Dataset: This dataset serves as a valuable resource for researching uncommon mutations and disorders, verifying their clinical importance, and discovering novel treatment options [78]. (3) Curated Cancer Clinical Outcomes Database (C3OD): C3OD integrates electronic medical records, tumor registry, biospecimen, and data registry to facilitate easier access to patient data in a unified location. Its goal is to accelerate eligibility screening for research purposes [79]. (4) Danish Head and Neck Cancer Database: Started in the early 1960s, this database focuses on a national strategy for multidisciplinary treatment of head and neck cancer in Denmark. It is utilized to describe the effects of reduced waiting time, changing epidemiology, and the influence of comorbidity and socioeconomic factors [80]. (5) National Cancer Database (NCDB): Over the past three decades, NCDB has evolved significantly, aggregating and categorizing approximately 40 million patient records from over 1500 hospitals. Its aim is to enhance the quality of cancer patient care [81]. (6) Surveillance, Epidemiology, and End Results (SEER) database: SEER focuses on investigating the history of colorectal cancer and patient care, providing valuable insights to the field [82]. (7) ClinVar: ClinVar is a public database designed for clinical laboratories, researchers, and expert panels. Launched in 2013, it contains over 600,000 submitted records from 1000 submitters, representing 430,000 unique variants. ClinVar enables data comparison among researchers [83].
Table 5 includes more detailed information about each database, its main features and scope.
3.6. Other Cancer Databases
Several other databases are also important for cancer research. The Database of Epigenetics Modifier (dbEM) contains potential targets for cancer treatment and information on mutations, copy number variations, and gene expression in tumor samples [84]. The Cancer Research Database (CRDB) explores the correlation between cancer and the COVID-19 pandemic, scoring other databases based on cancer types, sample size, omics results, and user interface [85]. The Comprehensive Review of Web Servers and Bioinformatics Tools for Cancer Prognosis Analysis discusses databases that examine prognostic biomarkers and survival rates, including PROGgene V2 [86,87]. The Cancer Drug Resistance (CancerDR) database provides information on anti-cancer drugs and their profiling across cancer cell lines [88]. DriverDB identifies driver genes/mutations using algorithms [89], while LncRNA2Target 2.0 and Lnc2Cancer focus on long non-coding RNAs associated with cancer [90,91]. The Genotype-Tissue Expression (GTEx) database investigates the relationship between genetic variation and gene expression in humans [92]. These evolving databases additionally contribute to improved diagnosis, prognosis, and therapeutic interventions in cancer research (Table 6).
Additionally, there are other databases that are non-cancer related that are being used alongside cancer databases to help increase the data surrounding the studied topic. Examples of these databases are The Comparative Toxicogenomic Database (CTD) connects toxicological data related to chemicals, genes, phenotypes, diseases, and exposures to enhance our understanding of human health [93]. The Therapeutic Target Database (TTD) provides information on known therapeutic proteins and nucleic acid targets. It includes pathway information and details about drugs/ligands directed at each target. The database offers sequences, 3D structures, functions, nomenclature, drug/ligand binding properties, drug usage, and effects associated with each target. Over time, TTD has expanded its repository to include target-regulating microRNAs, transcription factors, target-interacting proteins, as well as patented agents and their corresponding targets [94,95]. The Pharmacogenomics Knowledge Base (PharmGKB) presents genotypes, molecular data, and clinical information in a pathway-oriented representation. It also provides Very Important Pharmacogenes (VIP) summaries and links to additional external sources for further exploration. As of April 2021, PharmGKB contained annotated data for 715 drugs, 1761 genes, 227 diseases, and 165 clinical guidelines and drug labels [96,97]. DrugBank is a database that offers detailed molecular information about medications, including mechanisms, interactions, and targets. The most recent edition is DrugBank 5.0 [98]. These databases also are being used alongside cancer-related databases such as Ualcan, (protein database), the Cancer Research Database, and CancerResource, which is now a retired database.
Retired Databases
Development of databases has seen a number of changes, with some databases being retired while new ones emerge to fill the gaps. One retired database is the CancerResource database. This database was a comprehensive cancer-related data repository that integrated information from multiple databases to provide a fuller and more interactive resource. One key aspect of CancerResource was its focus on understanding how medications or drug-related substances interact with specific genes or proteins [99]. To achieve its comprehensive approach, CancerResource utilized several databases, including the Comparative Toxicogenomic Database (CTD), Therapeutic Target Database (TTD), Pharmacogenomics Knowledge Base (PharmGKB), and DrugBank. In the last eight years, the CancerResource database has expanded, encompassing approximately 91,000 drug-target relations, over 2000 cancer cell lines, and drug sensitivity data for about 50,000 drugs. CancerResource also allowed users to upload external expression and mutation data, enabling comparison with the database’s cell lines [100]. It is worth noting that as individual databases grow, interconnected databases such as CancerResource benefit from the acquisition of new and valuable information.
Genomic databases have also experienced the retiring of some of their databases. Among these retired genomic databases are the Roche Genomic Cancer Database and the Cancer Genes database [101,102], both of which played crucial roles in studying mutations surrounding cancer genes. The Roche Cancer Genome Database 2.0 (RCGDB) served as a comprehensive platform that combined different human mutation databases into a single location. This database offered interactive search capabilities for genes, samples, cell lines, diseases, and pathways, providing users with a centralized resource for accessing and analyzing cancer-related information. RCGDB also allowed for customized searches based on specific filter criteria, enabling researchers to address regularly occurring queries efficiently [103].
The contributions of the retired databases to cancer research have been significant, and their retirement leaves an opportunity for new advancements in the fields.
Similarly, the glycomic research community has experienced a transition in databases. While some database such as the GlycoSuite Database, EuroCarb, GlycoBase, and GlycoStore [64,66,70,71] have been retired and become inaccessible on web browsers such as Google Chrome and Safari, it is essential to acknowledge the wealth of information they previously provided. These databases were valuable resources for researchers, clinicians, and healthcare professionals studying glycomic data and its implications in various disease and biological processes.
3.7. Web-Based Servers
Web servers are instrumental in cancer research, offering various functionalities and benefits. GSCALite, for example, performs comprehensive analysis of cancer-related genes, including differential expression, survival analysis, genomic variation assessment, cancer pathway activity, miRNA regulation, drug sensitivity, and normal tissue expression [103]. OMIM serves as an online catalog, providing extensive information on genetic phenotypes, DNA/protein sequences, references, and mutational databases [104]. GEPIA is a web-based tool that enables interactive analysis of differential gene expression, correlation, survival, gene similarity, and dimensional reduction [105]. PepQuery facilitates proteomic validation of genomic alterations through simulations and experimental data [106]. These web servers play a critical role in empowering researchers and enabling in-depth exploration and analysis of cancer data (Table 7).
4. Discussion
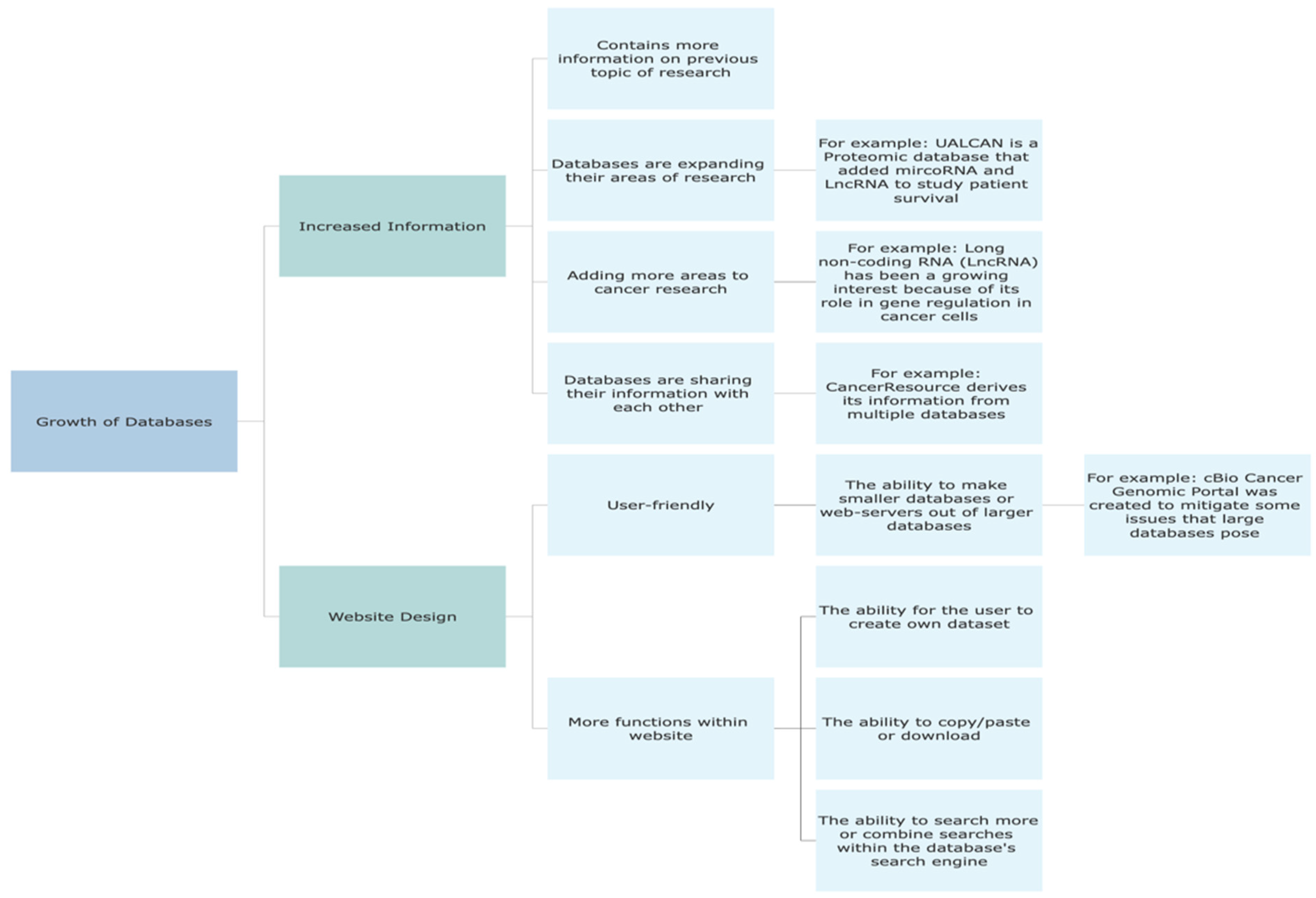
Databases have undergone significant growth and development in the past eight years, manifesting in various ways. Firstly, databases have expanded their information by continually adding more data. For instance, CanProVar 2.0 has experienced a tenfold increase in its content since its inception, enabling the dissemination of more comprehensive information. The sharing of data has emerged as a crucial focus for glycomic researchers, leading to the creation of databases such as GlyTouCan and the Carbohydrate Structure database. These databases aim to address integration challenges and other issues prevalent in glycan databases. CancerResource is another exemplar of databases sharing information, as it derives data from multiple sources.
Furthermore, databases have broadened their research scope by incorporating additional topics beyond their original areas of focus. A notable instance is Ualcan, a proteomic database that integrated microRNA and lncRNA data to explore patient survival outcomes. This expansion reflects the inclination of databases to explore diverse research domains within a single platform.
The second aspect of database growth pertains to database design and usability. Database developers and curators have striven to enhance user-friendliness, often evaluated through the FAIRness principle. This principle encompasses various criteria, including findability, accessibility, interpretability, and reusability, to determine the fairness and usability of scientific research, including databases [107]. A user-friendly database should be discoverable, easily accessible, interpretable, and allow data reuse for any purpose. Many databases examined in this study have endeavored to improve user-friendliness through website redesign, resulting in enhanced search engines and capabilities such as copying/pasting or downloading datasets. Additionally, efforts have been made to enable users to create their datasets within the database.
Overall, databases have experienced growth in terms of data expansion and user-friendly design. These advancements facilitate information sharing, enable broader research exploration, and contribute to the usability and accessibility of scientific research databases (Figure 3).
5. Conclusions
In conclusion, our search summary of existing cancer databases reveals significant growth and development over the past eight years. We have identified the need for more cancer-related lipidomic and glycomic databases, as well as the scarcity of proteomic databases in the cancer domain. Additionally, we have highlighted the importance of user-friendliness in database design and adherence to the FAIRness principles. This comprehensive analysis provides valuable insights into the current state of cancer databases and the areas that require further attention and improvement.
Author Contributions
Conceptualization, A.V.B. and H.V.; methodology, A.V.B. and H.V.; validation, A.F.; investigation, B.K.A. and A.F.; resources, A.V.B. and H.V.; data curation, B.K.A.; writing—original draft preparation, B.K.A.; writing—review and editing, B.K.A., A.F., H.V. and A.V.B.; visualization, B.K.A. and A.F.; supervision, A.V.B. and H.V.; project administration, A.V.B.; funding acquisition, A.V.B. and H.V. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by a grant from the National Institutes of Health P20 RR-01646100 awarded to H.V., and by the Transformative Seed Grant awarded to H.V. and A.V.B. by the Health Sciences Center at Prisma Health. The medical student research stipend for B.K.A. was funded by the Sargent Foundation.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All data are available in the manuscript.
Acknowledgments
ChatGPT technology (https://chat.openai.com accessed on 15 August 2023) was used at the last stage of the revision process of the manuscript to check for style, grammar, and spelling.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Faguet, G.B. A brief history of cancer: Age-old milestones underlying our current knowledge database. Int. J. Cancer 2015, 136, 2022–2036. [Google Scholar] [CrossRef] [PubMed]
- Weinstein, I.B.; Case, K. The History of Cancer Research: Introducing an AACR Centennial Series. Cancer Res. 2008, 68, 6861–6862. [Google Scholar] [CrossRef] [PubMed]
- SEER Training Modules. War Facts and the War on Cancer; National Cancer Institute: Bethesda, MA, USA, 2023. [Google Scholar]
- SEER Training Modules. Brief History of Cancer Registration; National Cancer Institute: Bethesda, MA, USA, 2023. [Google Scholar]
- Ursin, G. Cancer registration in the era of modern oncology and GDPR. Acta Oncol. 2019, 58, 1547–1548. [Google Scholar] [CrossRef] [PubMed]
- Pavlopoulou, A.; Spandidos, D.A.; Michalopoulos, I. Human cancer databases (Review). Oncol. Rep. 2015, 33, 3–18. [Google Scholar] [CrossRef] [PubMed]
- Tomczak, K.; Czerwińska, P.; Wiznerowicz, M. Review The Cancer Genome Atlas (TCGA): An immeasurable source of knowledge. Contemp. Oncol. 2015, 2015, 68–77. [Google Scholar] [CrossRef]
- Sarver, A.L.; Sarver, A.E.; Yuan, C.; Subramanian, S. OMCD: OncomiR Cancer Database. BMC Cancer 2018, 18, 1223. [Google Scholar] [CrossRef]
- Mei, S.; Meyer, C.A.; Zheng, R.; Qin, Q.; Wu, Q.; Jiang, P.; Li, B.; Shi, X.; Wang, B.; Fan, J.; et al. Cistrome cancer: A web resource for integrative gene regulation modeling in cancer. Cancer Res. 2017, 77, e19–e22. [Google Scholar] [CrossRef]
- Cerami, E.; Gao, J.; Dogrusoz, U.; Gross, B.E.; Sumer, S.O.; Aksoy, B.A.; Jacobsen, A.; Byrne, C.J.; Heuer, M.L.; Larsson, E.; et al. The cBio cancer genomics portal: An open platform for exploring multidimensional cancer genomics data. Cancer Discov. 2012, 2, 401–404. [Google Scholar] [CrossRef]
- Zhang, J.; Bajari, R.; Andric, D.; Gerthoffert, F.; Lepsa, A.; Nahal-Bose, H.; Stein, L.D.; Ferretti, V. The International Cancer Genome Consortium Data Portal. Nat. Biotechnol. 2019, 37, 367–369. [Google Scholar] [CrossRef]
- Kent, W.J.; Sugnet, C.W.; Furey, T.S.; Roskin, K.M.; Pringle, T.H.; Zahler, A.M.; Haussler, D. The Human Genome Browser at UCSC. Genome Res. 2002, 12, 996–1006. [Google Scholar] [CrossRef]
- The Human Genome Browser at UCSC. Available online: https://genome.cshlp.org/content/12/6/996.short (accessed on 6 February 2023).
- Clough, E.; Barrett, T. The Gene Expression Omnibus database. Methods Mol. Biol. 2016, 1418, 93–110. [Google Scholar] [PubMed]
- Flicek, P.; Amode, M.R.; Barrell, D.; Beal, K.; Billis, K.; Brent, S.; Carvalho-Silva, D.; Clapham, P.; Coates, G.; Fitzgerald, S.; et al. Ensembl 2014. Nucleic Acids Res. 2014, 42, D749–D755. [Google Scholar] [CrossRef] [PubMed]
- Zerbino, D.R.; Achuthan, P.; Akanni, W.; Amode, M.R.; Barrell, D.; Bhai, J.; Billis, K.; Cummins, C.; Gall, A.; Girón, C.G.; et al. Ensembl 2018. Nucleic Acids Res. 2018, 46, D754–D761. [Google Scholar] [CrossRef]
- Martin, F.J.; Amode, M.R.; Aneja, A.; Austine-Orimoloye, O.; Azov, A.G.; Barnes, I.; Becker, A.; Bennett, R.; Berry, A.; Bhai, J.; et al. Ensembl 2023. Nucleic Acids Res. 2023, 51, D933–D941. [Google Scholar] [CrossRef] [PubMed]
- Jensen, M.A.; Ferretti, V.; Grossman, R.L.; Staudt, L.M. The NCI Genomic Data Commons as an engine for precision medicine. Blood 2017, 130, 453–459. [Google Scholar] [CrossRef] [PubMed]
- GDC. Available online: https://portal.gdc.cancer.gov/ (accessed on 15 February 2023).
- Cappelli, E.; Cumbo, F.; Bernasconi, A.; Canakoglu, A.; Ceri, S.; Masseroli, M.; Weitschek, E. OpenGDC: Unifying, Modeling, Integrating Cancer Genomic Data and Clinical Metadata. Appl. Sci. 2020, 10, 6367. [Google Scholar] [CrossRef]
- Futreal, P.A.; Coin, L.; Marshall, M.; Down, T.; Hubbard, T.; Wooster, R.; Rahman, N.; Stratton, M.R. A census of human cancer genes. Nat. Rev. Cancer 2004, 4, 177–183. [Google Scholar] [CrossRef]
- Repana, D.; Nulsen, J.; Dressler, L.; Bortolomeazzi, M.; Venkata, S.K.; Tourna, A.; Yakovleva, A.; Palmieri, T. The Network of Cancer Genes (NCG): A comprehensive catalogue of known and candidate cancer genes from cancer sequencing screens 06 Biological Sciences 0604 Genetics 11 Medical and Health Sciences 1112 Oncology and Carcinogenesis 06 Biological Sciences 0601 Biochemistry and Cell Biology. Genome Biol. 2019, 20, 1–20. [Google Scholar]
- Zhang, D.; Huo, D.; Xie, H.; Wu, L.; Zhang, J.; Liu, L.; Jin, Q.; Chen, X. CHG: A Systematically Integrated Database of Cancer Hallmark Genes. Front. Genet. 2020, 11, 29. [Google Scholar] [CrossRef]
- Bamford, S.; Dawson, E.; Forbes, S.; Clements, J.; Pettett, R.; Dogan, A.; Flanagan, A.; Teague, J.; Futreal, A.P.; Stratton, M.R.; et al. The COSMIC (Catalogue of Somatic Mutations in Cancer) database and website. Br. J. Cancer 2004, 91, 355–358. [Google Scholar] [CrossRef]
- Tate, J.G.; Bamford, S.; Jubb, H.C.; Sondka, Z.; Beare, D.M.; Bindal, N.; Boutselakis, H.; Cole, C.G.; Creatore, C.; Dawson, E.; et al. COSMIC: The Catalogue of Somatic Mutations in Cancer. Nucleic Acids Res. 2019, 47, D941–D947. [Google Scholar] [CrossRef] [PubMed]
- Brown, A.-L.; Li, M.; Goncearenco, A.; Panchenko, A.R. Finding driver mutations in cancer: Elucidating the role of background mutational processes. PLoS Comput. Biol. 2019, 15, e1006981. [Google Scholar] [CrossRef] [PubMed]
- Huang, Q.; Carrio-Cordo, P.; Gao, B.; Paloots, R.; Baudis, M. The Progenetix oncogenomic resource in 2021. Database 2021, 2021, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Progenetix. Available online: https://progenetix.org/ (accessed on 15 February 2023).
- Ping, J.; Oyebamiji, O.; Yu, H.; Ness, S.; Chien, J.; Ye, F.; Kang, H.; Samuels, D.; Ivanov, S.; Chen, D.; et al. MutEx: A multifaceted gateway for exploring integrative pan-cancer genomic data. Briefings Bioinform. 2020, 21, 1479–1486. [Google Scholar] [CrossRef] [PubMed]
- Rhodes, D.R.; Yu, J.; Shanker, K.; Deshpande, N.; Varambally, R.; Ghosh, D.; Barrette, T.; Pander, A.; Chinnaiyan, A.M. ONCOMINE: A Cancer Microarray Database and Integrated Data-Mining Platform 1. 2004. Available online: www.oncomine.org (accessed on 6 February 2023).
- Rhodes, D.R.; Kalyana-Sundaram, S.; Mahavisno, V.; Varambally, R.; Yu, J.; Briggs, B.B.; Barrette, T.R.; Anstet, M.J.; Kincead-Beal, C.; Kulkarni, P.; et al. Oncomine 3.0: Genes, Pathways, and Networks in a Collection of 18,000 Cancer Gene Expression Profiles. Neoplasia 2007, 9, 166–180. [Google Scholar] [CrossRef]
- Vestergaard, L.K.; Oliveira, D.N.P.; Poulsen, T.S.; Høgdall, C.K.; Høgdall, E.V. OncomineTM comprehensive assay v3 vs. OncomineTM comprehensive assay plus. Cancers 2021, 13, 5230. [Google Scholar] [CrossRef] [PubMed]
- Cai, L.; Lin, S.; Girard, L.; Zhou, Y.; Yang, L.; Ci, B.; Zhou, Q.; Luo, D.; Yao, B.; Tang, H.; et al. LCE: An open web portal to explore gene expression and clinical associations in lung cancer. Oncogene 2018, 38, 2551–2564. [Google Scholar] [CrossRef]
- Koshkin, V.S.; Patel, V.G.; Ali, A.; Bilen, M.A.; Ravindranathan, D.; Park, J.J.; Kellezi, O.; Cieslik, M.; Shaya, J.; Cabal, A.; et al. PROMISE: A real-world clinical-genomic database to address knowledge gaps in prostate cancer. Prostate Cancer Prostatic Dis. 2021, 25, 388–396. [Google Scholar] [CrossRef]
- Lian, Q.; Wang, S.; Zhang, G.; Wang, D.; Luo, G.; Tang, J.; Chen, L.; Gu, J. HCCDB: A Database of Hepatocellular Carcinoma Expression Atlas. Genom. Proteom. Bioinform. 2018, 16, 269–275. [Google Scholar] [CrossRef]
- Edwards, N.J.; Oberti, M.; Thangudu, R.R.; Cai, S.; McGarvey, P.B.; Jacob, S.; Madhavan, S.; Ketchum, K.A. The CPTAC Data Portal: A Resource for Cancer Proteomics Research. J. Proteome Res. 2015, 14, 2707–2713. [Google Scholar] [CrossRef]
- Clinical Proteomic Tumor Analysis Consortium (CPTAC)|NCI Genomic Data Commons. Available online: https://gdc.cancer.gov/about-gdc/contributed-genomic-data-cancer-research/clinical-proteomic-tumor-analysis-consortium-cptac (accessed on 6 February 2023).
- Lindgren, C.M.; Adams, D.W.; Kimball, B.; Boekweg, H.; Tayler, S.; Pugh, S.L.; Payne, S.H. Simplified and Unified Access to Cancer Proteogenomic Data. J. Proteome Res. 2021, 20, 1902–1910. [Google Scholar] [CrossRef]
- Szklarczyk, D.; Gable, A.L.; Nastou, K.C.; Lyon, D.; Kirsch, R.; Pyysalo, S.; Doncheva, N.T.; Legeay, M.; Fang, T.; Bork, P.; et al. Correction to ‘The STRING database in 2021: Customizable protein–protein networks, and functional characterization of user-uploaded gene/measurement sets’. Nucleic Acids Res. 2021, 49, 10800. [Google Scholar] [CrossRef] [PubMed]
- Chandrashekar, D.S.; Karthikeyan, S.K.; Korla, P.K.; Patel, H.; Shovon, A.R.; Athar, M.; Netto, G.J.; Qin, Z.S.; Kumar, S.; Manne, U.; et al. UALCAN: An update to the integrated cancer data analysis platform. Neoplasia 2022, 25, 18–27. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Wang, B.; Xu, J.; Wang, X.; Xie, L.; Zhang, B.; Li, Y.; Li, J. CanProVar 2.0: An Updated Database of Human Cancer Proteome Variation. J. Proteome Res. 2017, 16, 421–432. [Google Scholar] [CrossRef] [PubMed]
- Rose, P.W.; Prlić, A.; Bi, C.; Bluhm, W.F.; Christie, C.H.; Dutta, S.; Green, R.K.; Goodsell, D.S.; Westbrook, J.D.; Woo, J.; et al. The RCSB Protein Data Bank: Views of structural biology for basic and applied research and education. Nucleic Acids Res. 2015, 43, D345–D356. [Google Scholar] [CrossRef] [PubMed]
- Consortium, T.U. Activities at the Universal Protein Resource (UniProt). Nucleic Acids Res. 2014, 42, 7486. [Google Scholar] [CrossRef]
- Bateman, A; UniProt: A Worldwide Hub of Protein Knowledge. Nucleic Acids Res 2019, 47, D506–D515. [CrossRef]
- Orsburn, B.C. Proteome Discoverer—A Community Enhanced Data Processing Suite for Protein Informatics. Proteomes 2021, 9, 15. [Google Scholar] [CrossRef]
- O’Donovan, C.; Martin, M.J.; Gattiker, A.; Gasteiger, E.; Bairoch, A.; Apweiler, R. High-quality protein knowledge resource: SWISS-PROT and TrEMBL. Briefings Bioinform. 2002, 3, 275–284. [Google Scholar] [CrossRef]
- Moriya, Y.; Kawano, S.; Okuda, S.; Watanabe, Y.; Matsumoto, M.; Takami, T.; Kobayashi, D.; Yamanouchi, Y.; Araki, N.; Yoshizawa, A.C.; et al. The jPOST environment: An integrated proteomics data repository and database. Nucleic Acids Res. 2019, 47, D1218–D1224. [Google Scholar] [CrossRef]
- Shao, X.; Taha, I.N.; Clauser, K.; Gao, Y.; Naba, A. MatrisomeDB: The ECM-protein knowledge database. Nucleic Acids Res. 2020, 48, D1136–D1144. [Google Scholar] [CrossRef] [PubMed]
- Yan, F.; Zhao, H.; Zeng, Y. Lipidomics: A promising cancer biomarker. Clin. Transl. Med. 2018, 7, 21. [Google Scholar] [CrossRef] [PubMed]
- Buszewska-Forajta, M.; Pomastowski, P.; Monedeiro, F.; Walczak-Skierska, J.; Markuszewski, M.; Matuszewski, M.; Markuszewski, M.J.; Buszewski, B. Lipidomics as a Diagnostic Tool for Prostate Cancer. Cancers 2021, 13, 2000. [Google Scholar] [CrossRef] [PubMed]
- Wu, Q.; Huang, Y.; Kong, X.; Jia, B.; Lu, X.; Chen, Y.; Huang, Z.; Li, Y.-Y.; Dai, W. DBLiPro: A Database for Lipids and Proteins in Human Lipid Metabolism. Phenomics 2023, 3, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Cotter, D.; Maer, A.; Guda, C.; Saunders, B.; Subramaniam, S. LMPD: LIPID MAPS proteome database. Nucleic Acids Res. 2006, 34 (Suppl. S1), D507–D510. [Google Scholar] [CrossRef]
- Sud, M.; Fahy, E.; Cotter, D.; Brown, A.; Dennis, E.A.; Glass, C.K.; Merrill, A.H.; Murphy, R.C.; Raetz, C.R.H.; Russell, D.W.; et al. LMSD: LIPID MAPS structure database. Nucleic Acids Res. 2007, 35 (Suppl. S1), D527–D532. [Google Scholar] [CrossRef]
- Liebisch, G.; Fahy, E.; Aoki, J.; Dennis, E.A.; Durand, T.; Ejsing, C.S.; Fedorova, M.; Feussner, I.; Griffiths, W.J.; Köfeler, H.; et al. Update on LIPID MAPS classification, nomenclature, and shorthand notation for MS-derived lipid structures. J. Lipid Res. 2020, 61, 1539–1555. [Google Scholar] [CrossRef]
- Blair, B.B.; Funkhouser, A.T.; Goodwin, J.L.; Strigenz, A.M.; Chaballout, B.H.; Martin, J.C.; Arthur, C.M.; Funk, C.R.; Edenfield, W.J.; Blenda, A.V. Increased Circulating Levels of Galectin Proteins in Patients with Breast, Colon, and Lung Cancer. Cancers 2021, 13, 4819. [Google Scholar] [CrossRef]
- Pinho, S.S.; Reis, C.A. Glycosylation in cancer: Mechanisms and clinical implications. Nat. Rev. Cancer 2015, 15, 540–555. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.-T.; Stowell, S.R. The role of galectins in immunity and infection. Nat. Rev. Immunol. 2023, 23, 1–16. [Google Scholar] [CrossRef]
- Funkhouser, A.T.; Strigenz, A.M.; Blair, B.B.; Miller, A.P.; Shealy, J.C.; Ewing, J.A.; Martin, J.C.; Funk, C.R.; Edenfield, W.J.; Blenda, A.V. KIT Mutations Correlate with Higher Galectin Levels and Brain Metastasis in Breast and Non-Small Cell Lung Cancer. Cancers 2022, 14, 2781. [Google Scholar] [CrossRef] [PubMed]
- Hizal, D.B.; Wolozny, D.; Colao, J.; Jacobson, E.; Tian, Y.; Krag, S.S.; Betenbaugh, M.J.; Zhang, H. Glycoproteomic and glycomic databases. Clin. Proteom. 2014, 11, 15. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Zhang, H. Glycoproteomics and clinical applications. Proteom.-Clin. Appl. 2010, 4, 124–132. [Google Scholar] [CrossRef]
- Kim, E.H.; Misek, D.E. Glycoproteomics-Based Identification of Cancer Biomarkers. Int. J. Proteom. 2011, 2011, 2010–2166. [Google Scholar] [CrossRef]
- Pan, S.; Chen, R.; Aebersold, R.; Brentnall, T.A. Mass Spectrometry Based Glycoproteomics—From a Proteomics Perspective. Mol. Cell. Proteom. 2011, 10, R110.003251. [Google Scholar] [CrossRef] [PubMed]
- Ferreira, J.A.; Relvas-Santos, M.; Peixoto, A.; Silva, A.M.; Santos, L.L. Glycoproteogenomics: Setting the Course for Next-generation Cancer Neoantigen Discovery for Cancer Vaccines. Genom. Proteom. Bioinform. 2021, 19, 25–43. [Google Scholar] [CrossRef]
- Cooper, C.A.; Harrison, M.J.; Wilkins, M.R.; Packer, N.H. GlycoSuiteDB: A new curated relational database of glycoprotein glycan structures and their biological sources. Nucleic Acids Res. 2001, 29, 332–335. [Google Scholar] [CrossRef]
- Hayes, C.A.; Karlsson, N.G.; Struwe, W.B.; Lisacek, F.; Rudd, P.M.; Packer, N.H.; Campbell, M.P. UniCarb-DB: A database resource for glycomic discovery. Bioinformatics 2011, 27, 1343–1344. [Google Scholar] [CrossRef]
- von der Lieth, C.-W.; Freire, A.A.; Blank, D.; Campbell, M.P.; Ceroni, A.; Damerell, D.R.; Dell, A.; Dwek, R.A.; Ernst, B.; Fogh, R.; et al. EUROCarbDB: An open-access platform for glycoinformatics. Glycobiology 2011, 21, 493–502. [Google Scholar] [CrossRef]
- Zhang, H.; Loriaux, P.; Eng, J.; Campbell, D.; Keller, A.; Moss, P.; Bonneau, R.; Zhang, N.; Zhou, Y.; Wollscheid, B.; et al. UniPep—a database for human N-linked glycosites: A resource for biomarker discovery. Genome Biol. 2006, 7, R73. [Google Scholar] [CrossRef]
- Togayachi, A.; Dae, K.-Y.; Shikanai, T.; Narimatsu, H. A Database System for Glycogenes (GGDB). Exp. Glycosci. 2008, 423–425. [Google Scholar] [CrossRef]
- Ranzinger, R.; Frank, M.; von der Lieth, C.-W.; Herget, S. Glycome-DB.org: A portal for querying across the digital world of carbohydrate sequences. Glycobiology 2009, 19, 1563–1567. [Google Scholar] [CrossRef] [PubMed]
- Campbell, M.P.; Royle, L.; Radcliffe, C.M.; Dwek, R.A.; Rudd, P.M. GlycoBase and autoGU: Tools for HPLC-based glycan analysis. Bioinformatics 2008, 24, 1214–1216. [Google Scholar] [CrossRef]
- Zhao, S.; Walsh, I.; Abrahams, J.L.; Royle, L.; Nguyen-Khuong, T.; Spencer, D.; Fernandes, D.L.; Packer, N.H.; Rudd, P.M.; Campbell, M.P. GlycoStore: A database of retention properties for glycan analysis. Bioinformatics 2018, 34, 3231–3232. [Google Scholar] [CrossRef] [PubMed]
- Ranzinger, R.; Aoki-Kinoshita, K.F.; Campbell, M.P.; Kawano, S.; Lütteke, T.; Okuda, S.; Shinmachi, D.; Shikanai, T.; Sawaki, H.; Toukach, P.; et al. GlycoRDF: An ontology to standardize glycomics data in RDF. Bioinformatics 2015, 31, 919–925. [Google Scholar] [CrossRef]
- Weatherly, D.B.; Arpinar, F.S.; Porterfield, M.; Tiemeyer, M.; York, W.S.; Ranzinger, R. GRITS Toolbox—A freely available software for processing, annotating and archiving glycomics mass spectrometry data. Glycobiology 2019, 29, 452–460. [Google Scholar] [CrossRef]
- Tiemeyer, M.; Aoki, K.; Paulson, J.; Cummings, R.D.; York, W.S.; Karlsson, N.G.; Lisacek, F.; Packer, N.H.; Campbell, M.P.; Aoki, N.P.; et al. GlyTouCan: An accessible glycan structure repository. Glycobiology 2017, 27, 915–919. [Google Scholar] [CrossRef]
- Hirabayashi, J.; Tateno, H.; Shikanai, T.; Aoki-Kinoshita, K.F.; Narimatsu, H. The Lectin Frontier Database (LfDB), and Data Generation Based on Frontal Affinity Chromatography. Molecules 2015, 20, 951–973. [Google Scholar] [CrossRef]
- Toukach, P.V.; Shirkovskaya, A.I. Carbohydrate Structure Database and Other Glycan Databases as an Important Element of Glycoinformatics. Russ. J. Bioorg. Chem. 2022, 48, 457–466. [Google Scholar] [CrossRef]
- Solomon, B.D.; Nguyen, A.-D.; Bear, K.A.; Wolfsberg, T.G. Clinical Genomic Database. Proc. Natl. Acad. Sci. 2013, 110, 9851–9855. [Google Scholar] [CrossRef]
- Hartmaier, R.J.; Albacker, L.A.; Chmielecki, J.; Bailey, M.; He, J.; Goldberg, M.E.; Ramkissoon, S.; Suh, J.; Elvin, J.A.; Chiacchia, S.; et al. High-throughput genomic profiling of adult solid tumors reveals novel insights into cancer pathogenesis. Cancer Res. 2017, 77, 2464–2475. [Google Scholar] [CrossRef] [PubMed]
- Mudaranthakam, D.P.; Thompson, J.; Hu, J.; Pei, D.; Chintala, S.R.; Park, M.; Fridley, B.L.; Gajewski, B.; Koestler, D.C.; Mayo, M.S. A Curated Cancer Clinical Outcomes Database (C3OD) for accelerating patient recruitment in cancer clinical trials. JAMIA Open 2018, 1, 166–171. [Google Scholar] [CrossRef] [PubMed]
- Overgaard, J.; Jovanovic, A.; Godballe, C.; Eriksen, J.G. The Danish Head and Neck Cancer database. Clin. Epidemiol. 2016, 8, 491–496. [Google Scholar] [CrossRef] [PubMed]
- McCabe, R.M. National Cancer Database: The Past, Present, and Future of the Cancer Registry and Its Efforts to Improve the Quality of Cancer Care. Semin. Radiat. Oncol. 2019, 29, 323–325. [Google Scholar] [CrossRef] [PubMed]
- Daly, M.C.; Paquette, I.M. Surveillance, Epidemiology, and End Results (SEER) and SEER-Medicare Databases: Use in Clinical Research for Improving Colorectal Cancer Outcomes. Clin. Colon Rectal Surg. 2019, 32, 61–68. [Google Scholar] [CrossRef] [PubMed]
- Landrum, M.J.; Kattman, B.L. ClinVar at five years: Delivering on the promise. Hum. Mutat. 2018, 39, 1623–1630. [Google Scholar] [CrossRef]
- Nanda, J.S.; Kumar, R.; Raghava, G.P.S. dbEM: A database of epigenetic modifiers curated from cancerous and normal genomes. Sci. Rep. 2016, 6. [Google Scholar] [CrossRef]
- Ullah, S.; Ullah, F.; Rahman, W.; Karras, A.D.; Ullah, A.; Ahmad, G.; Ijaz, M.; Gao, T. The Cancer Research Database (CRDB): Integrated Platform to Gain Statistical Insight Into the Correlation between Cancer and COVID-19. JMIR Cancer 2022, 8. [Google Scholar] [CrossRef]
- Zheng, H.; Zhang, G.; Zhang, L.; Wang, Q.; Li, H.; Han, Y.; Xie, L.; Yan, Z.; Li, Y.; An, Y.; et al. Comprehensive Review of Web Servers and Bioinformatics Tools for Cancer Prognosis Analysis. Front. Oncol. 2020, 10, 68. [Google Scholar] [CrossRef]
- Goswami, C.P.; Nakshatri, H. PROGgeneV2: Enhancements on the existing database. BMC Cancer 2014, 14, 1–6. [Google Scholar] [CrossRef]
- Kumar, R.; Chaudhary, K.; Gupta, S.; Singh, H.; Kumar, S.; Gautam, A.; Kapoor, P.; Raghava, G.P.S. CancerDR: Cancer Drug Resistance Database. Sci. Rep. 2013, 3. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.-H.; Shen, P.-C.; Chen, C.-Y.; Hsu, A.-N.; Cho, Y.-C.; Lai, Y.-L.; Chen, F.-H.; Li, C.-Y.; Wang, S.-C.; Chen, M.; et al. DriverDBv3: A multi-omics database for cancer driver gene research. Nucleic Acids Res. 2020, 48, D863–D870. [Google Scholar] [CrossRef] [PubMed]
- Cheng, L.; Wang, P.; Tian, R.; Wang, S.; Guo, Q.; Luo, M.; Zhou, W.; Liu, G.; Jiang, H.; Jiang, Q. LncRNA2Target v2.0: A comprehensive database for target genes of lncRNAs in human and mouse. Nucleic Acids Res. 2019, 47, D140–D144. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Shang, S.; Guo, S.; Li, X.; Zhou, H.; Liu, H.; Sun, Y.; Wang, J.; Wang, P.; Zhi, H.; et al. Lnc2Cancer 3.0: An updated resource for experimentally supported lncRNA/circRNA cancer associations and web tools based on RNA-seq and scRNA-seq data. Nucleic Acids Res. 2021, 49, D1251–D1258. [Google Scholar] [CrossRef] [PubMed]
- Carithers, L.J.; Moore, H.M. The Genotype-Tissue Expression (GTEx) Project. Biopreservation Biobanking 2015, 13, 307–308. [Google Scholar] [CrossRef]
- Davis, A.P.; Grondin, C.J.; Johnson, R.J.; Sciaky, D.; Wiegers, J.; Wiegers, T.C.; Mattingly, C.J. Comparative Toxicogenomics Database (CTD): Update 2021. Nucleic Acids Res. 2021, 49, D1138–D1143. [Google Scholar] [CrossRef]
- Chen, X.; Ji, Z.L.; Chen, Y.Z. TTD: Therapeutic Target Database. Nucleic Acids Res. 2002, 30, 412–415. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, S.; Li, F.; Zhou, Y.; Zhang, Y.; Wang, Z.; Zhang, R.; Zhu, J.; Ren, Y.; Tan, Y.; et al. Therapeutic target database 2020: Enriched resource for facilitating research and early development of targeted therapeutics. Nucleic Acids Res. 2020, 48, D1031–D1041. [Google Scholar] [CrossRef]
- Thorn, C.F.; Klein, T.E.; Altman, R.B. PharmGKB: The pharmacogenomics knowledge base. Methods Mol. Biol. 2013, 1015, 311–320. [Google Scholar]
- Gong, L.; Whirl-Carrillo, M.; Klein, T.E. PharmGKB, an Integrated Resource of Pharmacogenomic Knowledge. Curr. Protoc. 2021, 1, e226. [Google Scholar] [CrossRef]
- Wishart, D.S.; Feunang, Y.D.; Guo, A.C.; Lo, E.J.; Marcu, A.; Grant, J.R.; Sajed, T.; Johnson, D.; Li, C.; Sayeeda, Z.; et al. DrugBank 5.0: A Major Update to the DrugBank Database for 2018. Nucleic Acids Res. 2018, 46, D1074–D1082. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, J.; Meinel, T.; Dunkel, M.; Murgueitio, M.S.; Adams, R.; Blasse, C.; Eckert, A.; Preissner, S.; Preissner, R. CancerResource: A comprehensive database of cancer-relevant proteins and compound interactions supported by experimental knowledge. Nucleic Acids Res. 2011, 39, D960–D967. [Google Scholar] [CrossRef] [PubMed]
- Gohlke, B.-O.; Nickel, J.; Otto, R.; Dunkel, M.; Preissner, R. CancerResource—updated database of cancer-relevant proteins, mutations and interacting drugs. Nucleic Acids Res. 2016, 44, D932–D937. [Google Scholar] [CrossRef]
- Küntzer, J.; Maisel, D.; Lenhof, H.-P.; Klostermann, S.; Burtscher, H. The Roche Cancer Genome Database 2.0. BMC Med Genom. 2011, 4, 43. [Google Scholar] [CrossRef]
- Higgins, M.E.; Claremont, M.; Major, J.E.; Sander, C.; Lash, A.E. CancerGenes: A gene selection resource for cancer genome projects. Nucleic Acids Res. 2007, 35 (Suppl. S1), D721–D726. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.-J.; Hu, F.-F.; Xia, M.-X.; Han, L.; Zhang, Q.; Guo, A.-Y. GSCALite: A web server for gene set cancer analysis. Bioinformatics 2018, 34, 3771–3772. [Google Scholar] [CrossRef]
- Hamosh, A.; Amberger, J.S.; Bocchini, C.; Scott, A.F.; Rasmussen, S.A. Online Mendelian Inheritance in Man (OMIM®): Victor McKusick’s magnum opus. Am. J. Med Genet. Part A 2021, 185, 3259–3265. [Google Scholar] [CrossRef]
- Tang, Z.; Li, C.; Kang, B.; Gao, G.; Li, C.; Zhang, Z. GEPIA: A web server for cancer and normal gene expression profiling and interactive analyses. Nucleic Acids Res. 2017, 45, W98–W102. [Google Scholar] [CrossRef]
- Wen, B.; Wang, X.; Zhang, B. PepQuery enables fast, accurate, and convenient proteomic validation of novel genomic alterations. Genome Res. 2019, 29, 485–493. [Google Scholar] [CrossRef]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef]
Figure 1.
Distribution of Molecular Databases by Type (A) Before and (B) After 2015.

Figure 2.
Distribution of Cancer-Related and Non-Cancer-Related Molecular Databases (A) Before and (B) After 2015.
Figure 2.
Distribution of Cancer-Related and Non-Cancer-Related Molecular Databases (A) Before and (B) After 2015.

Figure 3.
Emerging Trends in Database Development Over the Last Eight Years.


{kind=link}
{kind=link}
{kind=link}
Table 1.
Genomic Databases.
| Name | Content/Functionality | Web Service | Downloadable | Analytics | Fairness | Website |
|---|---|---|---|---|---|---|
| The Cancer Genome Atlas Cases = 11,315 | Genome sequencing across 33 tumor types | Yes | Yes | Yes | F, A, I, R | https://www.cancer.gov/ccg/research/genome-sequencing/tcga (accessed on 14 March 2023) |
| OncomiR Cancer Database OMCD Cases = 9500 | Comparative genomic analysis of miRNA data sequencing | Yes | N/A | Yes | F, A, I | http://www.oncomir.org/cgi-bin/dbSearch.cgi (accessed on 14 March 2023) |
| cBio Cancer Genomic Portal | Genomic analysis of cancer-related genes | Yes | Yes | Yes | F, A, I, R | https://www.cbioportal.org/ (accessed on 14 March 2023) |
| International Cancer Genome Consortium (ICGC) Donors ~24,500 | Catalog of mutational abnormalities in major tumor types | Yes | Yes | Yes | F, A, I, R | https://dcc.icgc.org/ (accessed on 14 March 2023) |
| Human Genome Browser at USCS | Genomic data | Yes | Yes | F, A, R | https://genome.ucsc.edu/index.html (accessed on 14 March 2023) | |
| Gene Expression Omnibus Database (GEO) | Gene expression data | Yes | Yes | F, A, R | https://www.ncbi.nlm.nih.gov/geo/ (accessed on 14 March 2023) | |
| Ensembl | Genomic analysis | Yes | Yes | F, A, R | https://www.ensembl.org/index.html (accessed on 14 March 2023) | |
| National Cancer Institute Genomic Commons (GDC) Cases = 22,000 | Storage, analysis, and sharing of clinical data of patients | Yes | Yes | Yes | F, A, I, R | https://portal.gdc.cancer.gov/ (accessed on 14 March 2023) |
| Network of Cancer Genes | Cancer genes, healthy drivers and their properties | Yes | Yes | Yes | F, A, I, R | http://ncg.kcl.ac.uk/index.php (accessed on 14 March 2023) |
| Catalogue of Somatic Mutation in Cancer (COSMIC) | Somatic mutations in human cancer | Yes | Yes | Yes | F, A, I, R | https://cancer.sanger.ac.uk/cosmic (accessed on 14 March 2023) |
| Mutagene | Mutational profiles in 37 cancer types | Yes | Yes | Yes | F, A, I, R | https://www.ncbi.nlm.nih.gov/research/mutagene/ (accessed on 14 March 2023) |
| Progenetix Samples = 142,063 | Cancer copy number abnormalities (CNA) | Yes | Yes | Yes | F, A, I, R | https://progenetix.org/ (accessed on 14 March 2023) |
| MutEx | Stores and explores the relationships between gene expression, somatic mutation,mutational burden and and survival | Yes | Yes | Yes | F, A, I, R | http://www.innovebioinfo.com/Databases/Mutationdb_About.php (accessed on 14 March 2023) |
| Oncomine | Precision oncology through next-generation sequencing | Yes | Yes | Yes | F, A, I, R | https://www.oncomine.com/ (accessed on 14 March 2023) |
| Lung Cancer Explorer (LCE) Entries = 356 | Enables the exploration of lung cancer in various analyses | Yes | Yes | F, A, R | https://lce.biohpc.swmed.edu/lungcancer/imageset_tcga.php (accessed on 14 March 2023) | |
| Prostate Cancer Precision Medicine Multi-Institutional Collaborative Effort PROMISE | Analyzes prostate cancer genes and patient outcomes | Yes | Yes | F, A, I | https://www.prostatecancerpromise.org/research/ (accessed on 14 March 2023) | |
| HCCDb | Information about hepatocellular carcinoma | Yes | Yes | F, A, R | http://lifeome.net/database/hccdb/home.html (accessed on 14 March 2023) |
Table 2.
Proteomic Databases.
| Name | Content/Functionality | Web Service | Downloadable | Analytics | Fairness | Website |
|---|---|---|---|---|---|---|
| Clinical Proteomic Tumor Analysis Consortium (CPTAC) | Application of large-scale proteome and genome analysis | Yes | Yes | Yes | F, A, I, R | https://proteomics.cancer.gov/programs/cptac (accessed on 14 March 2023) |
| String Database | Protein-protein interactions, functional enrichment analysis | Yes | Yes | Yes | F, A, I, R | https://string-db.org/ (accessed on 14 March 2023) |
| Ualcan | Analyzes cancer transcriptome, proteome, and patient survival data | Yes | N/A | Yes | F, A, I | https://ualcan.path.uab.edu/ (accessed on 14 March 2023) |
| CanProVar | Proteomic variations | Yes | Yes | F, A, R | http://119.3.70.71/CanProVar/index.html (accessed on 14 March 2023) | |
| RCSB Protein Data Bank * | Works with UniProt and analyzes protein structures | Yes | Yes | Yes | F, A, I, R | https://www.rcsb.org/ (accessed on 14 March 2023) |
| Universal Protein Resource (UniProt) * | Information about protein structures and interactions | Yes | Yes | Yes | F, A, I, R | https://www.uniprot.org/ (accessed on 14 March 2023) |
| Proteome Discover * | Not free to access (attempted to access on 14 March 2023) | |||||
| Swiss-Prot and TrEMBL * | A part of the UniProt database | Yes | Yes | Yes | F, A, I, R | https://www.uniprot.org/uniprotkb (accessed on 14 March 2023) |
| jPOST * | Post-translational modifications on proteins | Yes | Yes | Yes | F, A, I, R | https://globe.jpostdb.org/ (accessed on 14 March 2023) |
| MatrisomeDB * | Proteomic data from studies of ECM ** | Yes | Yes | F, A, R | https://matrisomedb.org/ (accessed on 14 March 2023) |
* Databases not related to cancer. ** ECM, extracellular matrix.
Table 3.
Lipidomic Databases.
| Databases | Content/Functionality | Web Service | Downloadable | Analytics | Fairness | Website |
|---|---|---|---|---|---|---|
| DBLiPro * | Focuses on human lipid metabolism and provides lipidome-centric analysis | Yes | Yes | Yes | F, A, I, R | http://lipid.cloudna.cn/home (accessed on 14 March 2023) |
| Lipid Maps * | Lipid structures | Yes | Yes | Yes | F, A, I, R | https://www.lipidmaps.org/ (accessed on 14 March 2023) |
* Databases not related to cancer.
Table 4.
Glycomic Databases.
| Name | Content/Functionality | Web Service | Downloadable | Analytics | Fairness | Website |
|---|---|---|---|---|---|---|
| UniCarb-DB * | Carbohydrates characterized by LC-MS | Yes | Yes | Yes | F, A, I, R | https://unicarb-db.expasy.org/about (accessed on 14 March 2023) |
| UniPep * | N-linked glycosites for proteomic analyses | Yes | Yes | F, A, R | https://unipep.systemsbiology.net/ (accessed on 14 March 2023) | |
| GlycoGene (GGDB) * | Information about glycogenes | Yes | Yes | F, A, R | https://www.glycogene.com/ (accessed on 14 March 2023) | |
| Glycome-DB * | A part of the GlyTouCan database | http://www.glycome-db.org/ (accessed on 14 March 2023) | ||||
| GlycoRDF * | Glycomics data | Yes | Yes | F, A, R | https://github.com/glycoinfo/GlycoRDF/wiki (accessed on 14 March 2023) | |
| GRITs Toolbox* | Processing, annotating and archiving of glycomics data with a focus on MS data | Yes | Yes | Yes | F, A, I, R | http://www.grits-toolbox.org/ (accessed on 14 March 2023) |
| GlyTouCan * | Glycan structure repository | Yes | Yes | F, A, R | https://glytoucan.org/ (accessed on 14 March 2023) | |
| The Lectin Frontier Database (LfDB) * | Lectin-standard oligosaccharide interactions | Yes | F, A | https://acgg.asia/lfdb2/ (accessed on 14 March 2023) | ||
| Carbohydrate Structure Database (CSDB) * | Manually curated natural carbohydrate structures, taxonomy, bibliography, NMR, and other data | Yes | Yes, this is done by an external source | F, A, I, R | http://csdb.glycoscience.ru/database/index.html (accessed on 14 March 2023) |
* Databases not related to cancer.
Table 5.
Clinical Trial Databases.
| Name | Content/Functionality | Web Service | Downloadable | Analytics | Fairness | Website |
|---|---|---|---|---|---|---|
| Clinical Genomic Database (GCD) | Genetic information pertaining to patient care | Yes | Yes | F, A, R | https://research.nhgri.nih.gov/CGD/ (accessed on 14 March 2023) | |
| Foundation Medicine Adult-Cancer-Clinical Dataset | Clinical relevance of rare alterations and diseases | Yes | Yes | Yes | F, A, I, R | https://gdc.cancer.gov/about-gdc/contributed-genomic-data-cancer-research/foundation-medicine/foundation-medicine (accessed on 14 March 2023) |
| A Curated Cancer Clinical Outcome Database (C3OD) | Cannot access (14 March 2023) | |||||
| Danish Head and Neck Cancer Database | National guidelines, clinical studies for improved treatment | Yes | Yes | F, A, R | https://www.dahanca.dk/IndexPage (accessed on 14 March 2023) | |
| National Cancer Database (NCDB) | Requires login access | F | https://www.facs.org/quality-programs/cancer-programs/national-cancer-database/ (accessed on 14 March 2023) | |||
| Surveillance Epidemiology and End Results (SEER) * | Information on cancer statistics | Yes | F, A | https://seer.cancer.gov/ (accessed on 14 March 2023) | ||
| ClinVar * | Information about genomic variations and their relationship to human health. | Yes | Yes | F, A, R | https://www.ncbi.nlm.nih.gov/clinvar/ (accessed on 14 March 2023) |
* Databases not related to cancer.
Table 6.
Other Databases.
| Name | Content/Functionality | Web Service | Downloadable | Analytics | Fairness | Website |
|---|---|---|---|---|---|---|
| Database of Epigenetics Modifiers (dbEM) * | Genomic information about epigenetic modifiers from cancerous and normal genomes | Yes | F, A | https://webs.iiitd.edu.in/raghava/dbem/index.php (accessed on 14 March 2023) | ||
| Cancer Research Database (CRDB) | Analyses of other cancer research databases | Yes | F, A | https://www.habdsk.org/crdb (accessed on 14 March 2023) | ||
| PROGgene | Pan Cancer Prognostics | Yes | Yes | F, A, I | http://www.progtools.net/gene/index.php (accessed on 14 March 2023) | |
| Cancer Drug Resistance (CancerDR) | Information about anticancer drugs and their effectiveness against cancer cell lines | Yes | Yes | F, A, R | https://webs.iiitd.edu.in/raghava/cancerdr/index.html (accessed on 14 March 2023) | |
| DriverDBv3 | Cancer driver genes and mutations | Yes | Yes | Yes | F, A, I, R | http://driverdb.tms.cmu.edu.tw/ (accessed on 14 March 2023) |
| LncRNA2Target 2.0 * | Server unreachable (14 March 2023) | |||||
| Lnc2Cancers 3.0 | Server unreachable (14 March 2023) | |||||
| Genotype Expression Project (GTEx) * | Gene expression data, QTLs, and histology images | Yes | Yes | F, A, R | https://www.gtexportal.org/home/ (accessed on 14 March 2023) | |
| Comparative Toxicogenomic Database (CTD) * | Chemical–gene/protein interactions, chemical–disease and gene–disease relationships | Yes | Yes | Yes | F, A, I, R | http://ctdbase.org/ (accessed on 14 March 2023) |
| Therapeutic Target Database (TTD) | Therapeutic protein and nucleic acid targets, the targeted disease, pathway information and the corresponding drugs | Yes | Yes | Yes | F, A, I, R | https://db.idrblab.net/ttd/ (accessed on 14 March 2023) |
| Pharmacogenomics Knowledge Base (PharmGKB) | Knowledge about the impact of genetic variation on drug response | Yes | Yes | F, A, I, R | https://www.pharmgkb.org/ (accessed on 14 March 2023) | |
| DrugBank | Information about drugs, mechanisms of action, and interactions | Yes | Yes | F, A, I, R | https://go.drugbank.com/ (accessed on 14 March 2023) |
* Databases not related to cancer.
Table 7.
Web Servers.
| Name | Content/Functionality | Web Service | Downloadable | Analytics | Fairness | Website |
|---|---|---|---|---|---|---|
| Gene Set Cancer Analysis (GSCALite) | Analysis platform for gene set cancer analysis | Yes | F, A | http://bioinfo.life.hust.edu.cn/web/GSCALite/ (accessed on 14 March 2023) | ||
| Online Mendelian Inheritance in Man (OMIM) | Online catalog of human genes and genetic disorders | Yes | Yes | F, A, R | https://www.omim.org/ (accessed on 14 March 2023) | |
| Gene Expression Profiling Interactive Analysis (GEPIA) * | Analysis of RNA sequencing expression data | Yes | Yes | Yes | F, A, I, R | http://gepia.cancer-pku.cn/ (accessed on 14 March 2023) |
| PepQuery * | Universal targeted peptide search engine | Yes | Yes | F, A, R | http://www.pepquery.org/ (accessed on 14 March 2023) |
* Web servers not related to cancer.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Austin, B.K.; Firooz, A.; Valafar, H.; Blenda, A.V. An Updated Overview of Existing Cancer Databases and Identified Needs. Biology 2023, 12, 1152. https://doi.org/10.3390/biology12081152
AMA Style
Austin BK, Firooz A, Valafar H, Blenda AV. An Updated Overview of Existing Cancer Databases and Identified Needs. Biology. 2023; 12(8):1152. https://doi.org/10.3390/biology12081152
Chicago/Turabian StyleAustin, Brittany K., Ali Firooz, Homayoun Valafar, and Anna V. Blenda. 2023. "An Updated Overview of Existing Cancer Databases and Identified Needs" Biology 12, no. 8: 1152. https://doi.org/10.3390/biology12081152
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.