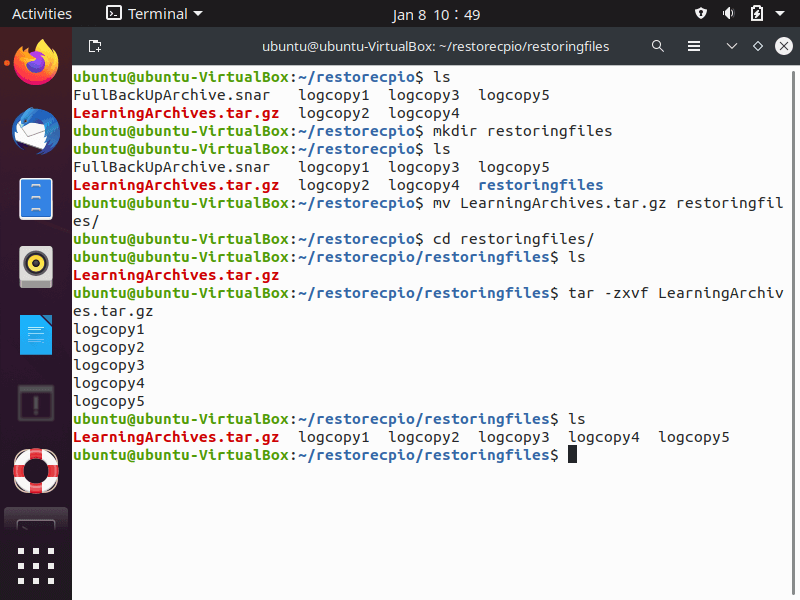
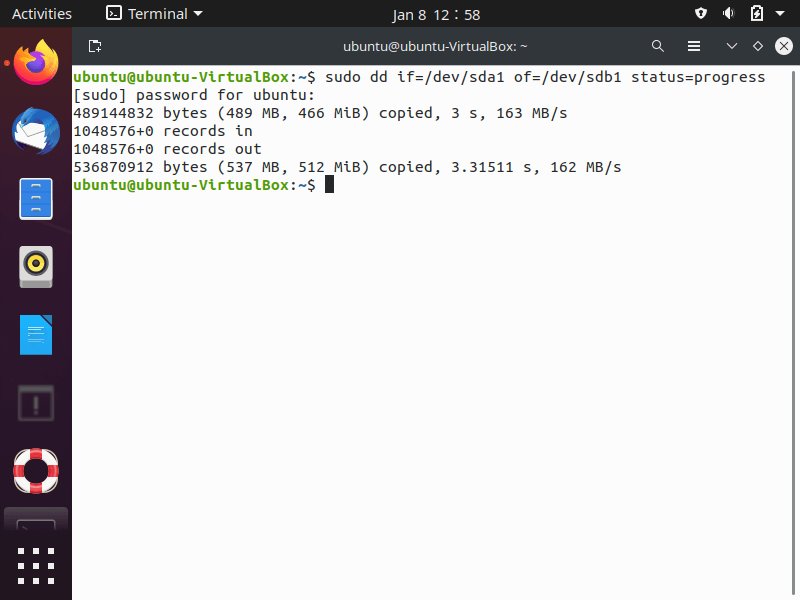
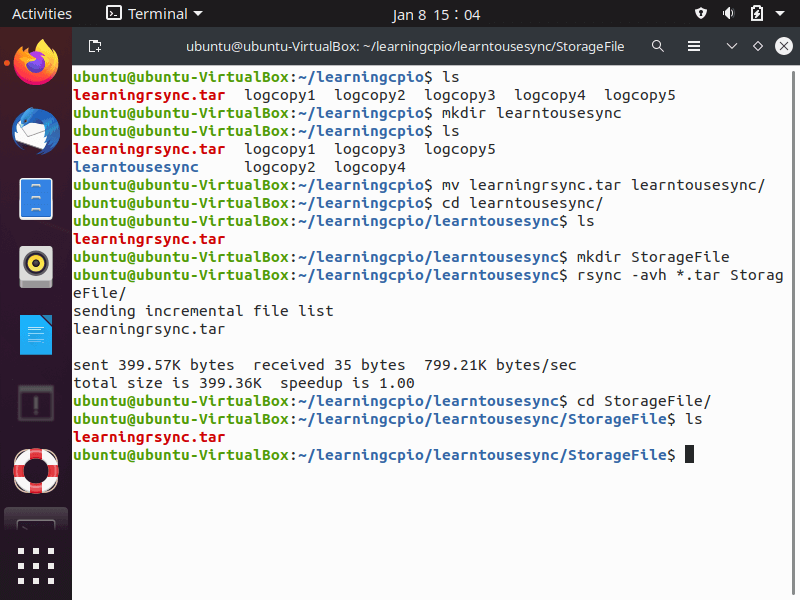
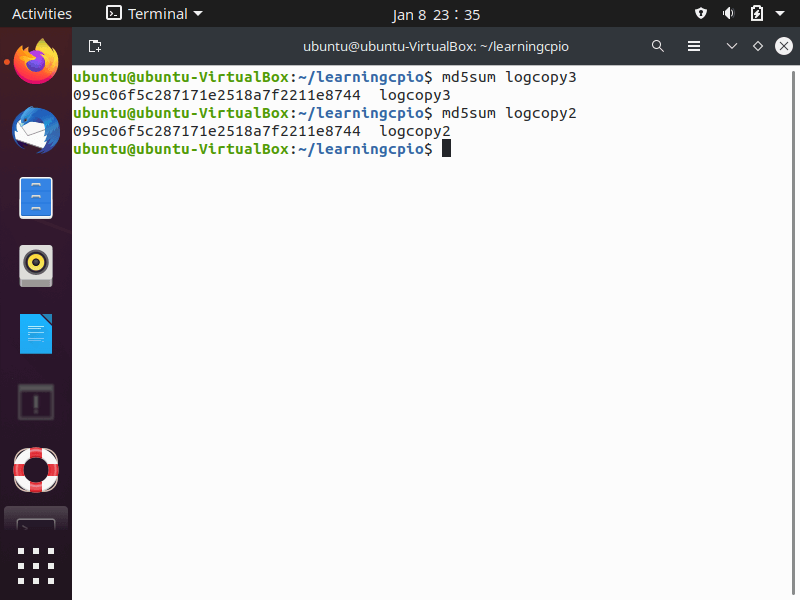


")

When learning how to set up and properly configure a firewall, the first step is knowing the difference between a software vs hardware firewall, which

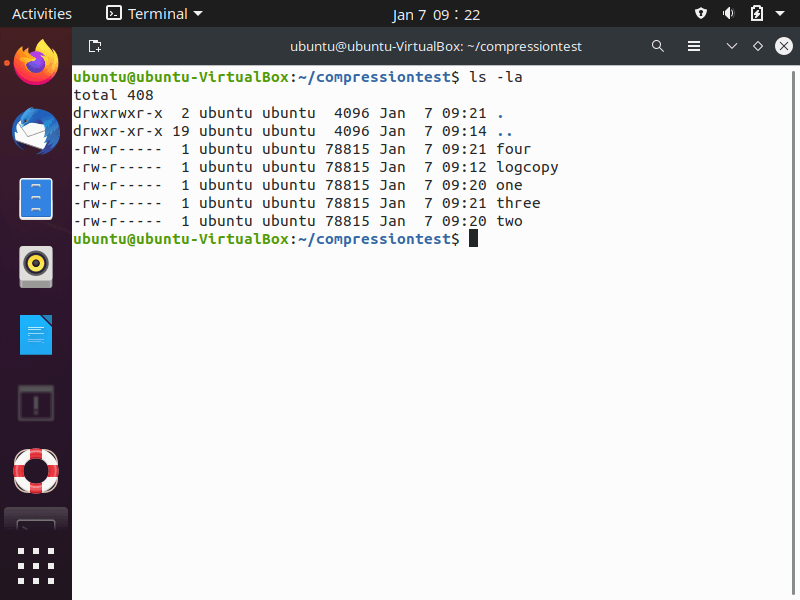
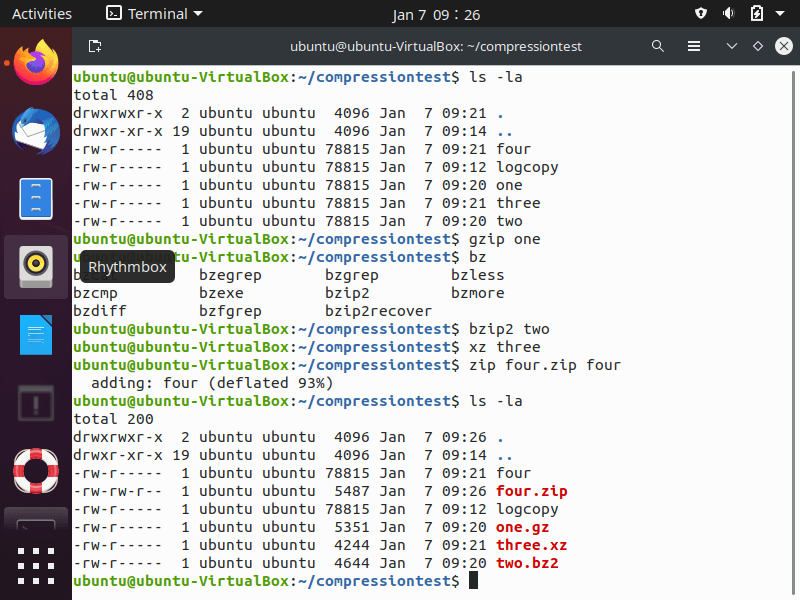
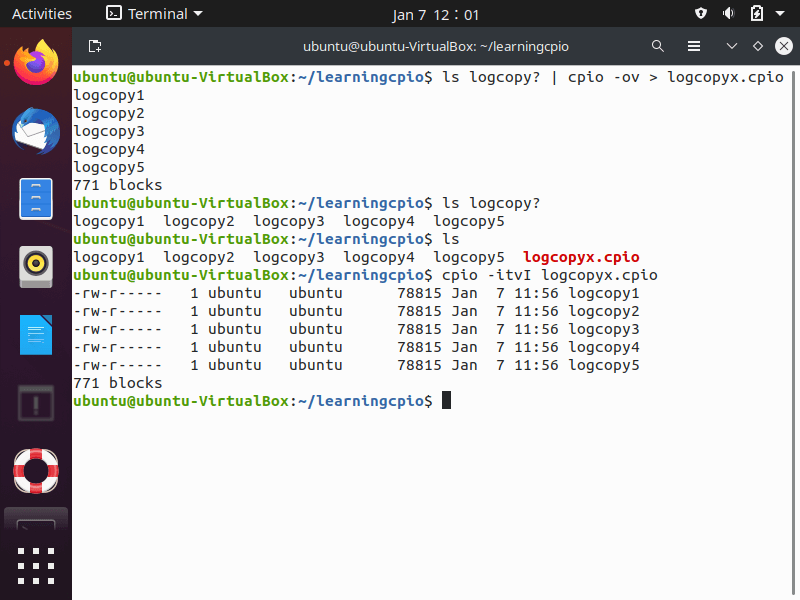
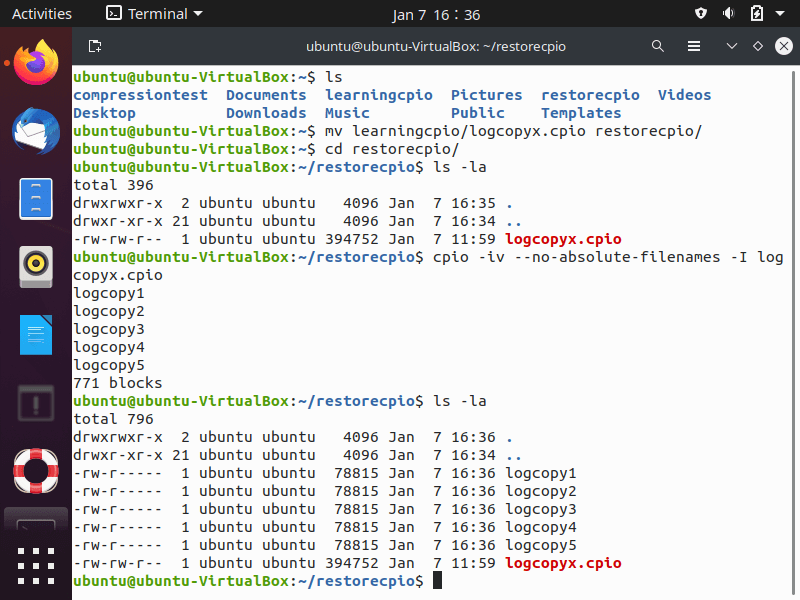
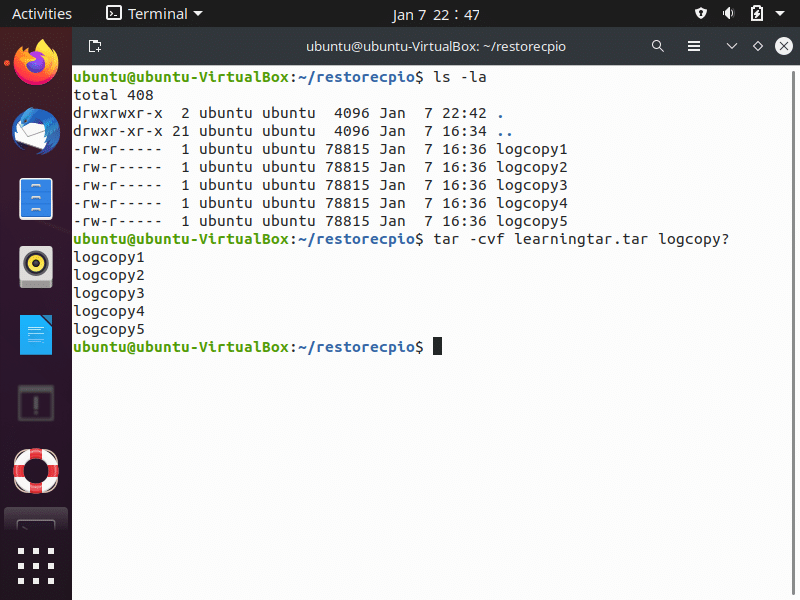
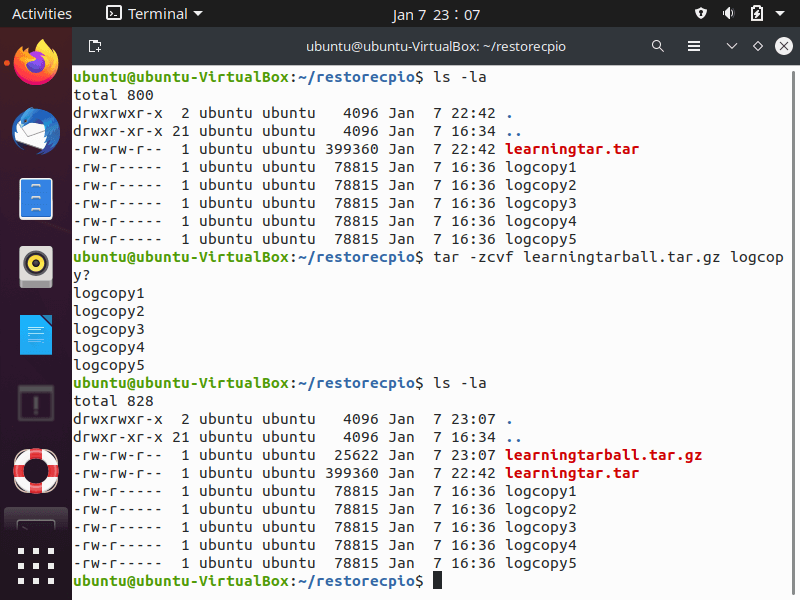
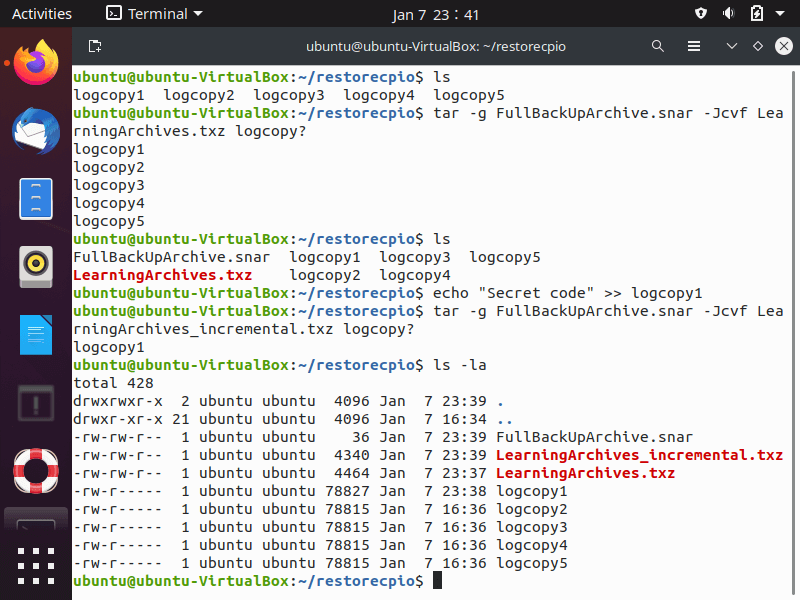
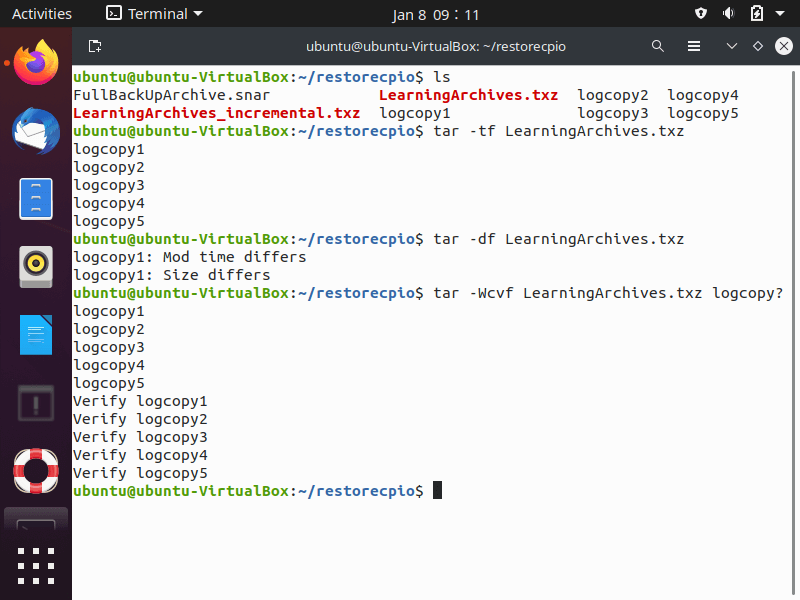
The various parts of the built in Linux logging system records almost all actions (especially errors and security alerts) that take place on your system and provides administrators with a great resource in analyzing system activities. Log files provide evidence of all system activity, including unauthorized access, so these files can provide evidence of hacker intrusions so you need to understand how to these files can be manipulated in order to obfuscate intrusions.

I’m gonna put this out there, managing Linux ownership and permissions for files and directories will be be the bane of your professional existence as

hile you won’t be writing applications as Linux administrator, understanding secure coding best practices as application security bugs are often used to attack networks, so