
医者が診断する際、一つの血液検査の数値だけでは病気の特定は難しい。だが検査項目を増やしていくことで、病気の特定はより確実性を増していく。このように、人はデータを増やすことで予測の精度を上げることができる。同様にAIの予測に不確実性を持たせ、観測点を増やすことでその不確実性を減らす最新の研究の一つを紹介しよう。

ディープラーニングの弱点といわれているものの一つに、「データがなければ予測や変換ができない」点がある。ただ実はこれはほぼ誤解で、直接のデータを必要としない、「メタ学習」という予測モデルの研究が進んでいる(第10回「データがないのに学習可能? 最先端AI『メタ学習』がスゴい」を参照)。
メタ学習は、一言で言うと「学習のやり方を学習する」手法のこと。異なる問題に対して、他で得た知識を再利用する、高次元的なディープラーニングの利用法だ。
今回は、そんなメタ学習の一つである「ConvCNP」(Convolutional Conditional Neural Process)(i)を紹介する。メタ学習をもう少し詳しく説明すると、異なる複数のタスクに共通した知識を獲得し、その知識を新しい未知のタスクに利用するディープラーニングの利用法だ。今回扱うConvCNPは、メタ学習であると同時に、予測の不確実性も扱える注目の研究である。
予測の不確実性は「自信のなさ」の表れ
まず、ConvCNPを扱う前に、予測の不確実性について説明しよう。ディープラーニング以外の機械学習手法の一つである「ガウス過程」は、いくつかの観測点が得られたときの予測事後分布を推定する。ガウス過程による1次元回帰の結果は、下の図1のようになる。ちなみに、1次元回帰とは、1次元の入力データxが与えられたときの出力y=f*(x)となるような真の関数f*を機械学習モデルによって推定するタスクである。

図中の点線は推定したい真の関数f*、実線(青)はガウス過程による予測分布の平均、領域(青)は予測分布の標準偏差を示している。この標準偏差(分散)のことを予測の不確実性と呼ぶことが多く、機械学習モデル(ここではガウス過程のこと)の予測に対する“自信のなさ”を表していると考えてほしい。
ここで注目すべきは、図(a) -> (b) -> (c) -> (d)の順に観測点(黒点、xとyのペア)が増えていくにつれて、ガウス過程による予測分布が真の関数f*(点線)に近づき、特に観測点付近で青い部分(標準偏差)が少なくなっていることである。これは、観測した点の周辺について、機械学習モデルが、予測に対して「自信がある」ということを示している。
ディープラーニングでも予測の不確実性は扱えるか?
ディープラーニングでも、ガウス過程と同じように予測の不確実性を扱えるようにしたのが、今回のConvCNPのベースとなっている「(C)NP」((Conditional)Neural Process)(ii)である。(C)NPのアーキテクチャーを下の図2に示したが、(変分)オートエンコーダと同じように、エンコーダeとデコーダdの2種類のニューラルネットワークで構成されている。
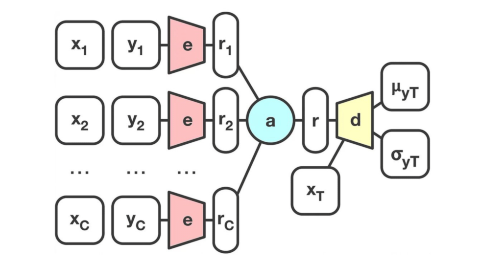
オートエンコーダと異なる点は、エンコーダeへの入力データである。オートエンコーダでは基本的に1つの入力xであるのに対し(yを使わないことが多い)、NPはエンコーダにC個の入出力ペアである観測点{(x1,y1),…,(xC,yC)}を入力する。そして各観測点(xi,yi)におけるエンコーダの出力riを算出した後、平均r(下の式を参照)を算出する。このrは、与えられた複数の観測点の潜在表現ベクトルである。デコーダにrを予測点xtと共に入力することで、観測点を考慮した出力ytの予測が可能となる。
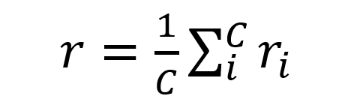

実際にNPに複数の観測点を与えたときの予測結果を図3(a)に載せる。確かにガウス過程(図3(c))と同じように平均と標準偏差を出力していることがわかる。しかしながら、よく見ると(a)は観測点を平均が通っておらず、かつ観測点周辺での標準偏差が小さくなっていないことがわかる。
これは、観測点のベクトル表現およびその利用方法が適切ではないためとされている。そこで、観測点と予測点の類似性を考慮するために、翻訳をはじめとした自然言語処理タスクでよく用いられているAttention機構を利用したAttentive NP(iv)や非巡回有向グラフを構築するFunctional NP(v)などが提案されている。
Attentive NPによる回帰結果を載せてみたのが図3(b)だ。(a)のNPと比較すると、ガウス過程の結果である(c)にだいぶ近づいていることがわかるはずだ。観測点と予測点の類似性を測ることの重要さは伝わったであろうか。
この記事は会員限定(無料)です。








