一文辨析编译型语言与解释型语言异同。

如果嫌太长,可以直接跳到2.1.3看总结。
1基本概念
1.1编程语言分类
根据抽象级别的不同,编程语言可以分为机器语言(二进制机器码)、汇编语言和高级语言。
编程语言的任务:把认为书写的源代码转换成机器码。
1.2高级语言分类
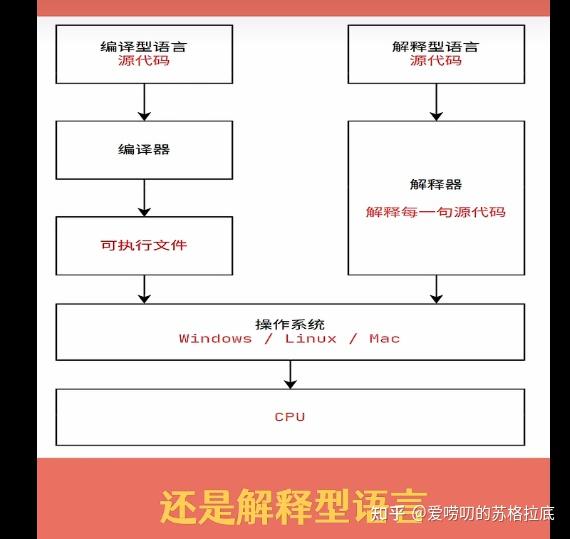
根据构建可执行程序过程的不同,高级语言又可分为编译型语言(如C++);解释型语言,(如Python);及混合型语言(如Java--它先编译成字节码,然后字节码在JVM上解释执行)。
1.3编译型语言与编译器
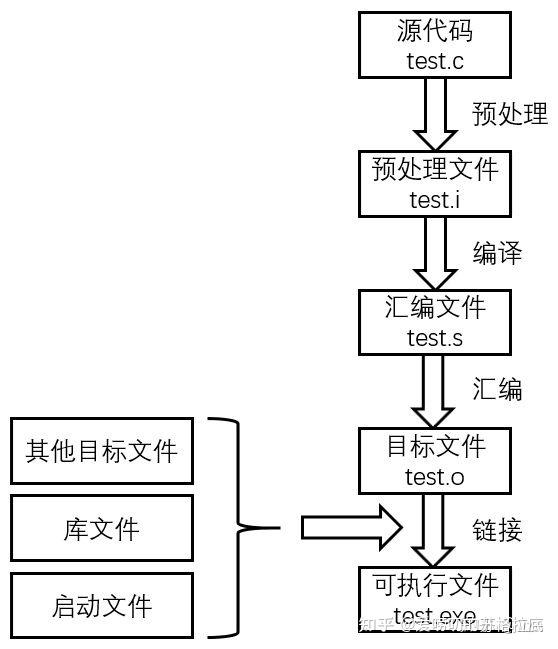
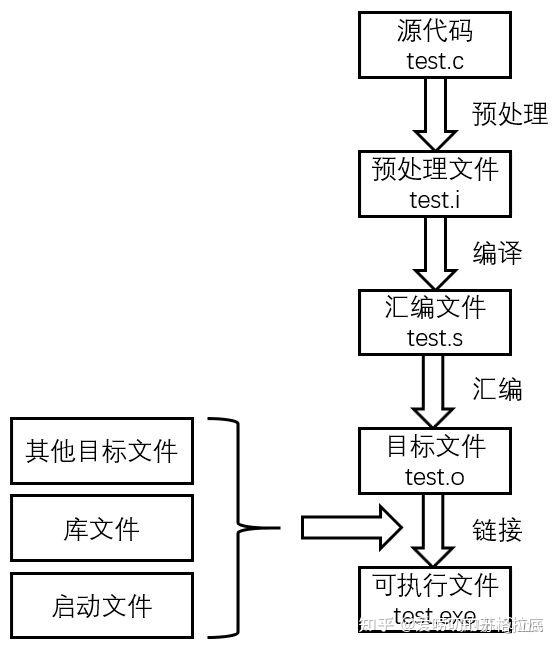
编译型语言:是一种使用编译器一次性地将源代码编译成二进制机器码,然后再执行的高级语言。
编译器(compiler):是一种把高级语言一次性翻译成机器语言的一种软件(也可称之为一个程序)。
编译的过程是一次性的,编译完成后,执行速度很快,一次编译通过的代码,在后续执行中,无需再次编译,所以特点是快。
1.4 解释型语言与解释器
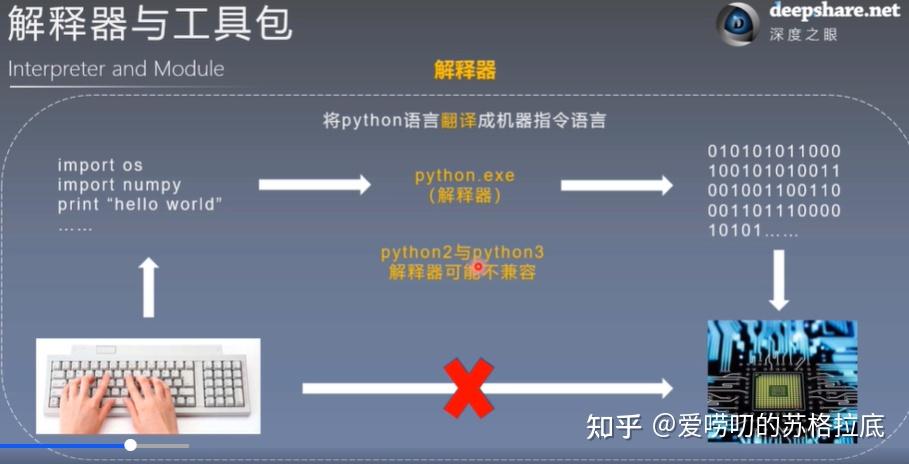
解释型语言:是一种使用解释器一行一行地将源代码翻译成二进制机器码,进行解释执行的语言。
解释器(Interpreter): 是一种把高级语言一行一行地翻译成机器语言的一种软件(也可以说是一个程序)。
这个解释过程是边执行代码边转换成机器语言,需要哪些源代码就转换哪些源代码,所以执行速度相对编译器产生的代码明显比较慢。不会生成可执行程序所以每执行一次,就得解释一次,所以特点是慢。

2关系辨析
2.1编译型语言与解释型语言关系
两者联系的实质:任务是相同的。
两者区别的实质:翻译器和解释器的不同。
2.1.1联系
2.1.1.1语言类型相同
两者都属于高级语言
2.1.1.2输入与输出相同
输入都是源代码,输出都是二进制机器码。
2.1.2区别
2.1.2.1翻译工具不同
- 编译型语言用的是编译器,解释型语言用的是解释器。
2.1.2.2转换成机器码的过程不同
这是由工具原因造成的,编译器是一次性进行源代码到机器码的转换过程,解释器是逐行进行源代码到机器码的转换过程。
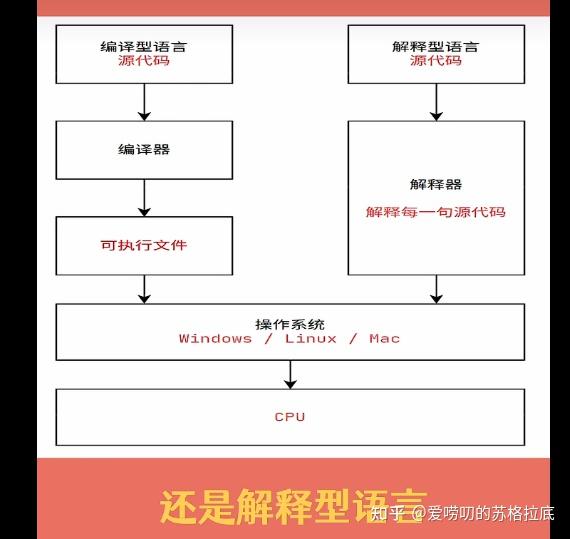
2.1.2.3执行速度不同
编译型语言:开发完成以后需要将所有的源代码都转换成可执行程序,比如 Windows 下的.exe文件,可执行程序里面包含的就是机器码。只要我们拥有可执行程序,就可以随时运行,不用再重新编译了,也就是“一次编译,无限次运行”。在运行的时候,我们只需要编译生成的可执行程序,不再需要源代码和编译器了,所以说编译型语言可以脱离开发环境运行。
解释型语言:每次执行程序都需要一边转换一边执行,用到哪些源代码就将哪些源代码转换成机器码,用不到的不进行任何处理。每次执行程序时可能使用不同的功能,这个时候需要转换的源代码也不一样。
因为每次执行程序都需要重新转换源代码,所以解释型语言的执行效率天生就低于编译型语言,甚至存在数量级的差距。计算机的一些底层功能,或者关键算法,一般都使用 C/C++ 实现,只有在应用层面(比如网站开发、批处理、小工具等)才会使用解释型语言。
2.1.2.4跨平台性能不同
解释器可跨平台:因为采用解释器的编程语言考虑了跨系统(平台)移植要求。代码既可以在Windows环境下运行,也可以在Linx环境下运行,甚至可以在不同的智能手机平台上运行,无须反复调整代码或进行再编译,这就是解释方式语言的优势。
编译器不能跨平台:采用编译器的编程语言只在一种操作系统下运行正常,在另外一种操作系统下可能无法运行。
2.1.2.5保密性不同
当我们说“下载一个程序(软件)”时,不同类型的语言有不同的含义。
对于编译型语言:我们下载到的是可执行文件,源代码被作者保留,所以编译型语言的程序一般是闭源的。
对于解释型语言:我们下载到的是所有的源代码,因为作者不给源代码就没法运行,所以解释型语言的程序一般是开源的。
2.1.3总结
| 异同 | 项目 | 编译型语言 | 解释型语言 |
|---|---|---|---|
| 同 | 语言类型 | 高级语言 | |
| 输入输出 | 输入源代码,输出机器码 | ||
| 异 | 翻译工具 | 编译器 | 解释器 |
| 转换过程 | 代码一次翻译 | 代码逐行解释 | |
| 执行速度 | 快 | 慢 | |
| 跨平台性能 | 差 | 好 | |
| 保密性能 | 好 | 差 |
3疑问解答
3.1为什么解释型语言能跨平台?
首先,跨平台是指源代码跨平台,而不是解释器跨平台。解释器用来将源代码转换成机器码,它是一个可执行程序,是绝对不能跨平台的。
因此,官方针对不同的平台开发不同的解释器,这些解释器能够遵守同样的语法,识别同样的函数,完成同样的功能,只有这样,同样的代码在不同平台的执行结果才是相同的。
所以,解释型语言之所以能够跨平台,是因为有了解释器这个中间层。在不同的平台下,解释器会将相同的源代码转换成不同的机器码,解释器帮助我们屏蔽了不同平台之间的差异。
3.2为什么编译型语言不能跨平台
- 原因一:可执行程序不能跨平台
不同操作系统对可执行文件的内部结构有着截然不同的要求,彼此之间不能兼容。不能跨平台是天经地义,能跨平台反而才是奇葩。
如不能将 Windows 下的可执行程序拿到 Linux 下使用,也不能将 Linux 下的可执行程序拿到 Mac OS 下使用。
另外,相同操作系统的不同版本之间也不一定兼容,比如不能将 x64 程序(Windows 64 位程序)拿到 x86 平台(Windows 32 位平台)下运行。但是反之一般可行,因为 64 位 Windows 对 32 位程序作了很好的兼容性处理。 - 原因二:源代码不能跨平台
不同平台支持的函数、类型、变量等都可能不同,基于某个平台编写的源代码一般不能拿到另一个平台下编译。我们以C语言为例来说明。
【实例1】在C语言中要想让程序暂停可以使用“睡眠”函数,在 Windows 平台下该函数是 Sleep(),在 Linux 平台下该函数是 sleep(),首字母大小写不同。其次,Sleep() 的参数是毫秒,sleep() 的参数是秒,单位也不一样。
以上两个原因导致使用暂停功能的C语言程序不能跨平台,除非在代码层面做出兼容性处理,非常麻烦。
【实例2】虽然不同平台的C语言都支持 long 类型,但是不同平台的 long 的长度却不同,如Windows 64 位平台下的 long 占用 4 个字节,Linux 64 位平台下的 long 占用 8 个字节。
我们在 Linux 64 位平台下编写代码时,将 0x2f1e4ad23 赋值给 long 类型的变量是完全没有问题的,但是这样的赋值在 Windows 平台下就会导致数值溢出,让程序产生错误的运行结果。让人苦恼的,这样的错误一般不容易察觉,因为编译器不会报错,我们也记不住不同类型的取值范围。
4参考文献与说明
4.1参考文献
- 作者:懂法的程序猿
链接:https://www.zhihu.com/question/420516398/answer/2395461484 - 来源:C程序的编译过程 - ZhengN的文章 - 知乎https://zhuanlan.zhihu.com/p/106777805
- 参考:https://www.bilibili.com/video/BV1EF41147nh?spm_id_from=333.337.search-card.all.click&vd_source=368f2502092f2d16a857de20ea61fd86
- 图2 来自深度之眼
- Python编程 从零基础到项目实战 刘瑜
4.2说明
文章纯属学习记录整理,如有侵权,请联系删除。