
一键生成线性回归统计报告!批量单因素分析及先单后多三线表直出!

线性回归是一种常用的统计分析方法,用于建立自变量和因变量之间的线性关系模型。当知道两个变量间存在相关关系时,我们时常想进一步去探讨是否可以通过其中一个变量的数值定量的去预测另外一个变量的数值。
经典案例:父亲身高与儿子身高存在相关关系,是否可以通过父亲身高预测儿子的身高?
这类问题在统计学上常采用线性回归的方法来解决。
线性回归分析报告的统计模块主要包括3部分内容:统计描述、相关性分析和单因素+多因素回归。
实际中,许多人习惯性使用SPSS开展线性回归,但是SPSS无法进行批量单因素分析,还需要手动绘制三线表,费时又费力。而R语言虽然可以解决以上难点但具有一定的门槛,因此,这里结合一篇文献与实操案例为大家介绍一个智能在线免费统计分析平台——风暴统计。


本文主要内容包括:
一、案例文献解读
二、实操案例介绍
三、风暴统计智能在线免费平台复现
一、案例文献解读
通过中国人民解放军空军医大学第一附属医院的一篇核心期刊的文章,为大家简述一下线性回归分析文章的统计分析框架。


1、变量说明
这是一篇现况研究,探究缺血性脑卒中多病共存患者的出院准备度水平及其影响因素,共收集256例缺血性脑卒中多病共存住院患者为研究对象,下表为可能影响患者出院准备度的一般资料。
| 变量名 | 变量类型 | 变量说明 |
| 性别 | 2分类 | 1=男;2=女 |
| 婚姻状况 | 2分类 | 1=已婚;2=单身 |
| 户口类型 | 2分类 | 1=农村;2=城市 |
| 首发脑卒中 | 2分类 | 1=是;2=否 |
| 吸烟 | 2分类 | 1=是;2=否 |
| 独居 | 2分类 | 1=是;2=否 |
| 年龄(岁) | 多分类 | 1=“55~64”;2=“65~74”;3=“≥75” |
| 文化程度 | 多分类 | 小学及以下(D1=1,D2=0,D3=0,D4=0); 初中(D1=0,D2=0,D3=0, D4=0); 高中(D1=0,D2=1,D3=0,D4=0); 大专(D1=0,D2=0, D3=1,D4=0); 本科及以上(D1=0,D2=0,D3=0,D4=1) |
| 合并症数量 | 多分类 | 1=“1~2”;2=“3~4”;3=“>4” |
| 就业状况 | 多分类 | 在职(F1=1,F2=0); 自由职业者(F1=0,F2=1); 退休(F1=0,F2=0) |
| 家庭人均月收入(元) | 多分类 | 1=“<3 000”;2=“3 000~6 000”;3=“>6 000” |
| 医疗支付方式 | 多分类 | 自费(H1=1,H2=0,H3=0); 城乡居民医疗保险(H1=0,H2=1, H3=0); 居民医疗保险(H1=0,H2=0,H3=1); 职工医疗保险 (H1=0,H2=0,H3=0) |
| BMI(kg/m2) | 多分类 | <18.5(G1=1,G2=0,G3=0); 18.5~23.9(G0=0,G2=0,G3=0); 24~27.9(G1=0,G2=1,G3=0); ≥28(G1=0,G2=0,G3=1) |
2、统计方法
作者究使用SPSS 24.0软件进行数据的录入与分析。定量数据使用均数、标准差描述,不同特征的出院准备度得分采用中位数和四分位间距进行描述。 采用Pearson相关分析检验出院准备度与出院指导质量的相关性;采用非参数检验法(Mann-Whitney U检验、Kruskal-Wallis检验)进行单因素分析;多因素分析采用多重线性回归法;检验水准为α=0.05。
3、统计结果
3.1统计描述+单因素分析
这篇文章的统计分析框架就是比较典型的线性回归文章的分析框架。由于结局是定量数据,无分组变量,表一进行了变量的描述统计与单因素分析。单因素分析结果显示,不同年龄、合并症数量的患者出院准备度得分差异具有统计学意义(P<0.05)。进一步两两比较,年龄≥75岁组与55~64岁组之间有统计学差异(P=0.036);合并症数量为1~2种组与3~4种组之间存在统计学差异(P=0.001)。


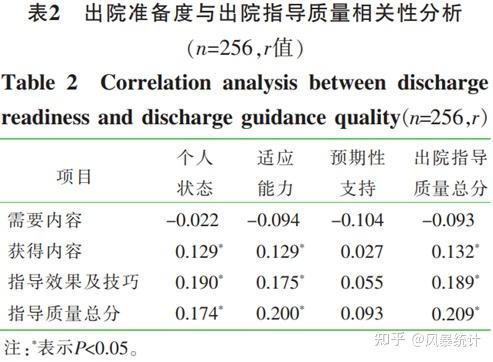
3.2相关性分析
本研究出院指导质量得分与出院准备度得分呈正相关(r=0.209,P=0.001)。

3.3多重线性回归分析
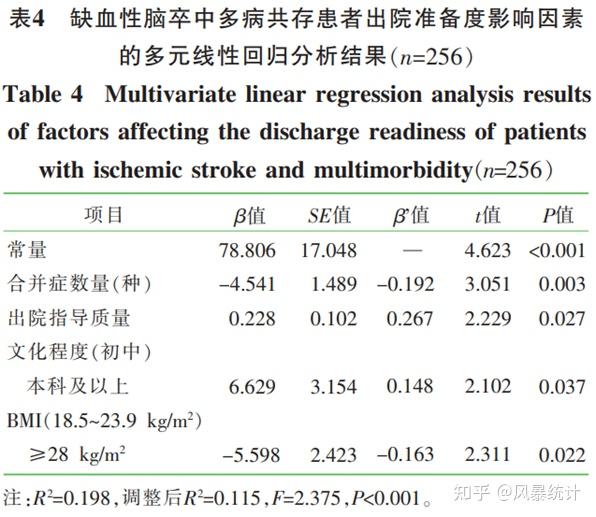
考虑单因素分析纳入的变量过少,本研究结合临床专业知识将所有相关变量作为自变量,以出院准备度总分作为因变量进行线性回归分析。多重线性回归分析的结果显示合并症数量、文化程度、出院指导质量总分及BMI值最终进入了回归方程,对模型的解释力为11.5%。

二、实操案例讲解
接着我们将结合实操数据集对上述线性回归分析文章的统计框架进行复现。
数据集来源于R自带MASS数据集birthwt,这是一份于1986年在在马萨诸塞州收集的与婴儿出生体重低相关的危险因素的数据。以定量数据出生体重(bwt)作为结局变量,探讨下列因素对出生体重的影响。可能的影响因素如下:
| 变量名 | 变量说明 | 变量属性 | 变量值 |
| bwt | 出生体重(克) | 定量数据 | |
| age | 孕妇年龄(年) | 定量数据 | |
| lwt | 孕妇在末次月经期间的体重(磅) | 定量数据 | |
| race | 母亲种族 | 定性数据 | White=白人,black=黑人,other=其他 |
| smoke | 怀孕期间吸烟状况 | 定性数据 | False=不吸烟,True=吸烟 |
| ptd | 既往早产次数 | 定性数据 | False=无,True=有 |
| ht | 高血压病史 | 定性数据 | False=无,True=有 |
| ui | 应激事件 | 定性数据 | False=无,True=有 |
| ftv | 孕早期的就诊次数 | 定性数据 | 0次,1次,2+次 |
下面将结合本数据分别通过风暴统计智能在线免费平台与R语言软件来进行统计框架复现,方便大家对两种方法的特点有更加直观的认识!
三、风暴统计智能在线免费平台复现
1、统计描述
线性回归定量结局的差异性分析无论在R语言还是SPSS软件,都无法做到批量差异性分析,而风暴统计平台通过编写代码实现了定量资料的批量差异分析!
(1)【风暴统计】——【风暴智能统计】——【线性回归分析】


(2)【数据导入整理】——【Browse数据导入】(目前支持10 M 以内数据)


(3)【数据整理转换】
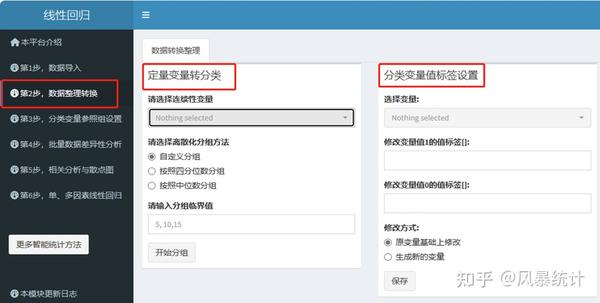

①【定量变量转分类】
例:将变量ptl以1为界,分为两组:一组“≥1”,一组“<1”。在第【定量变量转分类】中选择要转换的定量变量ptl,再选择分组的方法,我们选择自定义分组,分组临界值输入“1”。


点击“开始分组”会生成新变量“ptl_group”。同样,选择“按照四分位数分组”和“按照中位数分组”也会生成新的分组变量。


注意:按照临界值分组,分组区间为左闭右合,如ptl变量以1为临界值,分为[0,1)和[1,+∞)。若分组临界值有多个,中间以英文符号“,”隔开即可。
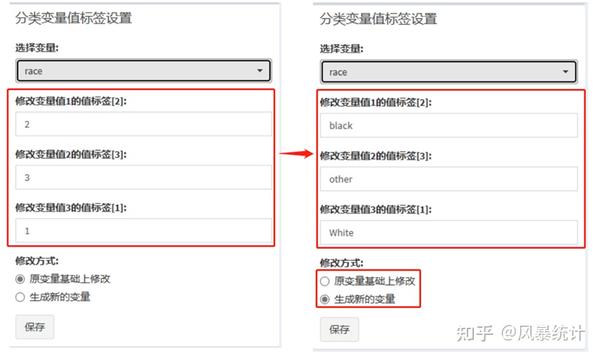
②【分类变量值标签设置】
例:将变量race变量值打标签,“1=white”,“2=black”,“3=other”。可以在原变量基础上修改,也可生成新的变量,切记一定要点“保存”!

③【产生新变量】
例:将变量bwt单位有g转换为斤,即运用公式“Bwt==bwt*0.001*2”
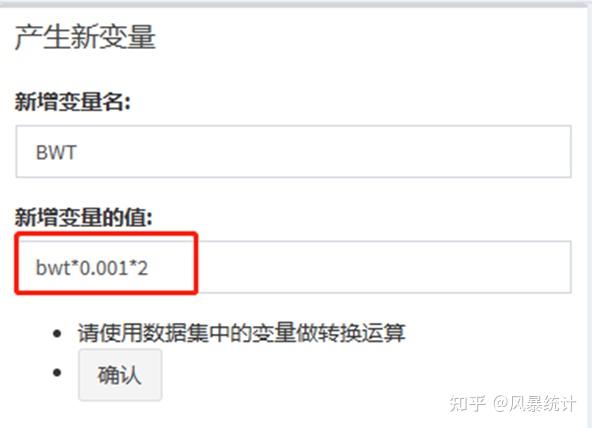

点击确认,产生新变量“BWT”
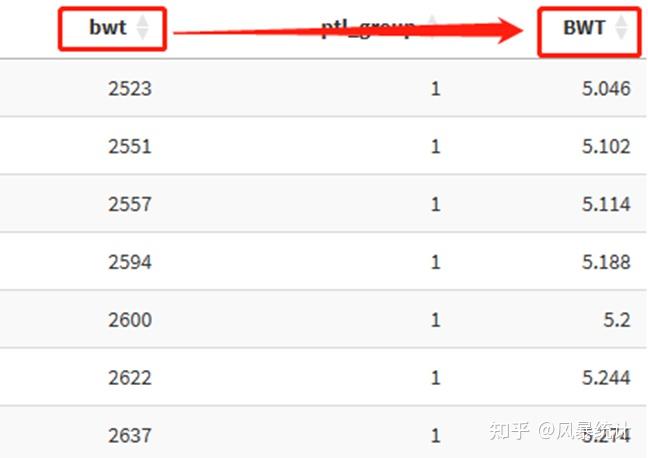

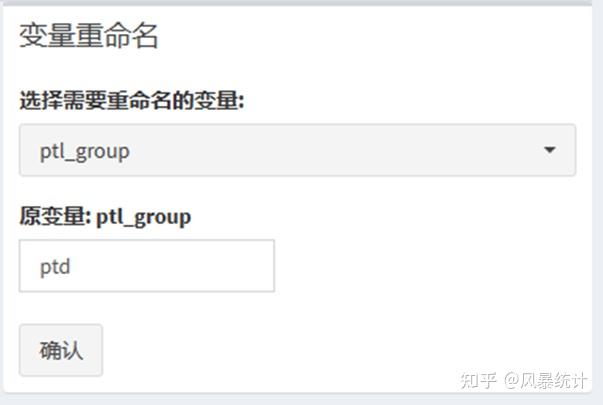
④【变量重命名】
选择原变量,并在下方输入重命名名称即可。

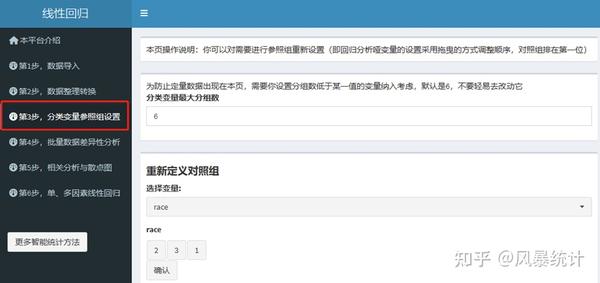
(4)【分类变量参照组设置】
设置对照组,对变量race中“1=white”设置为对照组。

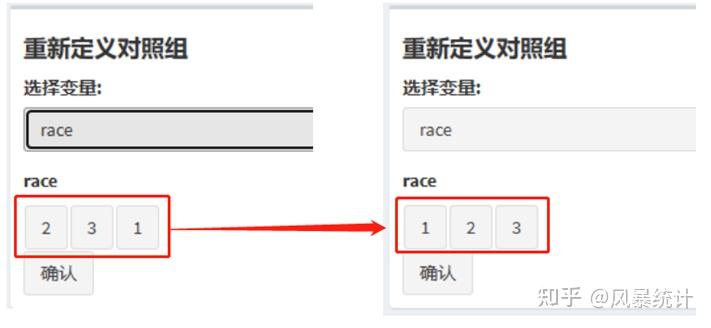
拖动“1”,“2”,“3”的小方块可以调换位置。排序第一位的为对照组。

(5)点击【批量数据差异性分析】。选择定量检验变量(即线性回归结局变量),可指定变量为正态或偏态,也可以通过网站检验;选择分类变量进行分组比较。


结果会自动呈现在右边,并在“statistic”注明了检验统计量。
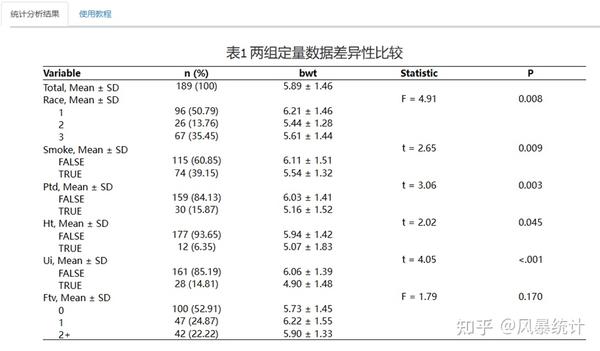

【导出统计分析报告】——结果直接呈现三线表形式,包括表名与表头一步到位。如需细节打磨,word形式方便进行编辑!
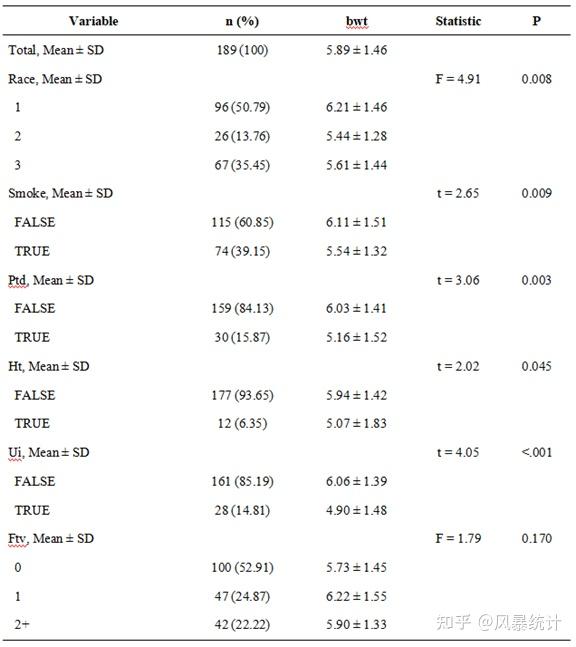

风暴统计平台与R语言的统计分析结果一致,且对于定量结局的数据来说,风暴统计平台可以进行批量差异性分析,经过对比,结果与SPSS完全相同。风暴统计平台更简便,更精确!
2.相关性分析
(1)点击【相关分析与散点图】。
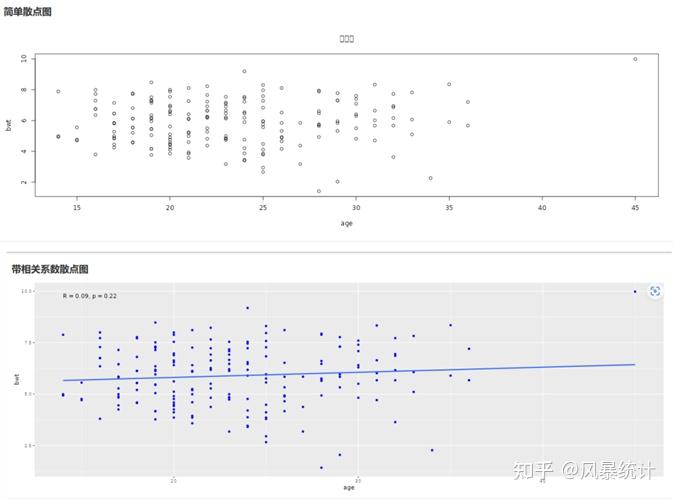
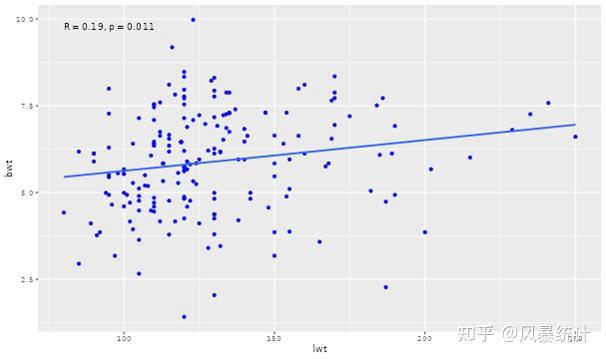
(1)选择x轴变量和y轴变量,散点图会在右边显示,R值和P值在图片上显示,右键可保存图片


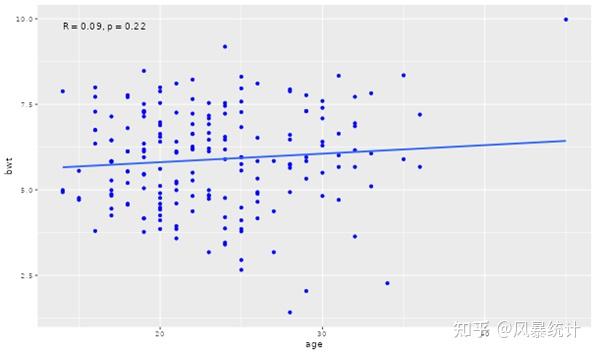

3、单因素及多因素线性回归
(1)点击【单、多因素线性回归】


(2)并选择因变量和自变量,右侧直接显示单因素、多因素线性回归及单因素+多因素回归结果
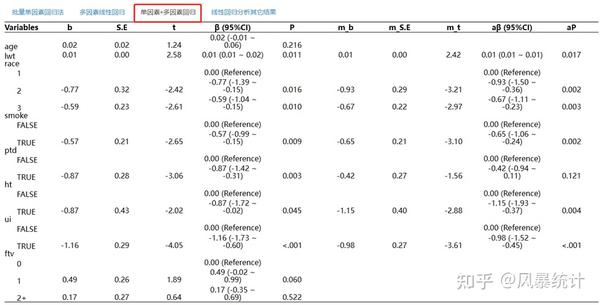

多因素线性回归变量纳入可以根据差异性分析<0.05纳入,也可以根据单因素线性回归分析<0.05纳入,结果会稍有差异。
(3)导出word版三线表结果
风暴统计结果展示如下,直接生成word版三线表,高效快速!
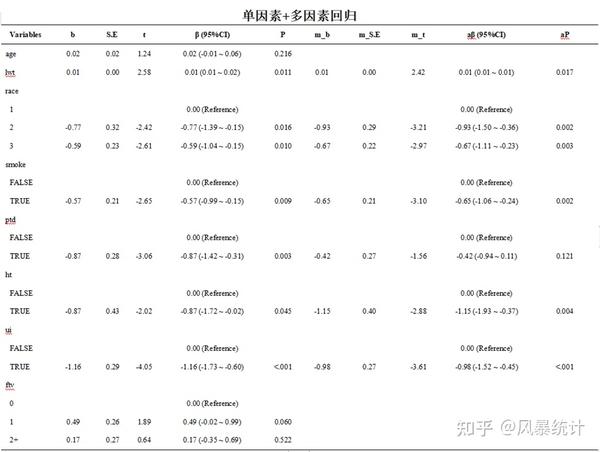

以上结果经检验,风暴统计平台与R语言线性回归结果完全一致,并且风暴统计平台操作更简单,且p值单独分列,结果更加的清晰明了!
通过对线性回归分析文章的统计分析框架的复现,基于以上结果对比,可以得出,风暴统计平台的分析结果十分规范可靠,这也是由于平台的构建依托于R代码进行分析。同时操作过程也十分的简便,相较于R语言的使用门槛那真的是低太多了。结果直接一键输出word三线表,方便又快捷,大家进行统计分析时不妨一试!