
Abstract
Deprived settlements, usually referred to as slums, are often located in hazardous areas. However, there have been very few studies to examine this notion. In this study, we leverage the advancements in open geospatial data, earth observation (EO), and machine learning to create a multi-hazard susceptibility index and a transferrable disaster risk approach to be adapted in low- and middle-income country (LMIC) cities, with low-cost methods. Specifically, we identify multi-hazards in Nairobi's selected case study area and construct a susceptibility index. Then, we test the predictability of deprived settlements using the multi-hazard susceptibility index in comparison with EO texture-based methods. Lastly, we survey 100 households in two deprived settlements (typical and atypical slums) in Nairobi and use the survey outcomes to validate the multi-hazard susceptibility index. To test the assumption that deprived areas are dominantly located in areas with higher susceptibility to multiple hazards, we contrast morphologically identified deprived settlements with non-deprived settlements. We find that deprived settlements are generally more exposed to hazards. However, there are variations between central and peripheral settlements. In testing the predictability of deprivation using multi-hazards, the multi-hazard-based model performs better for deprived settlements than for other classes. In contrast, the texture-based model is better at classifying all types of morphological settlements. Lastly, by contrasting the survey outcomes to the household interviews, we conclude that proxies used for the multi-hazard susceptibility index adequately capture the hazards. However, more localized proxies can be used to improve the index performance.
Similar content being viewed by others

1 Introduction
Globally, disasters lead to massive economic losses, displacements, injuries, and fatalities (Dilley et al. 2005). These concentrate in cities and particularly cities located in low- and middle-income Countries (LMICs) (Aryal et al. 2021). Commonly, studies focus on a specific hazard and analyze disaster risks (e.g., Kamruzzaman et al. 2021; Müller et al. 2020). However, most cities are affected by multiple hazards (Dilley et al. 2005). Data to support multiple hazard analyses in LMIC cities are often not readily available, limiting the spatial knowledge on intracity patterns of multiple hazard susceptibility (Pourghasemi et al. 2020) and its relation with urban inequality (deprivation)(Abascal et al. 2022).
Disasters are commonly caused by man-made, natural, and technological hazards causing damage and losses (Gallina et al., 2016). Notably, urban areas are hot spots for anthropogenic activities that have resulted in increased hazards (IPCC 2022; Satterthwaite & Bartlett 2017). For instance: increased impervious surfaces (Seto et al. 2010), destruction of natural ecosystems (Seto & Shepherd 2009), and increased heat-trapping greenhouse gases (GHG) that have significantly contributed to global warming (Revi et al. 2014). Also, many cities globally are located in hazard-prone regions (IPCC 2022). Additionally, more than 50% of the world's population resides in urban areas (United Nations 2018). Therefore, hazards represent a significant issue of risk for humanity.
Further, inequality (i.e., the economic polarization between the wealthy and the poor) characterizes many LMIC cities, and urban poverty has been spatially manifested as slum settlements (non-exclusively) (Baker 2008; UN-Habitat 2016). One in eight urban dwellers live in a slum (UN-Habitat 2016), and in Sub-Saharan Africa (SSA), 59% of the urban population are slum residents (UN-Habitat 2016). Typically, slum settlements are characterized by their poor environmental living conditions. Physically, slums are characterized by structures built without (if any) regard for building codes and are of poor material with low structural integrity (Lilford et al. 2019). Failing to provide the inhabitants with adequate protection from harsh climatic conditions. Spatially, slum settlements are contiguous, overcrowded with irregular patterns, and lacking adequate infrastructure (Thomson et al. 2020). They are located on derelict land and low environmental quality areas like near highways and industrial areas (Ramin 2009; Wekesa et al. 2011). Often, they are deprived of green spaces (vegetation) to act as natural sinks for pollutants and excess precipitation and thus have low air quality and are prone to flooding (Abascal et al. 2022; Merodio Gómez et al. 2021). Geographically, these settlements are commonly situated in hazardous locations (Müller et al. 2020) such as flood plains and steep hills prone to floods and landslides, respectively. These characteristics default the urban poor to the forefront of disaster risks (Revi et al. 2014).
Commonly, cities are affected by more than one hazard, and the frequency of disasters is reportedly increasing (Dilley et al. 2005; Tiepolo et al. 2019; van Westen & Greiving 2017). However, studies on multiple hazards in cities have been limited as research usually focuses on single hazards (e.g., Wang et al. 2019a, b, c). In LMIC's especially, data to support multiple hazard studies are scarce and often limited to small areas such as neighborhoods (e.g., Mulligan et al. 2017). However, advancements in open geospatial data (i.e., modelled/processed data, commonly available in vector or raster format – in Fig. 1 called GIS data), earth observation (EO) data (e.g., imagery that can be downloaded for analysis), and machine learning (i.e., self-learning methods) can help to address these limitations. As a framework for analysing multi-hazards, indices have proven robust in combing heterogeneous spatial data (e.g., Dilley et al. 2005; Greiving et al. 2006). Also, several studies showed the potential to combine EO data and geospatial data using innovations in machine learning (e.g., Kuffer et al. 2016; Ajami et al. 2019; Müller et al. 2020). Therefore, this study analyzes the relationship between hazards and deprivation using a multi-hazard susceptibility approach. The city of Nairobi was selected as a case study to analyze this relationship, because of data availability. Furthermore, like other studies (e.g., Kuffer et al. 2020, 2018; Thomson et al. 2020), we adopt the term deprived areas (and its variants) to refer to slums.

Relationship between hazard and deprivation analyzed with geospatial data (called GIS data) and earth observation (EO) data
2 Methodology
To analyze the relationship between hazards and deprivation, we contextualize the aforementioned environmental conditions of deprived areas using the generic slum ontological (GSO) framework developed by Kohli et al. (2012) (Fig. 2). Utilizing the hierarchical grouping nature of the framework, we identify three spatial levels (environs-city, settlement, and object-household level) for our analysis.

Generic Slum Ontological (GSO) framework (Kohli et al. 2012)
At the city level, we use open geospatial and EO data (available in open archives) to construct a multi-hazard susceptibility index (Fig. 3). The use of open data will support the transferability and scalability of the proposed index beyond the case study area. Thus a multi-hazard susceptibility index is constructed, using relevant local indicators and open geospatial and EO data. This selection is informed by an extensive literature review and key informant interviews. By consulting the experts, we gain insights into the hazards present in the study area and thus refine the theoretical multi-hazard susceptibility index. We conduct extensive literature and database search to identify geo-data to construct the index.

Overview of the methodology
Secondly, we test whether deprived settlements are more commonly located in hazardous areas in cities. Thus, building on the assumption of a direct relationship between hazards and deprivation. We perform canonical discriminant analysis (CDA), which is a multi-variate technique to analyze the relationship between class/group/categorical variables and outcome/predictor variables, by plotting cases on a feature space and forming decision boundaries by class (Field 2018; Zhao & Maclean 2000)(Lobo 1997).
Next, we use machine learning methods to analyze whether the multi-hazard susceptibility index can predict deprivation. We use the multi-hazard susceptibility index developed in the first step to perform a land-use classification of the different types of residential settlements (and other identified land uses) in our study area. In parallel, we also run an experiment using a common land-use classification method, i.e., using textural features as a control test. Lastly, we conduct household interviews to analyze the inter-settlement hazard dispersal and household-level exposure to hazards. The household survey findings are contrasted with the outcome of the multi-hazard susceptibility index.
2.1 Case study – Nairobi, Kenya
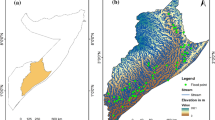
To define our area of interest (AOI), we select Nairobi county’s (which is also the city’s) political-administrative boundary (Fig. 4) obtained from GADM. Nairobi, the capital city of Kenya, has a population of 4.4 million people (Kenya National Bureau of Statistics 2018). The city has a high level of inequality in terms of housing, infrastructure, services, etc., dating back to the pre-independence racial zoning and rigid building standards (Pamoja Trust 2009) (Gatabaki-Kamau & Karirah-Gitau 2004; Pamoja Trust 2009). After independence in 1963, Nairobi experienced a housing crisis leading to the massive growth of high-density deprived areas. The housing privatization legislation worsened the situation. Presently, approximately 86% of Nairobi’s housing stock is supplied by the private sector, including slumlords (KNBS 2018). It is estimated that around 60% of the inhabitants of Nairobi live in deprived settlements that occupy 4% of the built-up area (Pamoja Trust 2009).

Case study area – Nairobi (Sources: GADM & Spatial collective)
The hazards affecting our AOI at the city- and deprived settlement levels were identified through interviews of experts. The questions were prepared beforehand based on the literature review. They covered four main topic areas: (i) deprived settlement types, (ii) hazards, (iii) durable housing, and (iv) ethical concerns/considerations (Table 1). The experts were selected based on their experience working in deprived settlements or analysing urban poverty in different types of organizations and professions (Table 2).
Deprived urban areas in Nairobi are not homogenous. Building on research carried out in the related SLUMAP project (Vanhuysse et al. 2021) and using the insights gained from the expert interviews (Table 2), we used in total four different types of residential areas (Fig. 5 and Table 9 for details):
-
Class 1: High- to mid-density built areas—formal central housing areas
-
Class 2: Low-density built areas—commonly single-family housing mainly at the periphery
-
Class 3: Deprived urban areas (Type I)—typical slums, very densely built-up areas commonly at more central locations
-
Class 4: Deprived urban areas (Type II)—atypical slums, high- to mid-density built-up areas commonly at the periphery

Four types of residential areas in Nairobi as used in this study
2.2 Data and software
We obtain cloud-free Sentinel 2 surface reflectance multispectral imagery from European Space Agency (ESA). The imagery is downloaded using Google Earth Engine (GEE) for 2019, where the annual mean values are computed, and cloud masking is also undertaken. A similar approach is undertaken to acquire Land Surface Temperature from MODIS and air pollution data from Sentinel 5P, where the annual maximum values are computed. The digital elevation model (DEM), a Synthetic Aperture Radar (SAR) Radiometric Terrain Corrected (RTC), imagery is obtained from the National Aeronautics and Space Administration (NASA) Earth Data portal. Nairobi’s land use map and building outlines were generated by Columbia University's Center for Sustainable Urban Development in 2010 and obtained through the World Bank data portal. The slum boundaries were obtained from a local company – Spatial Collective, and represent morphological slums. Morphological slums are areas that are relatively homogeneous from the point of view of morphological characteristics (e.g., buildings sizes, built-up patterns and densities) (Wurm & Taubenböck 2018) reflecting the physical dimension of deprivation. Ancillary data was obtained from Open Street Map (OSM). ESRI satellite imagery, accessed through QGIS, is used as a base map and conceptualizes settlements. Free and open-source software for geoinformatics (FOSS4G) solutions are employed in our study. Specifically, QGIS is used for raster and vector data manipulation, KoBo Toolbox for primary data collection (household questionnaires), and R studio for advanced statistical manipulation, i.e., texture extraction and machine learning (Table 8). We, however, also use commercial software: ArcGIS 10.8.1-Topography Toolbox for extracting the Height Above Nearest Drainage (HAND); ZOOM – a video teleconferencing platform for conducting key informant interviews; MS-Excel and SPSS for statistical analysis of our data. MS Excel is also used to present the outcomes of the statistical analysis.
2.3 Construction of a multi-hazard susceptibility index
Figure 6 illustrates the workflow leading to the construction of the multi-hazard susceptibility index (Table 3).

Construction of the multi-hazard susceptibility index (workflow (for Index ref see Table 3)
The first step consists in defining the hazard domain using the Emergency Events Database (EM-DAT 2009) classification of disasters, in relation with UN-Habitats' measures of durable housing, where we identify two broad hazard domains, i.e., natural and technological hazards (Table 4). Furthermore, we review the country's National Policy for Disaster Management (Government of Kenya, 2009), the "Tomorrow's Cities: Urban risk in transition" project under current implementation in Nairobi, the IDEAMAPs framework of Domains of Deprivation (Abascal et al. 2022) and conduct expert interviews (Table 2) to identify hazards affecting our study area at the city and deprived settlement. To select the relevant hazard types and construct a multi-hazard susceptibility index, we use (besides the outcome of the expert interviews) the spatial multi-risk index construction principles outlined by (Greiving et al. 2006), which are: (i) non-sectoral, meaning the consideration of hazards should incorporate different sectors (i.e., disciplines: e.g., flooding, industrial hazards, earthquakes); (ii) the hazards should have spatial relevancy (i.e., are relevant for the location); and (iii) collective hazards (i.e., that impact the community not only one individual) are what should be considered.
To construct the index, we identify open geospatial data indicative of hazardousness following an extensive literature search and outcomes of the expert interviews. The identified geospatial and EO-based variables result in 6 major hazard groups disaggregated into 10 sub-hazards (indicator groups) and 18 sub-hazard indicators (Table 3). However, the selection was limited by data availability. We used data that are commonly available in African cities, to support the transferability of the proposed method.”
The spatial data identified to represent the indicators are pre-processed. We project the data to Nairobi's Coordinate Reference System (EPSG:32737), mask and clip them to our AOI, resample them to 10 m (the same resolution as Sentinel-2 data) and normalize them (resulting in values ranging from 0 to 1—lowest to highest indication of hazardousness Normalization of data are essential since it minimizes complexity and allows us to compare the indicators. Data normalization cost and benefit functions are used for the study and operationalized using the raster calculator tool in QGIS. Thus, LST, air pollution, and building and industries densities data are normalized using the benefit function since higher values indicate a higher likelihood of hazardousness. The road network density, NDVI, proximity data, and HAND are normalized using the cost function since lower values indicate a higher likelihood of hazardousness. Due to the lack of data on the frequency of hazard occurrence, we consider that all six hazards have the same importance and thus assign them equal weights. The hazard weights are then distributed proportionally among the sub-hazards (Table 3). Finally, we compute the multi-hazard susceptibility index through a weighted sum of layers corresponding to the sub-hazards.
2.4 Predicting deprivation via the multi-hazard susceptibility index
To test the ability of multi-hazards to predict the location of deprivation, we compare an image-based classification approach that includes textural features (texture-based data set) to a classification approach that uses multi-hazards (multi-hazard dataset). In previous studies (using Sentinel images (e.g., Kuffer et al. 2021; Wurm et al. 2019)), the combination of the spectral and texture features has shown their capability to distinguish between deprived and non-deprived built-up areas. Adding hazard features, we analyze whether the hazard allows improving the classification of deprived areas.
For the first land-cover/user classification, besides the image bands (using 10 m resolution Sentinel-2 red, green, blue, and near-infrared (NIR) bands eight), we use eight common textural measures based on grey-level co-occurrence matrix (Haralick et al. 1973; Kuffer et al. 2016). These textural features are: contrast, entropy, mean, dissimilarity, homogeneity, angular second moment (ASM), correlation, and variance. Texture features were added as they showed in previous studies as an important contribution to improving the classification accuracy (Engstrom et al. 2017; Kuffer et al. 2016; Wang et al. 2019a; Wurm et al. 2017). These are generated in R Studio using the GLCM package. We set the user-defined parameters of window size (kernel) and shift. Kernels apply a function to the central pixel based on the neighboring pixels. They, therefore, not only deal with noise in data but also influence the performance of models. Thus, selecting the ones that best fit the data characteristics is essential. Using a scaling factor of two, we use varying kernel sizes ranging from 5X5 to 27X27 for each of the four bands and apply a shift factor of 1. As a result, we derive 416 textural bands collectively described as high-dimensional data (or big data). To reduce dimensionality and identify the best kernel size for classification, we use the variable selection using RF (VSURF) algorithm, implemented in R Studio (Genuer et al. 2015).
For the second land-cover/use classification, the hazard index is added as an image feature. For both classifications, random forest (RF) is used. Parameter optimization (ntree and mtry) are determined using iterative tuning operations. The first parameter that we tune is ntree, which indicates the number of trees used to build the model. For both land cover and land use classification, the optimal value is determined by starting the value at 0–5000 and varying the intervals by 500 until the learning curves of each predictor class (including OOB samples) stabilizes. While optimizing ntrees, the mtry values are kept at default, i.e., mtry = √number of variables. Mtry represents the number of nodes to be split in each tree. After finding stable values for ntrees, mtry is optimized by varying the value starting with the number of predictor variables.
To perform land-cover classification, we identify four classes of land cover in the study area, i.e., built-up, bare land, vegetation and water. Within each category, we further identify subclasses to capture the diverse nature of our study area. The built-up subclasses are mentioned in previous sections (high-mid density, low-density, deprived type I, deprived type II, including non-residential buildings). For these subclasses we use labeled samples generated in previous research (Vanhuysse et al. 2021) (Fig. 7). We use OSM data to automatically generate labeled samples for classes of bare land, unpaved roads, and vegetation cover through random sampling. Next, we perform a visual assessment of the samples, and for the class "vegetation" we supplement them with manually labeled samples to encompass the diversity of this class. In total, we generate 1219 labeled samples. These samples are randomly split into 70% for training and 30% for cross-validation and we rely on the out-of-bag (OOB) error to evaluate the model's classification performance.

Reference data used for training and validation of the built-up subclasses
2.5 Quantitative and qualitative validation of results
For the quantitative validation, first, we perform canonical discriminant analysis (CDA), to determine the relationship between the predictor variable (i.e., multi-hazard index) and grouping variables (i.e., four types of residential settlements (Sect. 2.1)). For the predictor variable, there are underlying linear dimensions called variates that are used to determine discriminant functions. These linear variates are described using a linear regression model function (Eq. 1) (Field 2018).
Linear regression equation, where: x1 = outcome variable 1 and b = weights indicative of each variable’s contribution to the variates.
The b values are calculated from the eigenvectors, i.e., the ratio of systematic variance to unsystematic variance (SS M / SS R) for the underlying variates (Field 2018). From eigenvectors, eigenvalues are extracted that measure the degree of freedom of the model. The larger the eigenvalue, the higher the variance between the linearly combined variables. The function (e.g., yi) represents the ratio of variability within the outcome variables as explained by the model (SS M) and error in prediction (SS R) to maximize group differences using a linear combination of outcome variables. Lastly, the number of discriminant functions is determined by K-1 (where K is the number of categories/group memberships) or the number of variates which is equivalent to p (number of outcome variables) (Field 2018). Given that we have four groups, three statistically significant discriminant functions were obtained (Table 5). The first discriminant function has a maximized ratio of variability since it tests the model as a whole. As a result, the first function is the most powerful discriminating dimension.
Secondly, we compute the overall accuracy from the confusion matrix that provides the global accuracy assessment measure based on the total correctly classified pixels. Additionally, we compute the F1 score- the weighted average function of precision and recall (Brownlee 2014). Precision is calculated using the confusion matrix as a ratio of correctly predicted observations to the total predicted positive observations. On the other hand, recall is calculated as the ratio of correctly predicted positive observations to total observations by class.
For the qualitative validation of the multi-hazard susceptibility index, we conducted household surveys in two deprived settlements in Nairobi: Kibera and Kariobangi North. An equal number of samples (n = 86) are selected for each settlement class to compare the spatial distribution of hazards in Nairobi. In developing the questionnaire, we focus on the hazards identified in the multi-hazard susceptibility index. Furthermore, given that the purpose of the questionnaire is to understand the hazards experienced in deprived settlements and at the household level, we use a funnel approach for the survey design (from settlement to household level). The questions are closed ended with an allowance for additional commentary by the respondents. A local community group (Community Mappers) provided research assistant services. A random sampling strategy is employed to reduce bias in the data collection. Specifically, we create grids of 100mx100m over the settlements and using the random selection tool in QGIS, 70 grid cells are selected in Kibera and 30 in Kariobangi North (Fig. 8). The questionnaire is designed and deployed using the KoBo toolbox, which was selected due to its compatibility with mobile devices, geo-location collection capabilities. It is a free and open-source application.

Study area with location of selected settlements for HH survey (top) and randomly selected grids within Kibera (bottom left) and Kariobangi North (bottom right)
3 Results
First, we provide the results of the multi-hazard susceptibility index per the 10 sub-hazards. Second, two validation approaches of the index are shown, i.e., a quantitative validation by using the hazard index for classifying the location of deprivation areas and a qualitative validation by a household survey in deprived communities.
3.1 Multi-hazard susceptibility index
Equal weight distribution was selected, from the main hazard category to indicators (Table 3). These were used to compute the multi-hazard index of our study, as presented in the following section. While typical multi-hazard assessments rely on occurrence or magnitude and frequency data for hazard analysis, the unavailability of these data resulted in the use of proxies for constructing a multi-hazard susceptibility index.
Generally, all hazards are found in Nairobi, while their geographic patterns show variations (Fig. 9). For example, Nairobi is highly susceptible to riverine and runoff flooding (Fig. 9). Two factors explain the observed high susceptibility to river inundation of the city. First, parts of the city have a relatively flat terrain. Secondly, the city has three major tributaries (Nairobi, Mathare and Ngong rivers) of the Nairobi Drainage basin system cutting through the city. Despite the seemingly high susceptibility to riverine flooding, the experts inform us that the river tributaries do not pose a significant threat to the city, in general, since the tributaries do not have a big extend and are in valley terrains. However, this is different for deprived settlements since many encroach on the riparian reserves (Fig. 4) and hardly have any protective measures to prevent flooding. On the other hand, runoff flooding appears to be a city-wide threat, including in deprived settlements, as our experts emphasize. Looking at the index, most of the city has scores > 0.6. Specifically, the central and eastern regions of the city are at high risk of runoff flooding. The terrains of these regions are characterized by foot slopes that transition into flat terrain. Furthermore, they lie downstream of the Nairobi drainage system, where the typical slums are mainly located.

Spatial distribution of hazards in Nairobi per sub-hazard category of the multi-hazard susceptibility index
In terms of epidemics, the index is based on the proximity of settlements to the city's sole landfill, located in the northeastern region. As a result, the hazard susceptibility is higher near the landfill. Extreme temperatures also have a distinct pattern, increasing from west to east (Fig. 9). Climatic factors can explain the sharp contrast between the west and east parts of the city. The western regions are closer to the highland areas (Kiambu County), while the eastern and southern regions are toward the semiarid climatic zones (Machakos and Kajiado counties). As a result of using proximity measures to transport infrastructures, most of the city has hazard scores > 0.8 (Fig. 9). Due to the high connectivity of the road and rail infrastructure, most of the city except the far eastern region is hazardous (Fig. 9). Furthermore, Nairobi is served by three airports located in the city's central areas. The index reflects this pattern, and the urban core and southern regions are thus most susceptible to air transport-related accidents. Also, industries are spread throughout the city. As a result, the index captures this pattern (Fig. 9). Therefore, we find the risk of industrial hazards is not as high compared to the other assessed hazards. Most of the city has hazard scores of 0.6 and below. However, within the city’s core, there is a hotspot area that coincides with the zoned industrial area of Nairobi. Similarly, the fire hazard index highlights distinct hotspots in the city (Fig. 9). Interestingly, the hotspot patterns distinctively outline some commonly known deprived settlements such as Kibera, classified as class 3—typical slum settlements in this study (see Fig. 8). The distinct pattern for the fire hazard index can be attributed to the district characteristics of deprived settlements, i.e., densely built, lacking adequate road infrastructure and green spaces (all features used to describe the susceptibility to fire hazards). The index further reveals that the central-western region is the most affected by air pollution, spreading to the western, northern and southern areas (Fig. 9). The possible reason for this is that by looking at the annual wind directions, the most predominant winds blow from the northeast direction and hardly any from the west (Windfinder 2021).
Lastly, to compute the multi-hazard index, we sum the weighted indicators. As a result, we find that the urban core of Nairobi is the most hazardous while the western region is the least hazardous (Fig. 10). The river tributaries are also highlighted. Their hazardousness coincides with the overall distribution of hazards in the city. Typical slums are in the most hazardous locations, followed by high-mid density settlements, atypical slums and low-density settlements, respectively (Fig. 10). This confirms that typical deprived areas (Type 1: most deprived areas) are most susceptible to multi-hazard. Besides, high density areas (e.g., low-cost housing areas) also have a high susceptibility to multi-hazard. This shows similar results as in multiple deprivation studies (Baud et al. 2008; Patel et al. 2015; Wurm & Taubenböck 2018) where low-cost (high-density built-up areas) often have high deprivation values.

Left: Multi-hazard susceptibility index in Nairobi, from the weighted sum of hazard indicators (natural breaks classification). Right: Index value range in each residential subclass
3.2 Statistical evaluation using canonical discriminant analysis
By first running MANOVA, we find that our model, is statistically significant. We establish this by evaluating all four multivariate test statistics (Pillai’s Trace, Wilk’s Lambda, Hotelling’s Trace and Roy’s Largest Root) that obtain p < 0.0001, indicating that the classes differ significantly (Table 6). Additionally, a Wilk’s Lambda of V = 0.062 indicates a high ability of class separation within our data.
Next, the discriminant functions were obtained. Given that we have four groups, three statistically significant discriminant functions were obtained (Table 5). The first discriminant function, that tests the model as a whole, explained 69.2% of the variance, with canonical R2 = 0.79; the second function explained only 17.6%, with canonical R2 = 0.49, and the third 13.2% with canonical R2 = 0.42.
Lastly, the functions at group centroids were obtained (Table 7). These show the functions used for discriminating the classes. The group centroids represent the group/class mean function scores (Field 2018). The first function significantly differentiated low-density areas (mean = − 3.29); the second function differentiated type II deprived areas (mean = − 1.515); and the third differentiated high- to mid-density built areas (mean = 1.473).
Also, by observing the differences in mean values for the classes, we understand the relationship among the classes. We find that deprived areas—type I have positive high mean scores in both the first and second functions (Table 7). Thus, highlighting the high contrast between deprivation type I and the other classes, i.e., low-density built-up areas and deprived areas type I (Table 7). Additionally, these observations can be seen from the plotted distribution of the class samples (including the group centroids) against the functions (Fig. 11). The X- axis (first discriminant function) of the plotted feature space demonstrates that deprived settlements are dominantly located in hazardous locations. Lastly, we find that the CDA model yields an overall prediction classification accuracy of 79.7%.

Plotted samples and respective group centroids against the first and second canonical discriminant functions
3.3 Predicting deprivation via the multi-hazard susceptibility index
Using the VSURF algorithm to select the best features for predicting deprivation, we narrow down the feature set to 35 features out of 420 from the texture-based dataset and seven features out of 22 from the multi-hazard dataset. The selected multi-hazard features include industry proximity, building density, river proximity, road density, rail proximity, dumpsite proximity, and nighttime LST. Both classifications (from multi-hazard dataset and from texture-based dataset) obtain an overall accuracy of above 70% at 95% confidence. The multi-hazard dataset, however, performs slightly better by 2% OA. These results are obtained with random forest classifier parameters optimized at ntree = 2500 and mtry = 6 for the texture dataset and; ntree = 3000 and mtry = 2 for the multi-hazard dataset.
From the multi-hazard dataset, the recall values of the deprived type I and II settlements are the highest (0.84 and 0.87, respectively), following those of non-residential areas (Fig. 12). The precision value of typical slums is also high (0.85), resulting in a high F1 score of 84%. Despite obtaining low recall values for deprived type II (0.68), the multi-hazard model performs well at classifying deprived settlements, getting an F1 score of 76%. In comparison, the textures model performs slightly poorly at classifying typical slums by obtaining an F1 score of 78% compared to the multi-hazards model. However, when comparing the settlement classes, typical slums are the best classified, followed by high-mid density settlements (F1 score of 71%).

A comparison of precision, recall and F1 score per class for multi-hazard susceptibility and texture-based datasets
We further note that the models confuse low-density settlements, non-built areas, high-mid density settlements and deprived type II settlements. Based on the multi-hazard model, the low recall values (0.58) of low-density settlements followed by non-built (0.63) and high-mid density (0.64) reflect this (Fig. 12). We find this to occur because low-density settlements and non-built areas are located on the city's periphery. Also, the data we use have a resolution of 10 m. Thus, some houses in low-density neighborhoods may go undetected. Additionally, the nature of high-mid density settlements varies within Nairobi, with some regions having similar characteristics to those of low-density settlements (Fig. 5). Looking at the texture-based dataset, the high-mid density settlements have the lowest recall (0.66), followed by the non-built class (0.67) and deprived type II (0.69).
Both models perform well at classifying typical slums. The main difference observed is that the multi-hazard dataset better classifies deprived areas than the texture-based dataset. Also, despite having a high OA, we see from the visual interpretation of the classification that the multi-hazards dataset generalizes entire regions while the textures-based model is noisier (Fig. 13). Thus, the use of hazard-based data highlights the location of deprived areas but provides a generalized map due to the coarse resolution of several inputs.

Land-cover/use maps generated from the multi-hazard dataset (top) and texture-based dataset (bottom)
3.4 Qualitative evaluation of multiple hazards in settlements
Our survey was divided into two sections. The first targeted responses of the hazards affecting the respective settlement, and the second focused on the household’s individual experiences. The questionnaire captured all identified hazards as per the index, except for air transport-related hazards. Also, there was no differentiation between riverine and runoff flooding (often occurring combined). Furthermore, some of the hazards were disaggregated, according to their plausible causes, e.g., extreme temperatures split to capture the extremities (heat and cold). Lastly, we also included building collapse as a hazard captured by the durable housing domain.
3.4.1 Settlement level
The highest reported hazard in both settlements was garbage accumulation, at 26% in Kariobangi North and 19% in Kibera at the settlement level (Figs. 14 and 15). For many years, Nairobi has relied on the Dandora landfill, which was declared full 25 years ago (UNEP 2018). Thus, these findings can be attributed to the city's lack of adequate garbage disposal services leading to garbage accumulation within settlements.

Garbage accumulation in the Nairobi River in Kibera, 2019

Reported hazards at the settlement level
In Kariobangi North, disease outbreaks (22%) are the second most reported hazard, followed by air pollution (12%) and fire (11%) (Fig. 15). The three leading causes of disease outbreaks are attributed to inadequate water drainage systems (23%), poor environmental conditions (20%) and burst sewerage pipes (20%). Further, air pollution in Kariobangi North is reportedly caused by burning garbage (44%) and industries (35%), while fire is mainly caused by poor electricity connections (53%) and industrial accidents (24%).
In Kibera, air pollution (14%) and fire (14%) are the second highest reported hazards, followed by floods (10%) and disease outbreaks (10%) (Fig. 15). Like Kariobangi North, burning garbage is the highest cause of air pollution, and poor power connections (60%) are the leading cause of fires in Kibera. The reported causes of flooding are blocked drainage channels (33%), insufficient drainage channels (33%), and proximity to river channels (31%). Disease outbreaks, on the other hand, are linked to several factors, including the reliance on unprotected toilets (19%), bursting of sewerage pipes (18%), poor water drainage systems and poor sanitation and hygiene by households (17%).
3.4.2 Household level
At the household level, garbage accumulation was also the highest reported hazard in both Kibera (32%) and Kariobangi North (35%) (Fig. 16). In Kariobangi North, this is followed by disease outbreaks (26%), fire (12%), and industrial pollution (12%), following a similar trend to reported hazards at the settlement level. In Kibera, extreme cold (21%) is the second highest hazard, followed by fire (11%) and extreme heat (10%) (Fig. 16). Building collapse is reported only in Kibera and at a low percentage (7%).

Reported hazards at the household level
Furthermore, since the durable domain of housing highlights that the quality of structure influences a household’s protection against climatic effects, including extreme temperatures, we investigated the relationship between extreme temperatures and the quality of building materials. We found that the common building materials in deprived settlements, as ranked by experts from most to least durable, are: quarry stone, brick, mud-with concrete plastering, mud, corrugated iron sheets, tin, polythene and cardboard. Also, the rent of dwellings differs based on the materials used. The more durable the building materials, the higher the cost of housing rent (Fig. 17).

Comparison between building materials per rent class (100-kes- Kenyan Shillings were $8.43 on 26/07/2022)
To understand the interaction between the hazards and building quality at the household level, we asked the respondents the reason why they were affected by reported hazards based on four household dwelling characteristics: roofing, walls, floor, and geographic location. For the hazards reported at the household level but not at the settlement level (extreme heat, extreme cold and building collapse), we found the type of flooring (34%) as the highest cause of extreme cold, closely followed by the type of walls (30%). Upon investigating the type of floor and wall material of by reporting household, we find that 53% have concrete plastering as their type of floor material and 53% have iron sheets for walls. Also, all households reporting extreme heat had iron sheets for walls. On the other hand, the majority (50%) of households reporting building collapse had mud walls (without modifications), followed by mud walls with concrete plastering (38%).
We, therefore, found that no household with the more durable housing materials (quarry stone, bricks, mud) was affected by extreme temperatures. On the other hand, those affected by extreme temperatures mainly had corrugated iron sheets for either roofing or walls that typically have poor insulating properties. Further, referencing the monthly rent, we see that the poorer households are most affected by extreme temperatures. These findings further support claims made in the literature that the quality of the housing structures in deprived areas is often precarious and offers insufficient protection from climate and weather elements (UN-Habitat 2016).
3.4.3 Comparison of multi-hazard susceptibility index scores between 2 settlements
We further explored the degree of hazardousness of the two deprived settlements surveyed in this study, as captured by the multi-hazard susceptibility index (Fig. 18). The highest hazards threats are transport accidents and riverine flooding, similar to the city level. However, both settlements have hazard scores of 0.8, higher than the city's average (Fig. 9). On the contrary, the qualitative analysis did not highly report these hazards. Only 9% of the respondents reported road accidents in both settlements at the settlement level. Additionally, rail accidents (4%) were only reported in Kibera. At the household level, there were only 2% and 4% reporting on road accidents in Kibera and Kariobangi North, respectively, and none for rail accidents. These findings highlight the limitations of the index to localize the hazards. Furthermore, in contrast to our initial findings, the atypical slum—Kariobangi North had a higher overall degree of hazardousness than the typical slum – Kibera (Fig. 18).

Comparison of settlements' multi-hazard susceptibility index scores
Nevertheless, we note that (in exemption of the hazards that are high at the city level) the other highly scoring hazards in the two settlements were also highly reported at the settlement and household levels. Of the hazards identified by the index with scores > 0.8 in Kariobangi North, the epidemics have higher values than Kibera and are above the city’s average (Fig. 15). When contrasting these findings to the settlement and household level assessments, we find that in Kariobangi North, garbage accumulation is the most reported hazard at settlement and household levels, followed by disease outbreaks (Figs. 15 and 16). Both hazards are indicative of susceptibility to epidemics. Furthermore, while the index outcome is due to the settlement’s proximity to the city’s landfill, the challenges are more localized at the settlement level. The causes are linked to the high accumulation of garbage and infrastructure failures. In Kibera, air pollution and fire are the identified hazards with index scores significantly higher than the city’s average and Kariobangi North (Fig. 15). Similarly, at the settlement and household levels, we found that following garbage accumulation, air pollution, and fire was the highest reported hazards at the settlement level and extreme cold, followed by fire at the household level (Figs. 15 and 16).
4 Discussion
The settlements' spatial distribution suggests that typical slums are the most vulnerable to the identified hazards in this study. Below we discuss the outcomes of the multi-hazard susceptibility index and qualitative analysis by contrasting the settlement classes per sub-hazard category.
4.1 Validation of multi-hazard susceptibility index
In assessing the settlement's exposure to multi-hazards, we found typical slums to be the most exposed settlements in all sub-hazard categories used in this study (Fig. 19). Specifically, we see that typical slums are most susceptible to fire hazards and runoff flooding compared to the other settlements. Looking at fire hazards, we further find atypical slums as the second most exposed settlements. These findings are in agreement with expert opinions and literature that state that urban fires are frequent in deprived settlements within Nairobi. The fire outbreaks are attributed to several factors, including poor power connections and drunkenness (Ngau & Boit 2020). In addition to the causes, slum conditions intensify fire outbreak incidents due to their high density and compactness; lack of open spaces to provide safety; and combustible building materials (Ngau & Boit 2020). The poor road connectivity further hinders responses to the fires within the settlements (Ngau & Boit 2020).

Settlements exposure to hazards
On the other hand, the experts consider runoff flooding a city-wide problem. On the contrary, our study finds that in comparison with other hazards, runoff flooding is not a significant threat to the city. We find this to be due to the data used for assessing the hazard. While our study's assessment of runoff flooding was based solely on the physical factors (terrain), other factors causing runoff flooding in the city, i.e., blockage of drainage systems by garbage and lack of adequate drainage systems, were identified by the experts and re-iterated by the survey outcomes. Specifically, blocked drainage channels were reported as the leading cause of flooding in both settlements (57% in Kariobangi North and 33% in Kibera). Insufficient drainage channels (33%) was also reported in Kibera. Interestingly, we found that Kariobangi North is also affected by point source runoff due to its proximity to the city's sewerage treatment plant inlets (14%).
Second, to typical slums, high-mid density settlements were highly exposed to hazards (Fig. 19). Specifically, air transport accidents, extreme temperatures, air pollution, and epidemics hazard threats are predominant. Generally, these settlements – similar to typical slums—are located in the city's central region (Fig. 7). In contrast, low-density settlements have the lowest exposure to hazards followed by atypical slums since they are predominantly located in the city’s periphery. Due to more intensive land use and land cover changes, urban cores often experience micro-climate modifications known as Urban Heat Island (UHI), where the temperatures are higher than their surroundings (Seto & Shepherd 2009; Zhou et al. 2015). Air pollution values also tend to be higher due to more industrial activities and less vegetation cover, and lastly, it is where the city’s major infrastructures, e.g., airports, are found. In addition to this, the study reveals the interrelations among some of these hazards. For instance, the leading causes of air pollution in Kibera were: the burning of garbage (74%) and pollution emanating from transport activities (14%). The respondents also associated industrial accidents with pollution (air, water, land/soil contamination, noise). In Kariobangi North, industries were reported at 35% as the cause of air pollution in the settlement. These interrelations emphasize the need for an integrated approach to investigating and managing hazards.
Generally, the multi-hazard susceptibility index found that the most significant threats in Nairobi are road accidents, riparian flooding and rail accidents, respectively (Fig. 19). The proximity to transport modes poses a high risk of accidents that may cause injuries and fatalities. In Kenya, reported causes of road accident fatalities in a recent study are attributed to driver-related causes such as ‘running over victims’ (Muguro et al. 2020). From this, we infer that secondary causes influence the occurrence of road accidents that our index did not capture. Even though only 9% of the respondents in each settlement reported road accidents, we find that insufficient/lack of pedestrian crossings is the major cause (44%—Kibera and 43%—Kariobangi North). Proximity to transport lines (43%) was the second most reported cause reported in Kariobangi North (43%) and Kibera (42%). The third highest reported cause of transport accidents is poorly trained/untrained motorcycle riders (14%) in Kariobangi North and inadequate road networks (14%) in Kibera. Similar reasons were reported for rail accidents.
Further, in agreement with the literature (see UN-Habitat 2016), our study found that deprived areas are affected by hazards due to two main reasons: their location and the quality of the building structure. Both are factors tied to the residents' socioeconomic status and highlight a crucial trade-off between hazard exposure and access to opportunities such as wealth, industries, markets, and mobility systems for the urban poor. In both Kibera and Kariobangi North, the main reasons for living in the settlement were the closeness to opportunities and rent affordability (Fig. 20). The household survey shows that the housing rent per month in both settlements are significantly low compared to the reported median urban rental expenditures of approx.300 USD in Kenya (KNBS 2018). The cost of monthly rent was lower in the typical slum – Kibera (approx. 20–30 USD) than in the atypical slum – Kariobangi North (approx. 40–50 USD). Therefore, typical slums are most afflicted, and this is highlighted not just by their exposure to hazards but also their socioeconomic status.

Reasons for staying in a deprived settlement
In conclusion, despite the difference in reporting of hazards at the three spatial scales (city, settlement and household levels), our assessments captured many similarities. Notably, we found that the city-wide multi-hazard susceptibility index is a useful starting point for more localized hazard assessments. Additionally, our study demonstrated that geospatial data, specifically EO data and its derivatives produced at high spatial scales and capturing different environmental phenomena, can be utilized in data-poor cities. Further, despite the top-down nature of geospatial methods, our study demonstrates that bottom-up approaches, e.g., household surveys, are still required. Physical and social scientific approaches are complementary and create a necessary feedback loop to improve and refine traditional top-down scientific methods.
4.2 Predictability of deprivation using multi-hazards
Interestingly, the multi-hazards model was better at discriminating deprived settlements, whereas the textural feature-based model performed well across settlement discrimination. Specifically, our study demonstrates that open geospatial data are useful in assessing urban poverty, as our attempts at using multi-hazard datasets to map deprivation resulted in high model accuracies. Further, the experiment revealed the layered nature of deprivation that goes beyond the socioeconomic conditions of the urban poor but also stresses the hazardous environmental conditions they live in.
5 Conclusion
The main goal of our study was to test the assumption that deprived areas are dominantly the locations with higher susceptibility to multiple hazards. We find this true from the multi-hazard susceptibility index and the prediction of deprivation via multi-hazards. Furthermore, by distinguishing the settlements into classes, we establish that typical slums are the worst afflicted by hazards, highlighting intra-city socio-spatial marginalization. Additionally, rampant marginalization is unveiled by investigating the hazards at the settlement and household levels. We also discovered that intra-settlement marginalization is pegged on the socioeconomic status of the residents. In concatenating these findings, we conclude that the poorest urban populations dominantly live in the most hazardous locations.
Although we obtained meaningful results, the present study is not without limitations, to be addressed in future research. First, it was challenging to identify spatial data indicative of hazards, including coherent frequency, magnitude, or occurrence. As a result, we used hazard proxies to create a multi-hazard susceptibility index that mainly highlights exposure to hazards. Nonetheless, a susceptibility index has proven to be a helpful starting point for localized hazard assessments, especially in LMICs, where data availability may be challenging. It is also simple to implement and replicate in other cities. Secondly, as shown by the household responses, we acknowledge that more and better proxies can be identified for the hazards. Lastly, the interrelated nature of some of the hazards highlights the need for more interdisciplinary and integrated approaches to investigating and managing hazards.
References
Abascal A, Rothwell N, Shonowo A, Thomson DR, Elias P, Elsey H, Kuffer M (2022) “Domains of deprivation framework” for mapping slums, informal settlements, and other deprived areas in LMICs to improve urban planning and policy: a scoping review. Comput Environ Urb Syst 93:101770. https://doi.org/10.1016/j.compenvurbsys.2022.101770
Aryal JP, Rahut DB, Marenya P (2021) Climate risks, adaptation and vulnerability in Sub-Saharan Africa and South Asia. In: Alam GMM, Erdiaw-Kwasie MO, Nagy GJ, Leal Filho W (eds) Climate Vulnerability and Resilience in the Global South: Human Adaptations for Sustainable Futures. Springer International Publishing, Cham, pp 1–20
Baker JL (2008) Urban poverty: a global view
Baud I, Sridharan N, Pfeffer K (2008) Mapping urban poverty for local governance in an Indian mega-city: the case of Delhi. Urb Stud 45(7):1385–1412. https://doi.org/10.1177/0042098008090679
Brownlee J (2014) Classification Accuracy is not enough: more performance measures you can use. Retrieved August 12, 2021, from Machine Learning Process website: https://machinelearningmastery.com/classificationaccuracy-is-not-enough-more-performance-measures-you-can-use/
Dilley M, Chen RS, Deichmann U, Lerner-Lam AL, Arnold M (2005). Natural Disaster hotspots: a global risk analysis retrieved from Washington, DC, USA: https://openknowledge.worldbank.org/handle/10986/7376
EM-DAT. (2009). General classification from EM-DAT: the international disaster database. retrieved from https://www.emdat.be/classification
Engstrom R, Newhouse D, Haldavanekar V, Copenhaver A, Hersh J (2017). Evaluating the relationship between spatial and spectral features derived from high spatial resolution satellite data and urban poverty in Colombo, Sri Lanka. Paper presented at the 2017 Joint Urban Remote Sensing Event (JURSE).
Field A (2018) Discovering statistics using IBM SPSS statistics. Sage
Gallina V, Torresan S, Critto A, Sperotto A, Glade T, Marcomini A (2016) A review of multi-risk methodologies for natural hazards: consequences and challenges for a climate change impact assessment. J Environ Manag 168:123–132. https://doi.org/10.1016/j.jenvman.2015.11.011
Gatabaki-Kamau R, Karirah-Gitau S (2004) Actors and interests: the development of an informal settlement in Nairobi, Kenya. In: Vaa M, Hansen Tranberg K (eds) Reconsidering informality: perspectives from Urban Africa. Nordiska Afrikainstitutet, Uppsala, Sweden, pp 158–175
Genuer R, Poggi JM, Tuleau-Malot C (2015) VSURF: an R package for variable selection using random forests. R J 7(2):19–33. https://doi.org/10.32614/rj-2015-018
Greiving S, Fleischhauer M, Lückenkötter J (2006) A Methodology for an integrated risk assessment of spatially relevant hazards. J Environ Plan Manage 49(1):1–19. https://doi.org/10.1080/09640560500372800
Haralick RM, Dinstein I, Shanmugam K (1973) Textural features for image classification. IEEE Trans Syst Man Cybern SMC-3(6):610–621. https://doi.org/10.1109/TSMC.1973.4309314
IPCC. (2022). Climate Change 2022: Impacts, Adaptation, and Vulnerability. Contribution of Working Group II to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change Retrieved from Cambridge, UK:
Kamruzzaman M, Mandal T, Rahman ATMS, AbdulKhalek M, Alam GMM, Rahman MS (2021) Climate Modeling, Drought Risk Assessment and Adaptation Strategies in the Western Part of Bangladesh. In: Alam GMM, Erdiaw-Kwasie MO, Nagy GJ, LealFilho W (eds) Climate Vulnerability and Resilience in the Global South: Human Adaptations for Sustainable Futures. Springer International Publishing, Cham, pp 21–54
KNBS. (2018). Basic report on well-being in Kenya -based on the Kenya integrated household budget survey (KIHBS). Retrieved from Nairobi, Kenya:
Kohli D, Sliuzas RV, Kerle N, Stein A (2012) An ontology of slums for image-based classification. Comput Environ Urb Syst 36(2):154–163. https://doi.org/10.1016/j.compenvurbsys.2011.11.001
Kuffer M, Pfeffer K, Sliuzas R, Baud I (2016) Extraction of slum areas from VHR imagery using GLCM variance. IEEE J Sel Top App Earth Obs Remote Sens 9(5):1830–1840. https://doi.org/10.1109/JSTARS.2016.2538563
Kuffer M, Thomson DR, Boo G, Mahabir R, Grippa T, Vanhuysse S, Kabaria C (2020) The role of earth observation in an integrated deprived area mapping “System” for low-to-middle income countries. Remote Sens 12(6):982
Kuffer M, Vanhuysse S, Georganos S, Wang J (2021) Meeting user requirements for mapping and characterizing deprived urban areas in support of pro-poor policies. GI_Forum 9(1):85–93
Kuffer M, Wang J, Nagenborg M, Pfeffer K, Kohli D, Sliuzas R, Persello C (2018). The scope of earth-observation to improve the consistency of the SDG slum indicator. ISPRS Int J Geo-Inf 7(11): 428. Retrieved from http://www.mdpi.com/2220-9964/7/11/428
Lilford R, Kyobutungi C, Ndugwa R, Sartori J, Watson SI, Sliuzas R, Ezeh A (2019) Because space matters: conceptual framework to help distinguish slum from non-slum urban areas. BMJ Global Health 4(2):e001267. https://doi.org/10.1136/bmjgh-2018-001267
Merodio Gómez P, Juarez Carrillo OJ, Kuffer M, Thomson DR, Olarte Quiroz JL, Villaseñor García E, Brito PL (2021) Earth observations and statistics: unlocking sociodemographic knowledge through the power of satellite images. Sustainability 13(22):12640
Muguro JK, Sasaki M, Matsushita K, Njeri W (2020) Trend analysis and fatality causes in Kenyan roads: a review of road traffic accident data between 2015 and 2020. Cogent Eng 7(1):1797981. https://doi.org/10.1080/23311916.2020.1797981
Müller I, Taubenböck H, Kuffer M, Wurm M (2020) Misperceptions of predominant slum locations? Spatial analysis of slum locations in terms of topography based on earth observation data. Remote Sens 12(15):2474
Ngau PM, Boit SJ (2020) Community fire response in Nairobi’s informal settlements. Environ Urban 32(2):615–630. https://doi.org/10.1177/0956247820924939
Pamoja Trust. (2009). An Inventory of the Slums in Nairobi. Retrieved from Nairobi, Kenya: http://www.irinnews.org/pdf/nairobi_inventory.pdf
Patel S, Sliuzas R, Mathur N (2015) The risk of impoverishment in urban development-induced displacement and resettlement in Ahmedabad. Environ Urb 27(1):231–256. https://doi.org/10.1177/0956247815569128
Pourghasemi HR, Kariminejad N, Amiri M, Edalat M, Zarafshar M, Blaschke T, Cerda A (2020) Assessing and mapping multi-hazard risk susceptibility using a machine learning technique. Sci Rep 10(1):3203. https://doi.org/10.1038/s41598-020-60191-3
Ramin B (2009) Slums, climate change and human health in sub-Saharan Africa. Bull World Health Organ 87(12):886–886. https://doi.org/10.2471/BLT.09.073445
Revi A, Satterthwaite D, Aragón-Durand F, Corfee-Morlot J, Kiunsi R, Pelling M, Solecki W (2014). Urban areas in climate change 2014: impacts, adaptation, and vulnerability. Part A: global and sectoral aspects. contribution of working group ii to the fifth assessment report of the intergovernmental panel on climate Change. In (pp. 535–612).
Satterthwaite D, Bartlett S (2017) Editorial: the full spectrum of risk in urban centres: changing perceptions, changing priorities. Environ Urb 29(1):3–14. https://doi.org/10.1177/0956247817691921
Seto KC, Sánchez-Rodríguez R, Fragkias M (2010) The new geography of contemporary urbanization and the environment. Annu Rev Environ Resour 35(1):167–194. https://doi.org/10.1146/annurev-environ-100809-125336
Seto KC, Shepherd JM (2009) Global urban land-use trends and climate impacts. Curr Op Environ Sustain 1(1):89–95. https://doi.org/10.1016/j.cosust.2009.07.012
Thomson DR, Kuffer M, Boo G, Hati B, Grippa T, Elsey H, Kabaria C (2020) Need for an integrated deprived area “Slum” mapping system (IDEAMAPS) in low- and middle-income countries (LMICs). Soc Sci 9(5):80
Tiepolo M, Bacci M, Braccio S, Bechis S (2019) Multi-hazard risk assessment at community level integrating local and scientific knowledge in the Hodh Chargui, Mauritania. Sustainability 11(18):5063
UN-Habitat (2016). Slums Almanac 2015–16. Tracking Improvement in the Lives of Slum Dwellers. Nairobi, Kenya
UNEP (2018). Smoking Nairobi landfill jeopardizes schoolchildren’s future. Retrieved from https://www.unep.org/news-and-stories/story/smoking-nairobi-landfill-jeopardizes-schoolchildrens-future
van Westen CJ, Greiving S (2017) Multi-hazard risk assessment and decision making. In: Dalezios NR (ed) Environmental Hazards Methodologies for Risk Assessment and Management. IWA Publishing
Vanhuysse S, Georganos S, Kuffer M, Grippa T, Lennert M, Wolff E (2021). Gridded urban deprivation probability from open optical imagery and dual-pol sar data. Paper presented at the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS.
Wang J, Kuffer M, Pfeffer K (2019a) The role of spatial heterogeneity in detecting urban slums. Comput Environ Urban Syst 73:95–107. https://doi.org/10.1016/j.compenvurbsys.2018.08.007
Wang J, Kuffer M, Sliuzas R, Kohli D (2019b) The exposure of slums to high temperature: morphology-based local scale thermal patterns. Sci Total Environ 650:1805–1817. https://doi.org/10.1016/j.scitotenv.2018.09.324
Wang S, Wang J, Fang C, Feng K (2019c) Inequalities in carbon intensity in China: a multi-scalar and multi-mechanism analysis. Appl Energy 254:113720. https://doi.org/10.1016/j.apenergy.2019.113720
Wekesa BW, Steyn GS, Otieno FAO (2011) A review of physical and socio-economic characteristics and intervention approaches of informal settlements. Habitat Int 35(2):238–245. https://doi.org/10.1016/j.habitatint.2010.09.006
Windfinder. (2021). Monthly wind direction and strength distribution, from Wind & weather statistics Nairobi/Jomo Kenyatta. Retrieved from https://www.windfinder.com/windstatistics/nairobi-jomo-kenyatta-airport
Wurm M, Stark T, Zhu XX, Weigand M, Taubenböck H (2019) Semantic segmentation of slums in satellite images using transfer learning on fully convolutional neural networks. ISPRS J Photogramm Remote Sens 150:59–69. https://doi.org/10.1016/j.isprsjprs.2019.02.006
Wurm M, Taubenböck H (2018) Detecting social groups from space: assessment of remote sensing-based mapped morphological slums using income data. Remote Sens Lett 9(1):41–50. https://doi.org/10.1080/2150704X.2017.1384586
Wurm M, Taubenböck H, Weigand M, Schmitt A (2017) Slum mapping in polarimetric SAR data using spatial features. Remote Sens Environ 194:190–204. https://doi.org/10.1016/j.rse.2017.03.030
Zhao G, Maclean AL (2000) A comparison of canonical discriminant analysis and principal component analysis for spectral transformation. Photogramm Eng Remote Sens 66:841–847
Zhou D, Zhao S, Zhang L, Sun G, Liu Y (2015) The footprint of urban heat island effect in China. Sci Rep 5(1):11160. https://doi.org/10.1038/srep11160
Acknowledgements
We would like to express our gratitude to Diana Reicken, Nicholus Mboga, Angela Abascal, Stefanos Georganos and Maxwell Owusu for providing feedback during the conceptual phase of this research. Furthermore, we would like to acknowledge the valuable input of the IDEAMAPS team who provided data for the research, the team at the Department of Geography, King's College London, Strand Campus: Prof. Mark Pelling, Bruce D. Malamud, Robert Sakic Trogrlic and Sebastiaan Beschoor Plug who provided helpful input on hazard analysis, including providing relevant literature. We are also grateful to the local organizations Community Mappers and Spatial Collective for the help in collecting data and to Maria Isabel Arango, a hazard specialist for refining the hazard analysis, Brian Masinde and Alfredo Chavarria for reviewing the algorithms used in this study and to Gift Kyansimire for illustrating the residential areas of Nairobi.
Funding
The principal author received research support from the Faculty of Geo-Information Science and Earth Observation, University of Twente ITC Foundation. Additionally, research pertaining to these results received financial aid from the Belgian Federal Science Policy (BELSPO) according to the agreement of subsidy no. SR/11/380 (SLUMAP). (SLUMAP: http://slumap.ulb.be/) and from NWO grant number VI. Veni. 194.025.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by PK, and reference data were prepared by SV. The first draft of the manuscript was written by PK and MK, and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kabiru, P., Kuffer, M., Sliuzas, R. et al. The relationship between multiple hazards and deprivation using open geospatial data and machine learning. Nat Hazards 119, 907–941 (2023). https://doi.org/10.1007/s11069-023-05897-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-023-05897-z